 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaMIL+: Modeling Long-Term Contextual Patterns for Gigapixel Whole Slide Image
Dec 19, 2025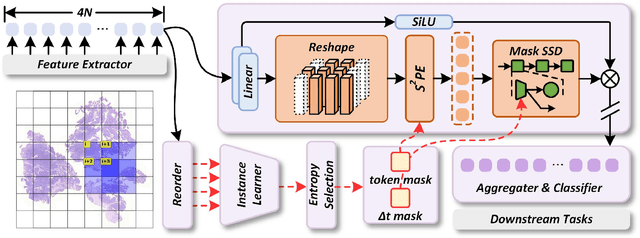
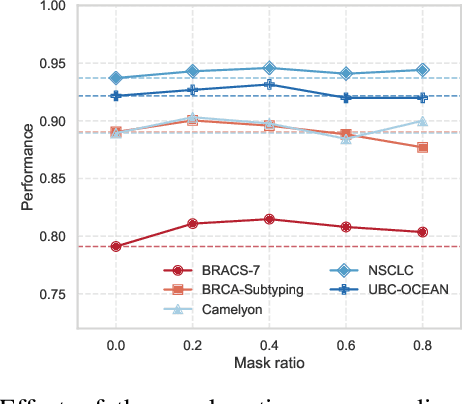
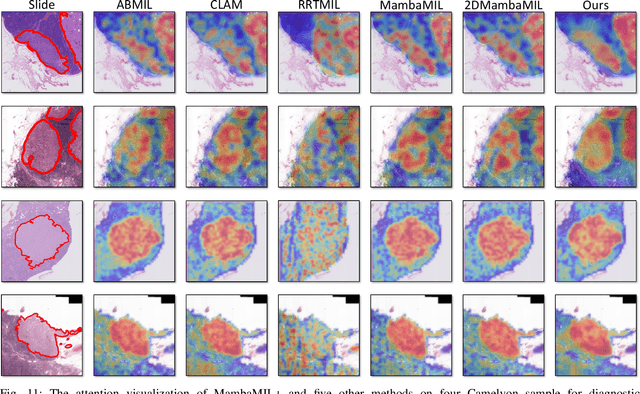
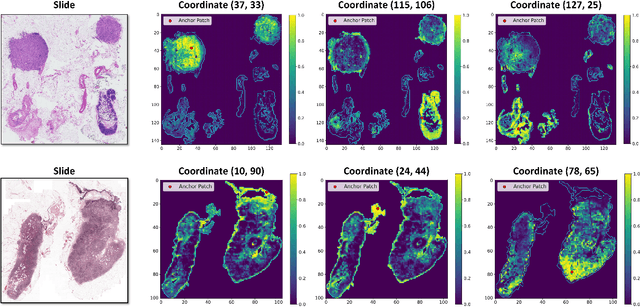
Whole-slide images (WSIs) are an important data modality in computational pathology, yet their gigapixel resolution and lack of fine-grained annotations challenge conventional deep learning models. Multiple instance learning (MIL) offers a solution by treating each WSI as a bag of patch-level instances, but effectively modeling ultra-long sequences with rich spatial context remains difficult. Recently, Mamba has emerged as a promising alternative for long sequence learning, scaling linearly to thousands of tokens. However, despite its efficiency, it still suffers from limited spatial context modeling and memory decay, constraining its effectiveness to WSI analysis. To address these limitations, we propose MambaMIL+, a new MIL framework that explicitly integrates spatial context while maintaining long-range dependency modeling without memory forgetting. Specifically, MambaMIL+ introduces 1) overlapping scanning, which restructures the patch sequence to embed spatial continuity and instance correlations; 2) a selective stripe position encoder (S2PE) that encodes positional information while mitigating the biases of fixed scanning orders; and 3) a contextual token selection (CTS) mechanism, which leverages supervisory knowledge to dynamically enlarge the contextual memory for stable long-range modeling. Extensive experiments on 20 benchmarks across diagnostic classification, molecular prediction, and survival analysis demonstrate that MambaMIL+ consistently achieves state-of-the-art performance under three feature extractors (ResNet-50, PLIP, and CONCH), highlighting its effectiveness and robustness for large-scale computational pathology
A Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.
