 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXGroundingCT: A 3D Chest CT Dataset for Segmentation of Findings from Free-Text Reports
Jul 29, 2025We present ReXGroundingCT, the first publicly available dataset to link free-text radiology findings with pixel-level segmentations in 3D chest CT scans that is manually annotated. While prior datasets have relied on structured labels or predefined categories, ReXGroundingCT captures the full expressiveness of clinical language represented in free text and grounds it to spatially localized 3D segmentation annotations in volumetric imaging. This addresses a critical gap in medical AI: the ability to connect complex, descriptive text, such as "3 mm nodule in the left lower lobe", to its precise anatomical location in three-dimensional space, a capability essential for grounded radiology report generation systems. The dataset comprises 3,142 non-contrast chest CT scans paired with standardized radiology reports from the CT-RATE dataset. Using a systematic three-stage pipeline, GPT-4 was used to extract positive lung and pleural findings, which were then manually segmented by expert annotators. A total of 8,028 findings across 16,301 entities were annotated, with quality control performed by board-certified radiologists. Approximately 79% of findings are focal abnormalities, while 21% are non-focal. The training set includes up to three representative segmentations per finding, while the validation and test sets contain exhaustive labels for each finding entity. ReXGroundingCT establishes a new benchmark for developing and evaluating sentence-level grounding and free-text medical segmentation models in chest CT. The dataset can be accessed at https://huggingface.co/datasets/rajpurkarlab/ReXGroundingCT.
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025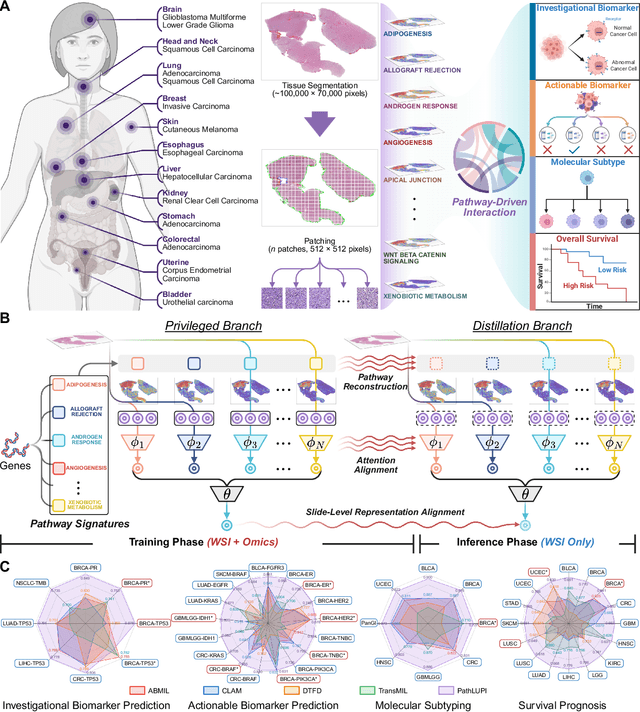
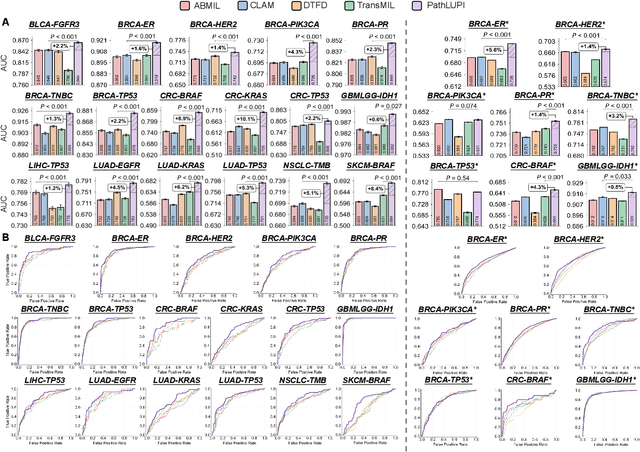
