 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARB4WM: An Adversarial Robustness Benchmark for World Models in Continuous Control
Jun 15, 2026World models are widely used in robotic and agentic engineering control systems due to their ability to learn latent dynamics for planning and decision-making. As these systems are increasingly deployed in safety-critical settings, understanding their robustness under adversarial conditions has become essential. However, existing evaluations lack a unified benchmark for testing adversarial threats across the policy, value, and latent-dynamics levels of world-model agents. To fill this gap, we present ARB4WM, a unified evaluation framework for pre-deployment robustness and risk assessment of world-model agents under visual perturbations. ARB4WM defines five white-box loss objectives across these three levels and studies their effects when combined with single-step or multi-step perturbation strategies and temporal attack modes, including full-frame, half-sequence, and sparse-frame exposure. Specifically, we evaluate four Dreamer-style agents across 20 tasks from MetaWorld and the DeepMind Control Suite under different loss objectives, perturbation strategies, and temporal attack modes. Results show that attacks targeting value estimation, latent representations, and RSSM dynamics can be as damaging as direct policy disruption, and that early or frequent perturbations are especially harmful, while input-level defenses provide limited recovery under adaptive attacks. These findings suggest that safety, risk, and reliability assessment for world models should cover multiple component-oriented attack objectives and temporal exposure protocols rather than relying solely on action-space robustness. Source code is available at https://github.com/zaoanguai/ARB4WM.
Debiased Dual-Invariant Defense for Adversarially Robust Person Re-Identification
Nov 13, 2025Person re-identification (ReID) is a fundamental task in many real-world applications such as pedestrian trajectory tracking. However, advanced deep learning-based ReID models are highly susceptible to adversarial attacks, where imperceptible perturbations to pedestrian images can cause entirely incorrect predictions, posing significant security threats. Although numerous adversarial defense strategies have been proposed for classification tasks, their extension to metric learning tasks such as person ReID remains relatively unexplored. Moreover, the several existing defenses for person ReID fail to address the inherent unique challenges of adversarially robust ReID. In this paper, we systematically identify the challenges of adversarial defense in person ReID into two key issues: model bias and composite generalization requirements. To address them, we propose a debiased dual-invariant defense framework composed of two main phases. In the data balancing phase, we mitigate model bias using a diffusion-model-based data resampling strategy that promotes fairness and diversity in training data. In the bi-adversarial self-meta defense phase, we introduce a novel metric adversarial training approach incorporating farthest negative extension softening to overcome the robustness degradation caused by the absence of classifier. Additionally, we introduce an adversarially-enhanced self-meta mechanism to achieve dual-generalization for both unseen identities and unseen attack types. Experiments demonstrate that our method significantly outperforms existing state-of-the-art defenses.
Fast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph
Jan 24, 2025
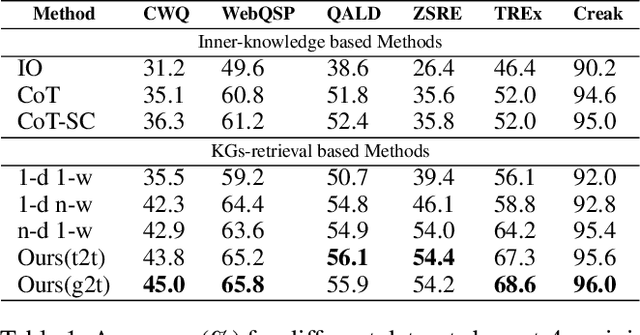

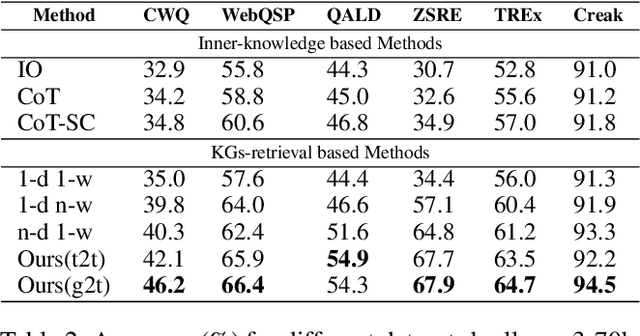
Graph Retrieval Augmented Generation (GRAG) is a novel paradigm that takes the naive RAG system a step further by integrating graph information, such as knowledge graph (KGs), into large-scale language models (LLMs) to mitigate hallucination. However, existing GRAG still encounter limitations: 1) simple paradigms usually fail with the complex problems due to the narrow and shallow correlations capture from KGs 2) methods of strong coupling with KGs tend to be high computation cost and time consuming if the graph is dense. In this paper, we propose the Fast Think-on-Graph (FastToG), an innovative paradigm for enabling LLMs to think ``community by community" within KGs. To do this, FastToG employs community detection for deeper correlation capture and two stages community pruning - coarse and fine pruning for faster retrieval. Furthermore, we also develop two Community-to-Text methods to convert the graph structure of communities into textual form for better understanding by LLMs. Experimental results demonstrate the effectiveness of FastToG, showcasing higher accuracy, faster reasoning, and better explainability compared to the previous works.