A Multimodal Foundation Model to Enhance Generalizability and Data Efficiency for Pan-cancer Prognosis Prediction
Sep 16, 2025Multimodal data provides heterogeneous information for a holistic understanding of the tumor microenvironment. However, existing AI models often struggle to harness the rich information within multimodal data and extract poorly generalizable representations. Here we present MICE (Multimodal data Integration via Collaborative Experts), a multimodal foundation model that effectively integrates pathology images, clinical reports, and genomics data for precise pan-cancer prognosis prediction. Instead of conventional multi-expert modules, MICE employs multiple functionally diverse experts to comprehensively capture both cross-cancer and cancer-specific insights. Leveraging data from 11,799 patients across 30 cancer types, we enhanced MICE's generalizability by coupling contrastive and supervised learning. MICE outperformed both unimodal and state-of-the-art multi-expert-based multimodal models, demonstrating substantial improvements in C-index ranging from 3.8% to 11.2% on internal cohorts and 5.8% to 8.8% on independent cohorts, respectively. Moreover, it exhibited remarkable data efficiency across diverse clinical scenarios. With its enhanced generalizability and data efficiency, MICE establishes an effective and scalable foundation for pan-cancer prognosis prediction, holding strong potential to personalize tailored therapies and improve treatment outcomes.
A Versatile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model
Jul 23, 2025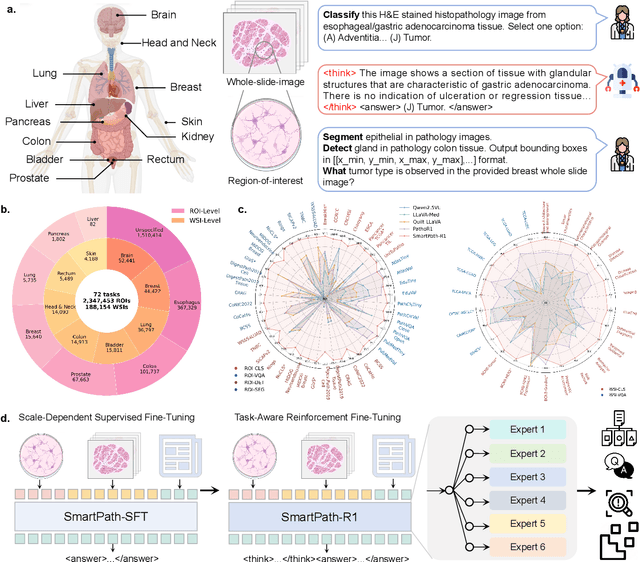
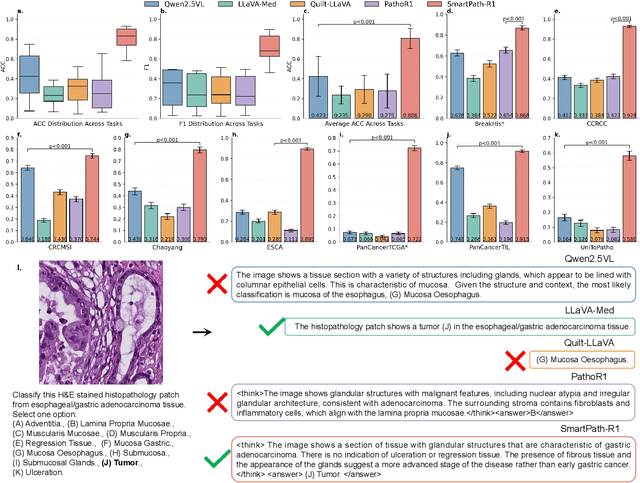
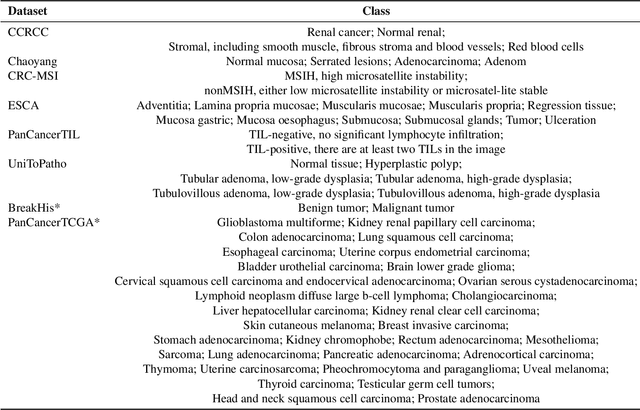
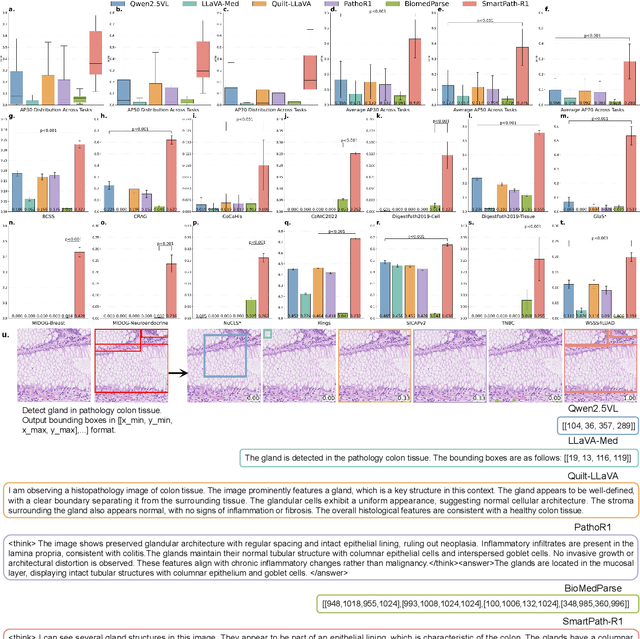