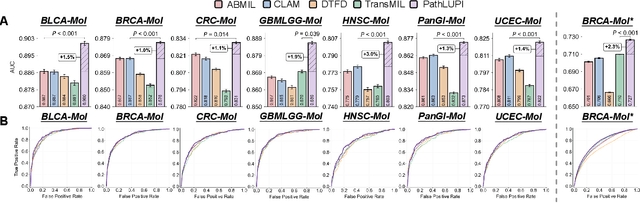
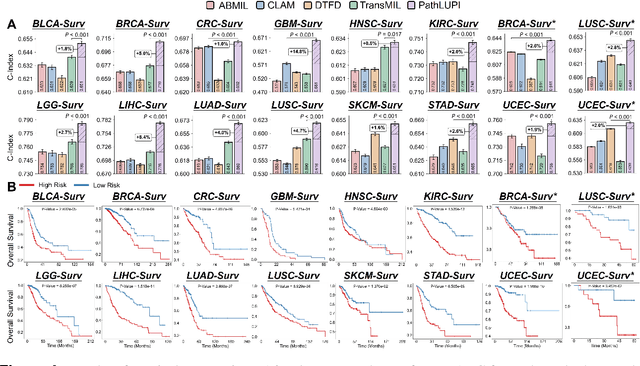
Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
PathBench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology
May 26, 2025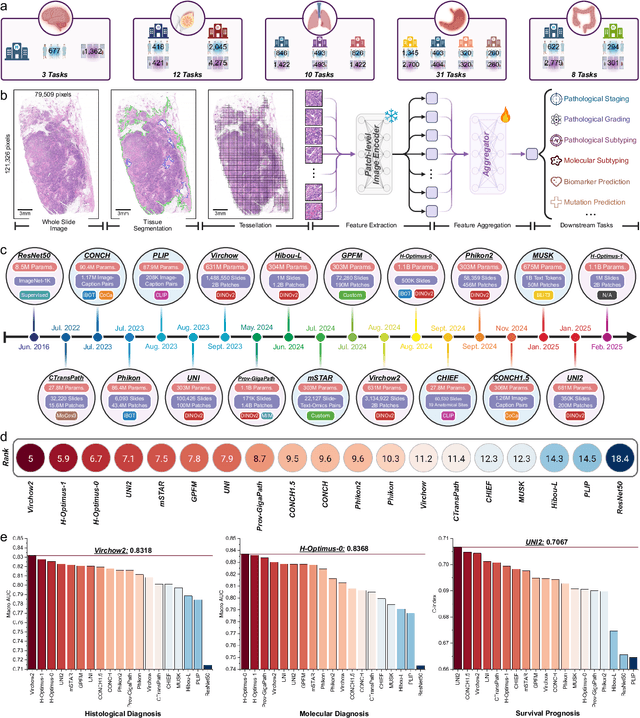



The emergence of pathology foundation models has revolutionized computational histopathology, enabling highly accurate, generalized whole-slide image analysis for improved cancer diagnosis, and prognosis assessment. While these models show remarkable potential across cancer diagnostics and prognostics, their clinical translation faces critical challenges including variability in optimal model across cancer types, potential data leakage in evaluation, and lack of standardized benchmarks. Without rigorous, unbiased evaluation, even the most advanced PFMs risk remaining confined to research settings, delaying their life-saving applications. Existing benchmarking efforts remain limited by narrow cancer-type focus, potential pretraining data overlaps, or incomplete task coverage. We present PathBench, the first comprehensive benchmark addressing these gaps through: multi-center in-hourse datasets spanning common cancers with rigorous leakage prevention, evaluation across the full clinical spectrum from diagnosis to prognosis, and an automated leaderboard system for continuous model assessment. Our framework incorporates large-scale data, enabling objective comparison of PFMs while reflecting real-world clinical complexity. All evaluation data comes from private medical providers, with strict exclusion of any pretraining usage to avoid data leakage risks. We have collected 15,888 WSIs from 8,549 patients across 10 hospitals, encompassing over 64 diagnosis and prognosis tasks. Currently, our evaluation of 19 PFMs shows that Virchow2 and H-Optimus-1 are the most effective models overall. This work provides researchers with a robust platform for model development and offers clinicians actionable insights into PFM performance across diverse clinical scenarios, ultimately accelerating the translation of these transformative technologies into routine pathology practice.