F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Oct 23, 2023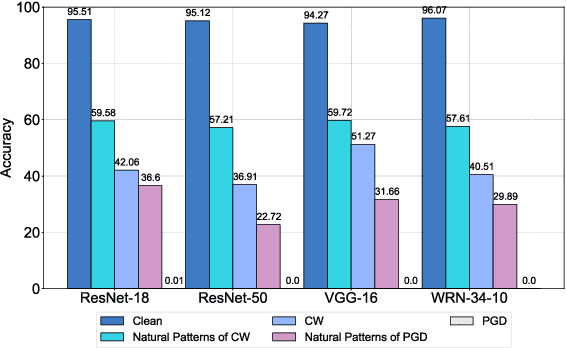

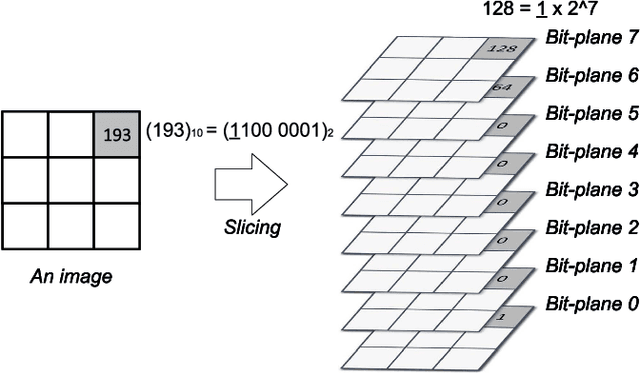
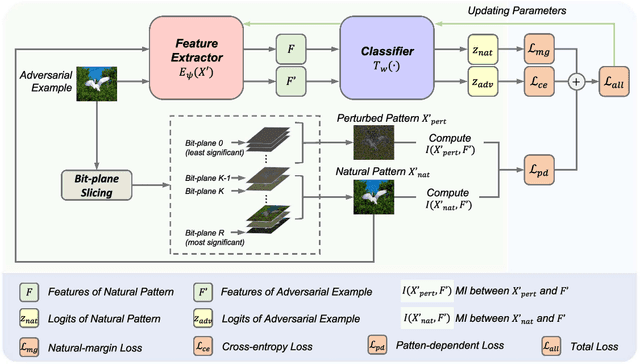
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023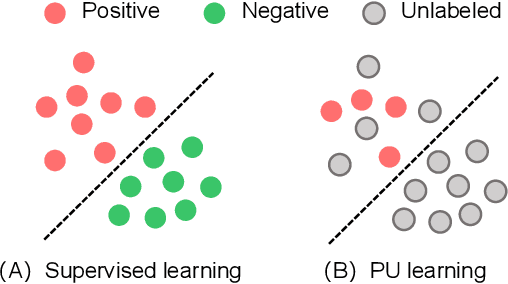
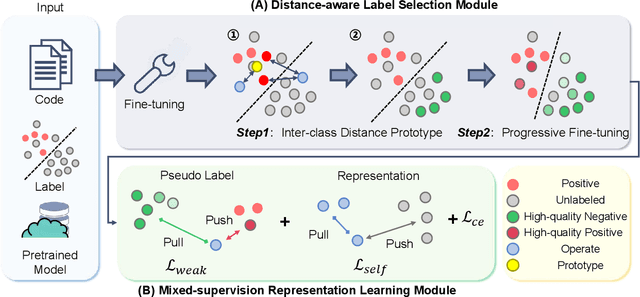

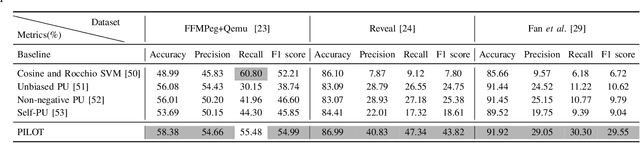
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022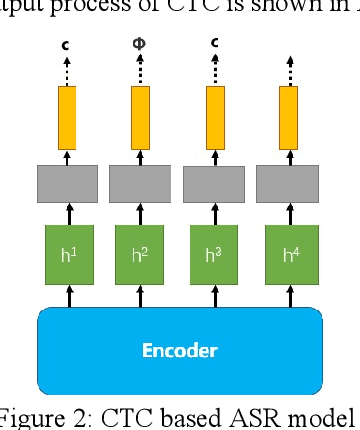
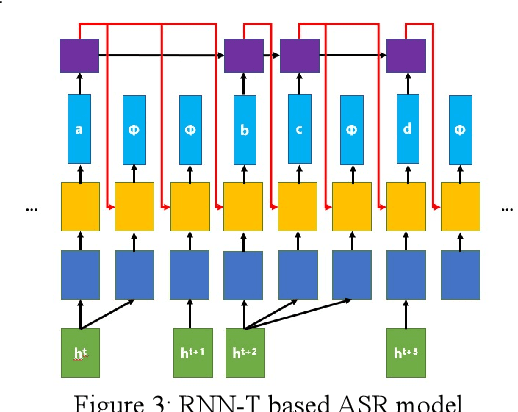
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.
Hessian-Free Second-Order Adversarial Examples for Adversarial Learning
Jul 04, 2022
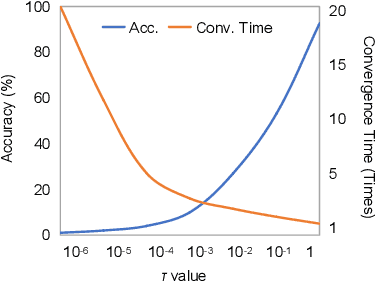
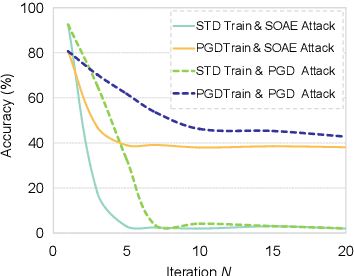
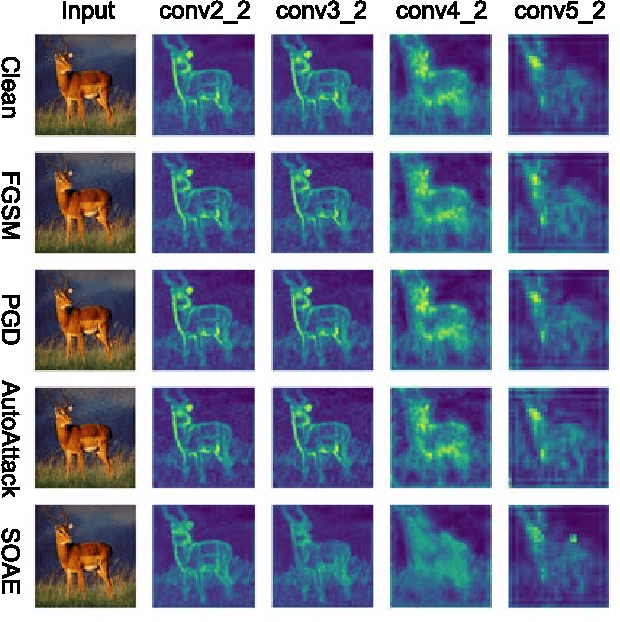
Recent studies show deep neural networks (DNNs) are extremely vulnerable to the elaborately designed adversarial examples. Adversarial learning with those adversarial examples has been proved as one of the most effective methods to defend against such an attack. At present, most existing adversarial examples generation methods are based on first-order gradients, which can hardly further improve models' robustness, especially when facing second-order adversarial attacks. Compared with first-order gradients, second-order gradients provide a more accurate approximation of the loss landscape with respect to natural examples. Inspired by this, our work crafts second-order adversarial examples and uses them to train DNNs. Nevertheless, second-order optimization involves time-consuming calculation for Hessian-inverse. We propose an approximation method through transforming the problem into an optimization in the Krylov subspace, which remarkably reduce the computational complexity to speed up the training procedure. Extensive experiments conducted on the MINIST and CIFAR-10 datasets show that our adversarial learning with second-order adversarial examples outperforms other fisrt-order methods, which can improve the model robustness against a wide range of attacks.
