 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeScale: Distributed Training for Sequence Recommendation Models with Minimal Scaling Cost
Apr 27, 2026Modern industrial Deep Learning Recommendation Models typically extract user preferences through the analysis of sequential interaction histories, subsequently generating predictions based on these derived interests. The inherent heterogeneity in data characteristics frequently result in substantial under-utilization of computational resources during large-scale training, primarily due to computational bubbles caused by severe stragglers and slow blocking communications. This paper introduces FreeScale, a solution designed to (1) mitigate the straggler problem through meticulously load balanced input samples (2) minimize the blocking communication by overlapping prioritized embedding communications with computations (3) resolve the GPU resource competition during computation and communication overlapping by communicating through SM-Free techniques. Empirical evaluation demonstrates that FreeScale achieves up to 90.3% reduction in computational bubbles when applied to real-world workloads running on 256 H100 GPUs.
LLM-driven Knowledge Enhancement for Multimodal Cancer Survival Prediction
Dec 16, 2025Current multimodal survival prediction methods typically rely on pathology images (WSIs) and genomic data, both of which are high-dimensional and redundant, making it difficult to extract discriminative features from them and align different modalities. Moreover, using a simple survival follow-up label is insufficient to supervise such a complex task. To address these challenges, we propose KEMM, an LLM-driven Knowledge-Enhanced Multimodal Model for cancer survival prediction, which integrates expert reports and prognostic background knowledge. 1) Expert reports, provided by pathologists on a case-by-case basis and refined by large language model (LLM), offer succinct and clinically focused diagnostic statements. This information may typically suggest different survival outcomes. 2) Prognostic background knowledge (PBK), generated concisely by LLM, provides valuable prognostic background knowledge on different cancer types, which also enhances survival prediction. To leverage these knowledge, we introduce the knowledge-enhanced cross-modal (KECM) attention module. KECM can effectively guide the network to focus on discriminative and survival-relevant features from highly redundant modalities. Extensive experiments on five datasets demonstrate that KEMM achieves state-of-the-art performance. The code will be released upon acceptance.
Words to Describe What I'm Feeling: Exploring the Potential of AI Agents for High Subjectivity Decisions in Advance Care Planning
Dec 12, 2025Serious illness can deprive patients of the capacity to speak for themselves. As populations age and caregiver networks shrink, the need for reliable support in Advance Care Planning (ACP) grows. To probe this fraught design space of using proxy agents for high-risk, high-subjectivity decisions, we built an experience prototype (\acpagent{}) and asked 15 participants in 4 workshops to train it to be their personal proxy in ACP decisions. We analysed their coping strategies and feature requests and mapped the results onto axes of agent autonomy and human control. Our findings argue for a potential new role of AI in ACP where agents act as personal advocates for individuals, building mutual intelligibility over time. We conclude with design recommendations to balance the risks and benefits of such an agent.
Distilled Prompt Learning for Incomplete Multimodal Survival Prediction
Mar 03, 2025The integration of multimodal data including pathology images and gene profiles is widely applied in precise survival prediction. Despite recent advances in multimodal survival models, collecting complete modalities for multimodal fusion still poses a significant challenge, hindering their application in clinical settings. Current approaches tackling incomplete modalities often fall short, as they typically compensate for only a limited part of the knowledge of missing modalities. To address this issue, we propose a Distilled Prompt Learning framework (DisPro) to utilize the strong robustness of Large Language Models (LLMs) to missing modalities, which employs two-stage prompting for compensation of comprehensive information for missing modalities. In the first stage, Unimodal Prompting (UniPro) distills the knowledge distribution of each modality, preparing for supplementing modality-specific knowledge of the missing modality in the subsequent stage. In the second stage, Multimodal Prompting (MultiPro) leverages available modalities as prompts for LLMs to infer the missing modality, which provides modality-common information. Simultaneously, the unimodal knowledge acquired in the first stage is injected into multimodal inference to compensate for the modality-specific knowledge of the missing modality. Extensive experiments covering various missing scenarios demonstrated the superiority of the proposed method. The code is available at https://github.com/Innse/DisPro.