Multimodal large language models (MLLMs) have emerged as powerful tools for computational pathology, offering unprecedented opportunities to integrate pathological images with language context for comprehensive diagnostic analysis. These models hold particular promise for automating complex tasks that traditionally require expert interpretation of pathologists. However, current MLLM approaches in pathology demonstrate significantly constrained reasoning capabilities, primarily due to their reliance on expensive chain-of-thought annotations. Additionally, existing methods remain limited to simplex application of visual question answering (VQA) at region-of-interest (ROI) level, failing to address the full spectrum of diagnostic needs such as ROI classification, detection, segmentation, whole-slide-image (WSI) classification and VQA in clinical practice. In this study, we present SmartPath-R1, a versatile MLLM capable of simultaneously addressing both ROI-level and WSI-level tasks while demonstrating robust pathological reasoning capability. Our framework combines scale-dependent supervised fine-tuning and task-aware reinforcement fine-tuning, which circumvents the requirement for chain-of-thought supervision by leveraging the intrinsic knowledge within MLLM. Furthermore, SmartPath-R1 integrates multiscale and multitask analysis through a mixture-of-experts mechanism, enabling dynamic processing for diverse tasks. We curate a large-scale dataset comprising 2.3M ROI samples and 188K WSI samples for training and evaluation. Extensive experiments across 72 tasks validate the effectiveness and superiority of the proposed approach. This work represents a significant step toward developing versatile, reasoning-enhanced AI systems for precision pathology.
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025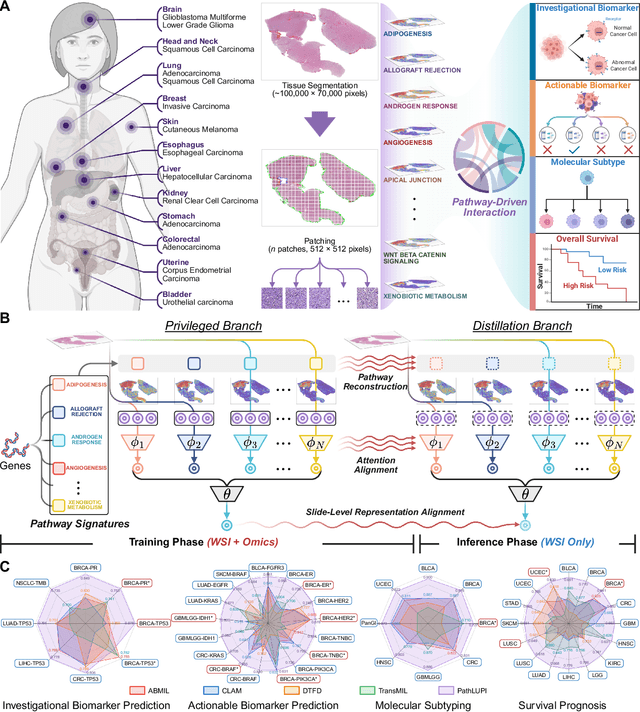
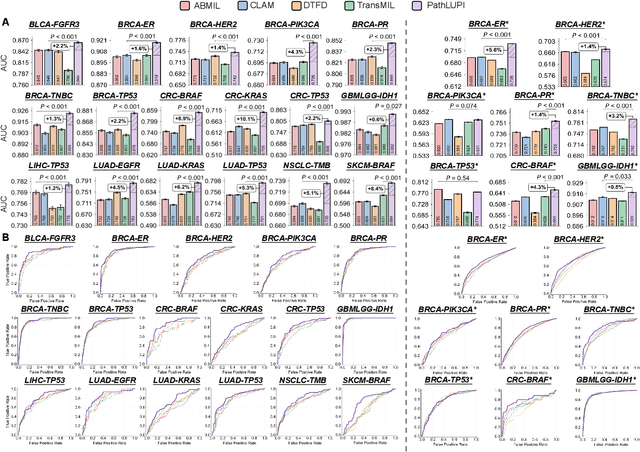
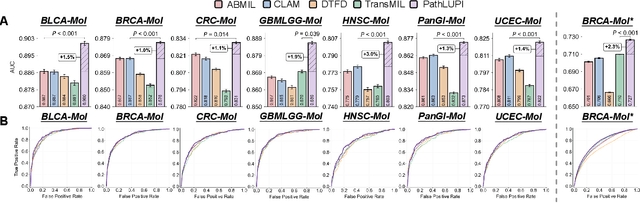
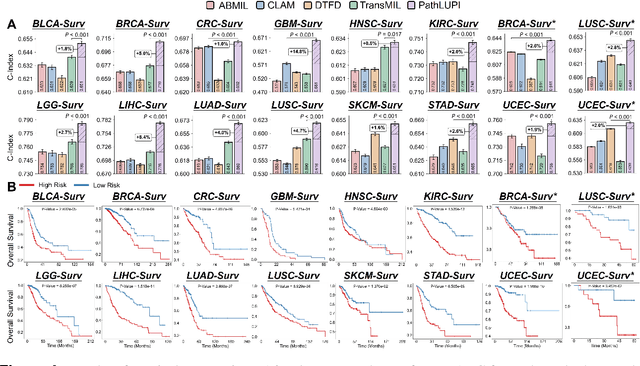
Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
PathBench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology