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025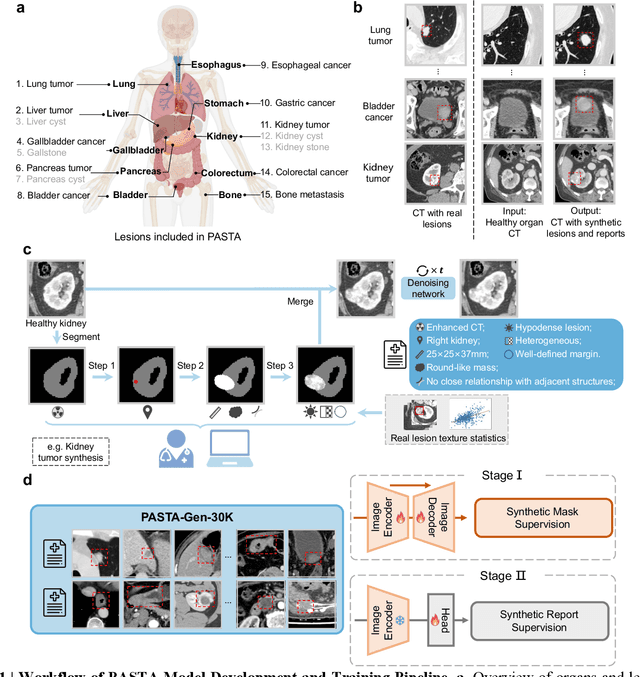
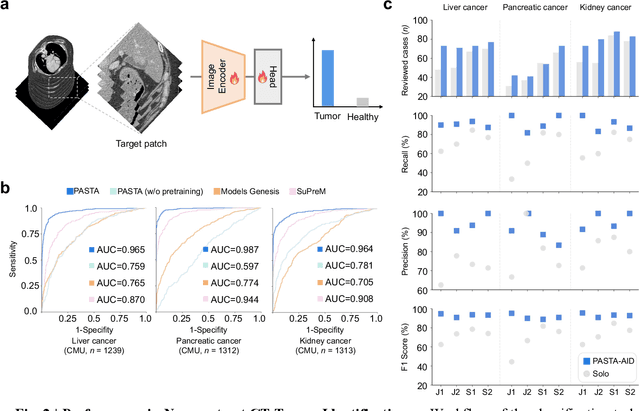
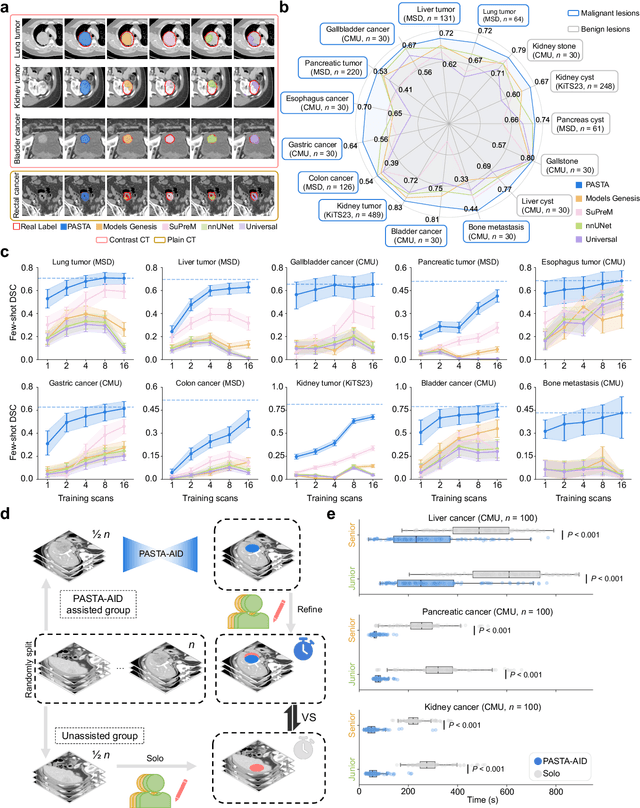
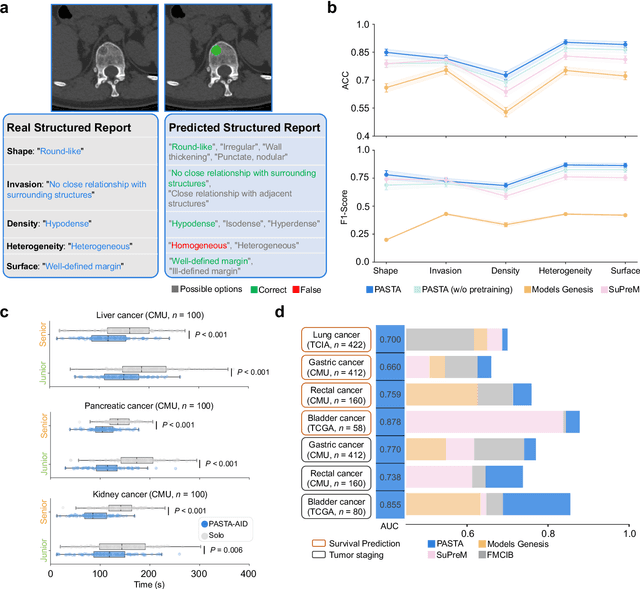
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.
HMIL: Hierarchical Multi-Instance Learning for Fine-Grained Whole Slide Image Classification
Nov 12, 2024



Fine-grained classification of whole slide images (WSIs) is essential in precision oncology, enabling precise cancer diagnosis and personalized treatment strategies. The core of this task involves distinguishing subtle morphological variations within the same broad category of gigapixel-resolution images, which presents a significant challenge. While the multi-instance learning (MIL) paradigm alleviates the computational burden of WSIs, existing MIL methods often overlook hierarchical label correlations, treating fine-grained classification as a flat multi-class classification task. To overcome these limitations, we introduce a novel hierarchical multi-instance learning (HMIL) framework. By facilitating on the hierarchical alignment of inherent relationships between different hierarchy of labels at instance and bag level, our approach provides a more structured and informative learning process. Specifically, HMIL incorporates a class-wise attention mechanism that aligns hierarchical information at both the instance and bag levels. Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability for fine-grained classification and a curriculum-based dynamic weighting module to adaptively balance the hierarchical feature during training. Extensive experiments on our large-scale cytology cervical cancer (CCC) dataset and two public histology datasets, BRACS and PANDA, demonstrate the state-of-the-art class-wise and overall performance of our HMIL framework. Our source code is available at https://github.com/ChengJin-git/HMIL.