Multimodal Data Integration for Precision Oncology: Challenges and Future Directions
Jun 28, 2024The essence of precision oncology lies in its commitment to tailor targeted treatments and care measures to each patient based on the individual characteristics of the tumor. The inherent heterogeneity of tumors necessitates gathering information from diverse data sources to provide valuable insights from various perspectives, fostering a holistic comprehension of the tumor. Over the past decade, multimodal data integration technology for precision oncology has made significant strides, showcasing remarkable progress in understanding the intricate details within heterogeneous data modalities. These strides have exhibited tremendous potential for improving clinical decision-making and model interpretation, contributing to the advancement of cancer care and treatment. Given the rapid progress that has been achieved, we provide a comprehensive overview of about 300 papers detailing cutting-edge multimodal data integration techniques in precision oncology. In addition, we conclude the primary clinical applications that have reaped significant benefits, including early assessment, diagnosis, prognosis, and biomarker discovery. Finally, derived from the findings of this survey, we present an in-depth analysis that explores the pivotal challenges and reveals essential pathways for future research in the field of multimodal data integration for precision oncology.
F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Oct 23, 2023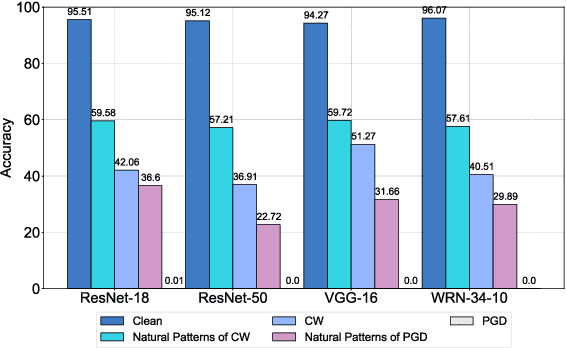

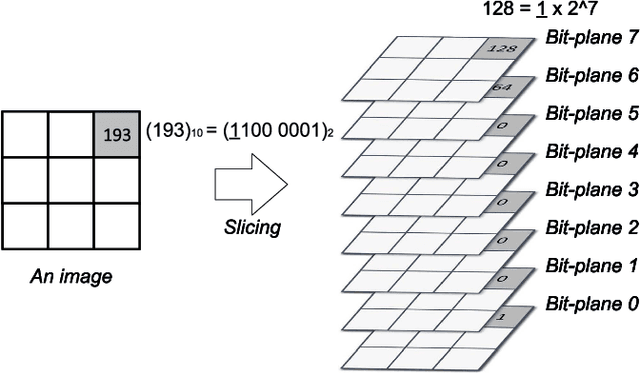
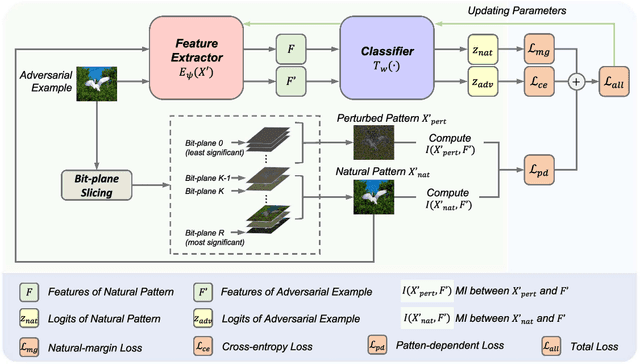
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.
Differentiable Retrieval Augmentation via Generative Language Modeling for E-commerce Query Intent Classification
Aug 21, 2023Retrieval augmentation, which enhances downstream models by a knowledge retriever and an external corpus instead of by merely increasing the number of model parameters, has been successfully applied to many natural language processing (NLP) tasks such as text classification, question answering and so on. However, existing methods that separately or asynchronously train the retriever and downstream model mainly