May 26, 2025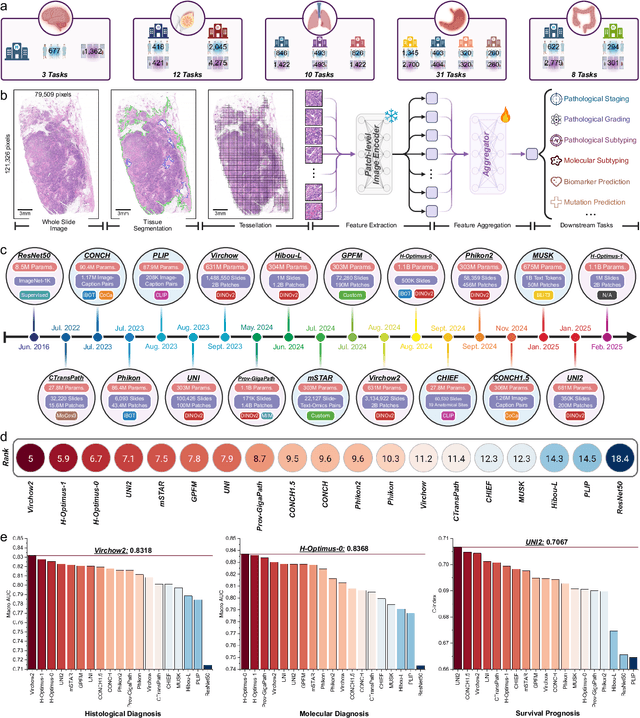



The emergence of pathology foundation models has revolutionized computational histopathology, enabling highly accurate, generalized whole-slide image analysis for improved cancer diagnosis, and prognosis assessment. While these models show remarkable potential across cancer diagnostics and prognostics, their clinical translation faces critical challenges including variability in optimal model across cancer types, potential data leakage in evaluation, and lack of standardized benchmarks. Without rigorous, unbiased evaluation, even the most advanced PFMs risk remaining confined to research settings, delaying their life-saving applications. Existing benchmarking efforts remain limited by narrow cancer-type focus, potential pretraining data overlaps, or incomplete task coverage. We present PathBench, the first comprehensive benchmark addressing these gaps through: multi-center in-hourse datasets spanning common cancers with rigorous leakage prevention, evaluation across the full clinical spectrum from diagnosis to prognosis, and an automated leaderboard system for continuous model assessment. Our framework incorporates large-scale data, enabling objective comparison of PFMs while reflecting real-world clinical complexity. All evaluation data comes from private medical providers, with strict exclusion of any pretraining usage to avoid data leakage risks. We have collected 15,888 WSIs from 8,549 patients across 10 hospitals, encompassing over 64 diagnosis and prognosis tasks. Currently, our evaluation of 19 PFMs shows that Virchow2 and H-Optimus-1 are the most effective models overall. This work provides researchers with a robust platform for model development and offers clinicians actionable insights into PFM performance across diverse clinical scenarios, ultimately accelerating the translation of these transformative technologies into routine pathology practice.