Improving robustness of language models from a geometry-aware perspective
Apr 28, 2022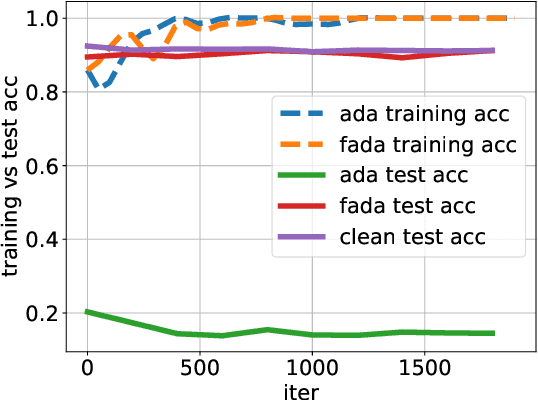


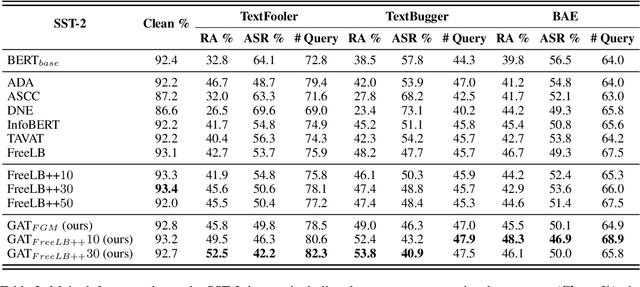
Recent studies have found that removing the norm-bounded projection and increasing search steps in adversarial training can significantly improve robustness. However, we observe that a too large number of search steps can hurt accuracy. We aim to obtain strong robustness efficiently using fewer steps. Through a toy experiment, we find that perturbing the clean data to the decision boundary but not crossing it does not degrade the test accuracy. Inspired by this, we propose friendly adversarial data augmentation (FADA) to generate friendly adversarial data. On top of FADA, we propose geometry-aware adversarial training (GAT) to perform adversarial training on friendly adversarial data so that we can save a large number of search steps. Comprehensive experiments across two widely used datasets and three pre-trained language models demonstrate that GAT can obtain stronger robustness via fewer steps. In addition, we provide extensive empirical results and in-depth analyses on robustness to facilitate future studies.
One model Packs Thousands of Items with Recurrent Conditional Query Learning
Nov 12, 2021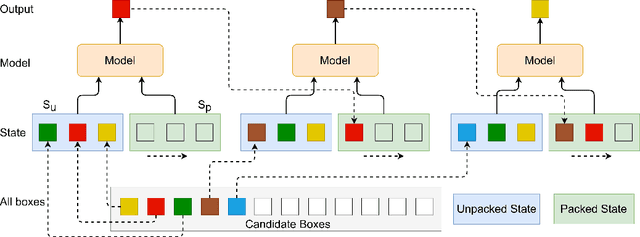
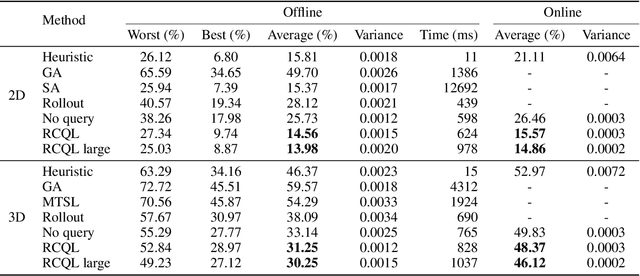
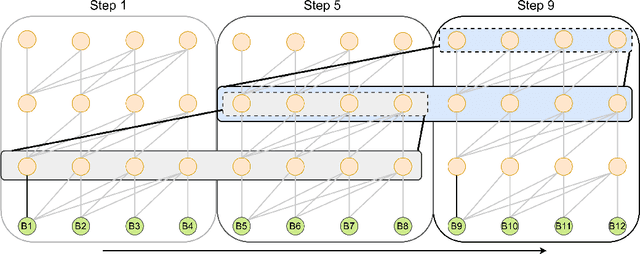
Recent studies have revealed that neural combinatorial optimization (NCO) has advantages over conventional algorithms in many combinatorial optimization problems such as routing, but it is less efficient for more complicated optimization tasks such as packing which involves mutually conditioned action spaces. In this paper, we propose a Recurrent Conditional Query Learning (RCQL) method to solve both 2D and 3D packing problems. We first embed states by a recurrent encoder, and then adopt attention with conditional queries from previous actions. The conditional query mechanism fills the information gap between learning steps, which shapes the problem as a Markov decision process. Benefiting from the recurrence, a single RCQL model is capable of handling different sizes of packing problems. Experiment results show that RCQL can effectively learn strong heuristics for offline and online strip packing problems (SPPs), outperforming a wide range of baselines in space utilization ratio. RCQL reduces the average bin gap ratio by 1.83% in offline 2D 40-box cases and 7.84% in 3D cases compared with state-of-the-art methods. Meanwhile, our method also achieves 5.64% higher space utilization ratio for SPPs with 1000 items than the state of the art.