due to the non-differentiability between the two parts, usually lead to degraded performance compared to end-to-end joint training. In this paper, we propose Differentiable Retrieval Augmentation via Generative lANguage modeling(Dragan), to address this problem by a novel differentiable reformulation. We demonstrate the effectiveness of our proposed method on a challenging NLP task in e-commerce search, namely query intent classification. Both the experimental results and ablation study show that the proposed method significantly and reasonably improves the state-of-the-art baselines on both offline evaluation and online A/B test.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022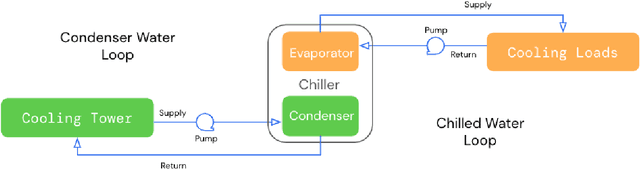
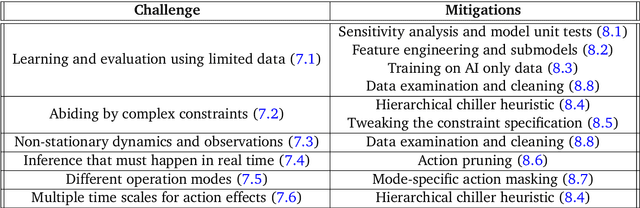
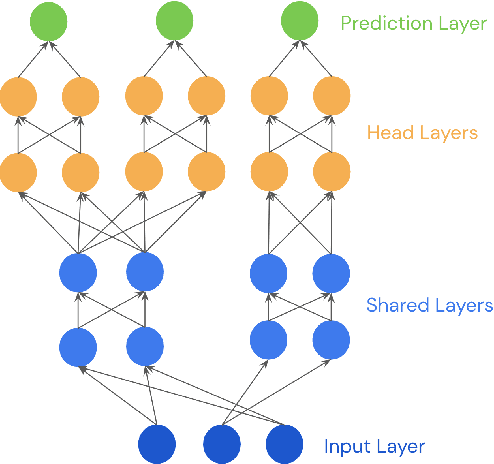
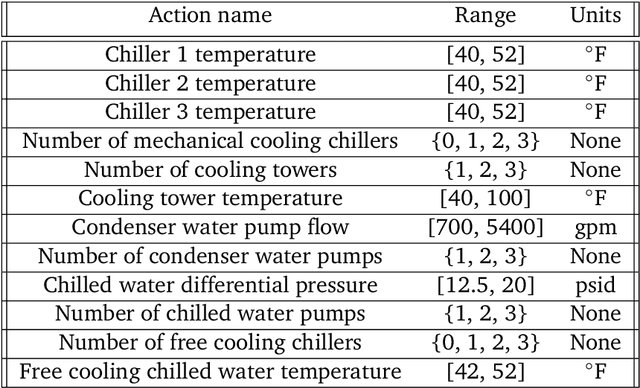
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search
Aug 22, 2022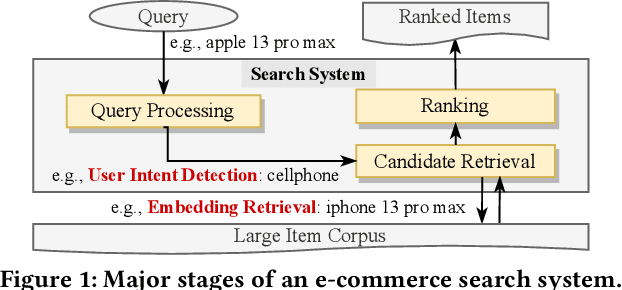

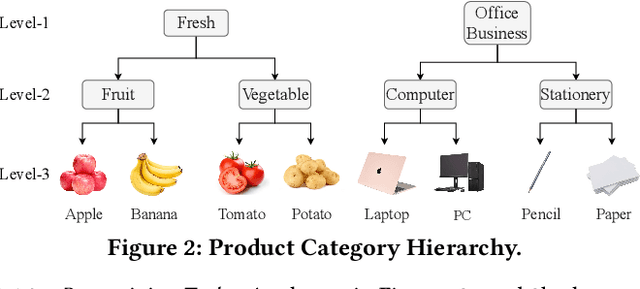
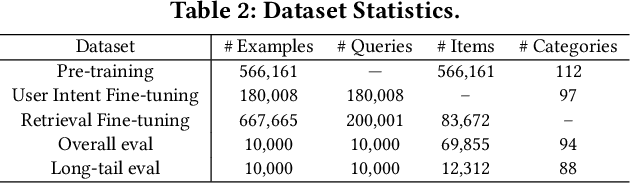
BERT-style models pre-trained on the general corpus (e.g., Wikipedia) and fine-tuned on specific task corpus, have recently emerged as breakthrough techniques in many NLP tasks: question answering, text classification, sequence labeling and so on. However, this technique may not always work, especially for two scenarios: a corpus that contains very different text from the general corpus Wikipedia, or a task that learns embedding spacial distribution for a specific purpose (e.g., approximate nearest neighbor search). In this paper, to tackle the above two scenarios that we have encountered in an industrial e-commerce search system, we propose customized and novel pre-training tasks for two critical modules: user intent detection and semantic embedding retrieval. The customized pre-trained models after fine-tuning, being less than 10% of BERT-base's size in order to be feasible for cost-efficient CPU serving, significantly improve the other baseline models: 1) no pre-training model and 2) fine-tuned model from the official pre-trained BERT using general corpus, on both offline datasets and online system. We have open sourced our datasets for the sake of reproducibility and future works.