 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Paper and Code
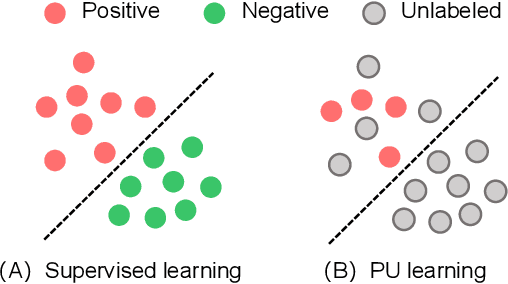
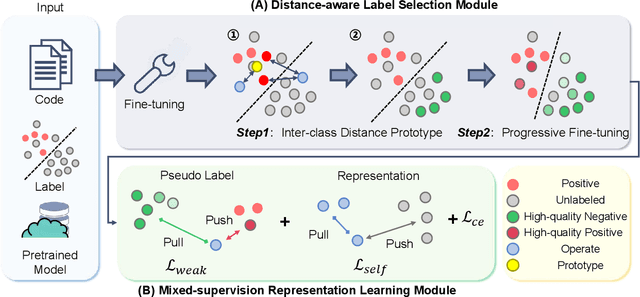

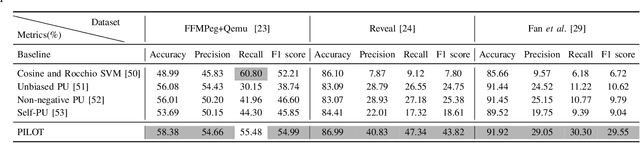
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.