* 16 pages, 5 figures, 3 tables. Accepted to Knowledge-Based Systems, 2022
TREATED:Towards Universal Defense against Textual Adversarial Attacks
Sep 13, 2021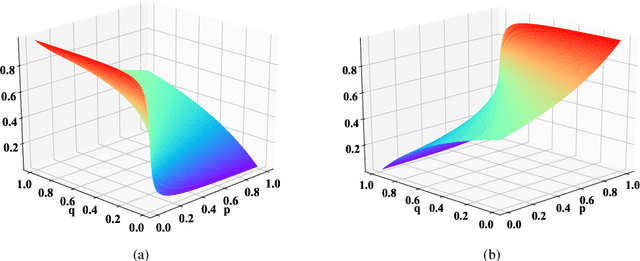
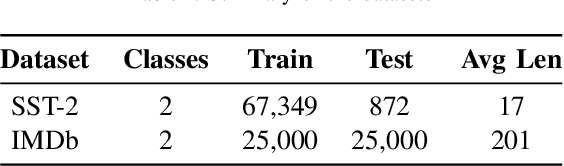
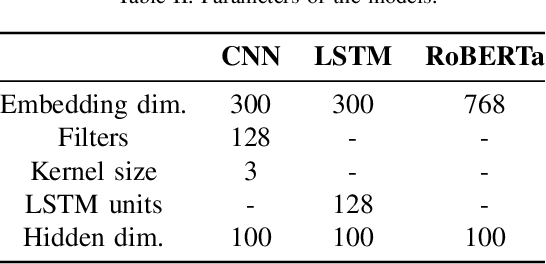
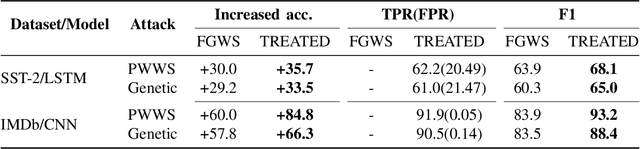
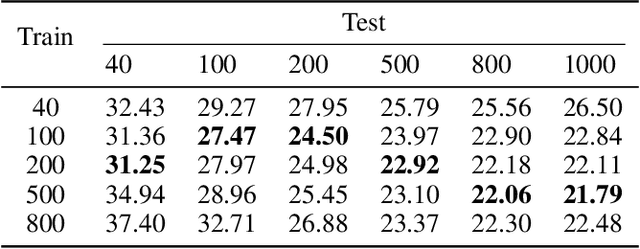
Recent work shows that deep neural networks are vulnerable to adversarial examples. Much work studies adversarial example generation, while very little work focuses on more critical adversarial defense. Existing adversarial detection methods usually make assumptions about the adversarial example and attack method (e.g., the word frequency of the adversarial example, the perturbation level of the attack method). However, this limits the applicability of the detection method. To this end, we propose TREATED, a universal adversarial detection method that can defend against attacks of various perturbation levels without making any assumptions. TREATED identifies adversarial examples through a set of well-designed reference models. Extensive experiments on three competitive neural networks and two widely used datasets show that our method achieves better detection performance than baselines. We finally conduct ablation studies to verify the effectiveness of our method.