Self-eXplainable AI for Medical Image Analysis: A Survey and New Outlooks
Oct 03, 2024



The increasing demand for transparent and reliable models, particularly in high-stakes decision-making areas such as medical image analysis, has led to the emergence of eXplainable Artificial Intelligence (XAI). Post-hoc XAI techniques, which aim to explain black-box models after training, have been controversial in recent works concerning their fidelity to the models' predictions. In contrast, Self-eXplainable AI (S-XAI) offers a compelling alternative by incorporating explainability directly into the training process of deep learning models. This approach allows models to generate inherent explanations that are closely aligned with their internal decision-making processes. Such enhanced transparency significantly supports the trustworthiness, robustness, and accountability of AI systems in real-world medical applications. To facilitate the development of S-XAI methods for medical image analysis, this survey presents an comprehensive review across various image modalities and clinical applications. It covers more than 200 papers from three key perspectives: 1) input explainability through the integration of explainable feature engineering and knowledge graph, 2) model explainability via attention-based learning, concept-based learning, and prototype-based learning, and 3) output explainability by providing counterfactual explanation and textual explanation. Additionally, this paper outlines the desired characteristics of explainability and existing evaluation methods for assessing explanation quality. Finally, it discusses the major challenges and future research directions in developing S-XAI for medical image analysis.
