 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Paper and Code
Oct 23, 2023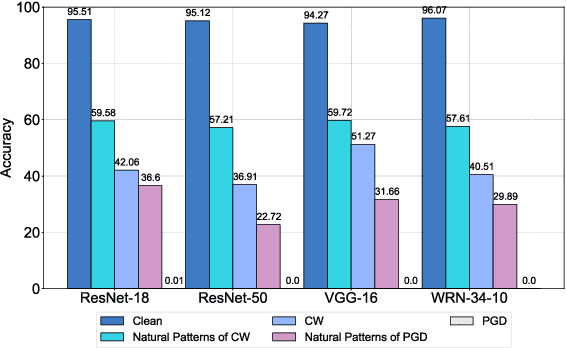

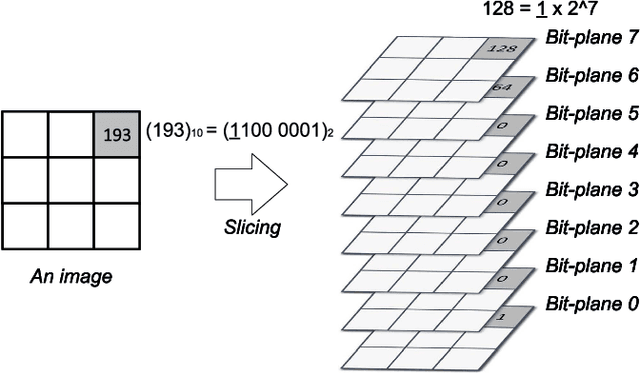
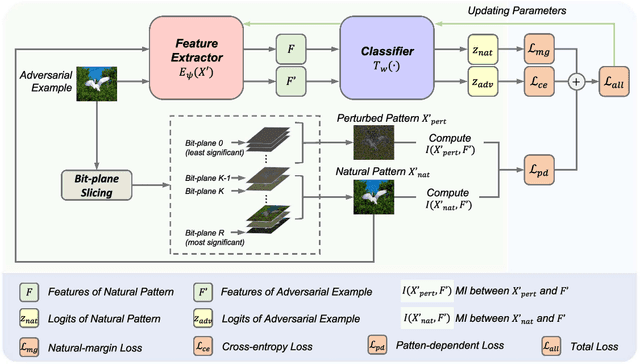
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.