ReXplain: Translating Radiology into Patient-Friendly Video Reports
Oct 01, 2024



Radiology reports often remain incomprehensible to patients, undermining patient-centered care. We present ReXplain (Radiology eXplanation), an innovative AI-driven system that generates patient-friendly video reports for radiology findings. ReXplain uniquely integrates a large language model for text simplification, an image segmentation model for anatomical region identification, and an avatar generation tool, producing comprehensive explanations with plain language, highlighted imagery, and 3D organ renderings. Our proof-of-concept study with five board-certified radiologists indicates that ReXplain could accurately deliver radiological information and effectively simulate one-on-one consultations. This work demonstrates a new paradigm in AI-assisted medical communication, potentially improving patient engagement and satisfaction in radiology care, and opens new avenues for research in multimodal medical communication.
SurgPETL: Parameter-Efficient Image-to-Surgical-Video Transfer Learning for Surgical Phase Recognition
Sep 30, 2024Capitalizing on image-level pre-trained models for various downstream tasks has recently emerged with promising performance. However, the paradigm of "image pre-training followed by video fine-tuning" for high-dimensional video data inevitably poses significant performance bottlenecks. Furthermore, in the medical domain, many surgical video tasks encounter additional challenges posed by the limited availability of video data and the necessity for comprehensive spatial-temporal modeling. Recently, Parameter-Efficient Image-to-Video Transfer Learning has emerged as an efficient and effective paradigm for video action recognition tasks, which employs image-level pre-trained models with promising feature transferability and involves cross-modality temporal modeling with minimal fine-tuning. Nevertheless, the effectiveness and generalizability of this paradigm within intricate surgical domain remain unexplored. In this paper, we delve into a novel problem of efficiently adapting image-level pre-trained models to specialize in fine-grained surgical phase recognition, termed as Parameter-Efficient Image-to-Surgical-Video Transfer Learning. Firstly, we develop a parameter-efficient transfer learning benchmark SurgPETL for surgical phase recognition, and conduct extensive experiments with three advanced methods based on ViTs of two distinct scales pre-trained on five large-scale natural and medical datasets. Then, we introduce the Spatial-Temporal Adaptation module, integrating a standard spatial adapter with a novel temporal adapter to capture detailed spatial features and establish connections across temporal sequences for robust spatial-temporal modeling. Extensive experiments on three challenging datasets spanning various surgical procedures demonstrate the effectiveness of SurgPETL with STA.
Surgformer: Surgical Transformer with Hierarchical Temporal Attention for Surgical Phase Recognition
Aug 07, 2024Existing state-of-the-art methods for surgical phase recognition either rely on the extraction of spatial-temporal features at a short-range temporal resolution or adopt the sequential extraction of the spatial and temporal features across the entire temporal resolution. However, these methods have limitations in modeling spatial-temporal dependency and addressing spatial-temporal redundancy: 1) These methods fail to effectively model spatial-temporal dependency, due to the lack of long-range information or joint spatial-temporal modeling. 2) These methods utilize dense spatial features across the entire temporal resolution, resulting in significant spatial-temporal redundancy. In this paper, we propose the Surgical Transformer (Surgformer) to address the issues of spatial-temporal modeling and redundancy in an end-to-end manner, which employs divided spatial-temporal attention and takes a limited set of sparse frames as input. Moreover, we propose a novel Hierarchical Temporal Attention (HTA) to capture both global and local information within varied temporal resolutions from a target frame-centric perspective. Distinct from conventional temporal attention that primarily emphasizes dense long-range similarity, HTA not only captures long-term information but also considers local latent consistency among informative frames. HTA then employs pyramid feature aggregation to effectively utilize temporal information across diverse temporal resolutions, thereby enhancing the overall temporal representation. Extensive experiments on two challenging benchmark datasets verify that our proposed Surgformer performs favorably against the state-of-the-art methods. The code is released at https://github.com/isyangshu/Surgformer.