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
Context Matters: Query-aware Dynamic Long Sequence Modeling of Gigapixel Images
Jan 31, 2025Whole slide image (WSI) analysis presents significant computational challenges due to the massive number of patches in gigapixel images. While transformer architectures excel at modeling long-range correlations through self-attention, their quadratic computational complexity makes them impractical for computational pathology applications. Existing solutions like local-global or linear self-attention reduce computational costs but compromise the strong modeling capabilities of full self-attention. In this work, we propose Querent, i.e., the query-aware long contextual dynamic modeling framework, which maintains the expressive power of full self-attention while achieving practical efficiency. Our method adaptively predicts which surrounding regions are most relevant for each patch, enabling focused yet unrestricted attention computation only with potentially important contexts. By using efficient region-wise metadata computation and importance estimation, our approach dramatically reduces computational overhead while preserving global perception to model fine-grained patch correlations. Through comprehensive experiments on biomarker prediction, gene mutation prediction, cancer subtyping, and survival analysis across over 10 WSI datasets, our method demonstrates superior performance compared to the state-of-the-art approaches. Code will be made available at https://github.com/dddavid4real/Querent.
FOCUS: Knowledge-enhanced Adaptive Visual Compression for Few-shot Whole Slide Image Classification
Nov 22, 2024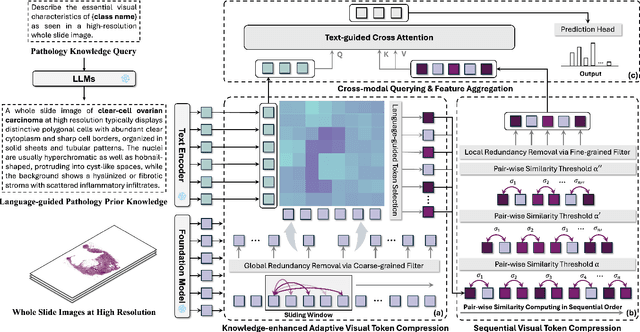
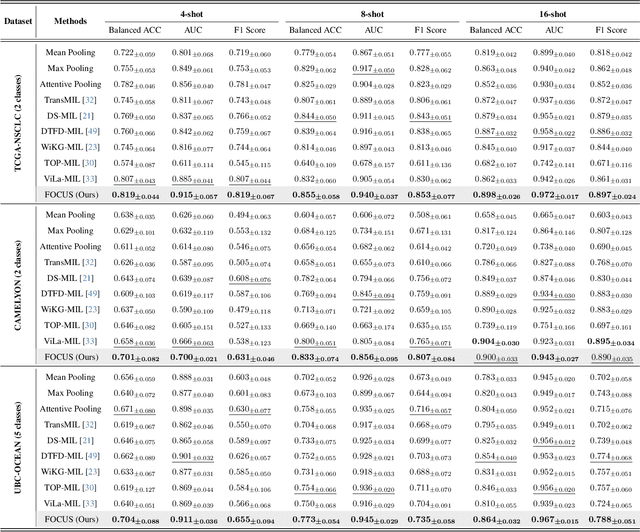
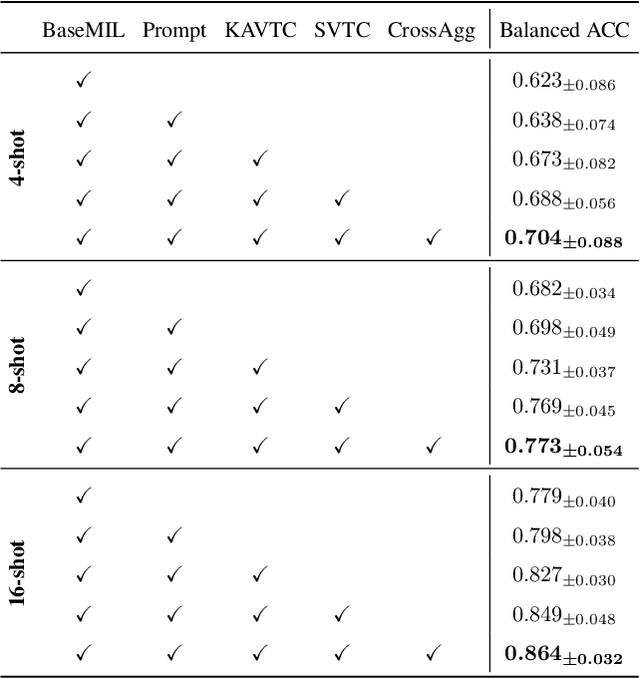
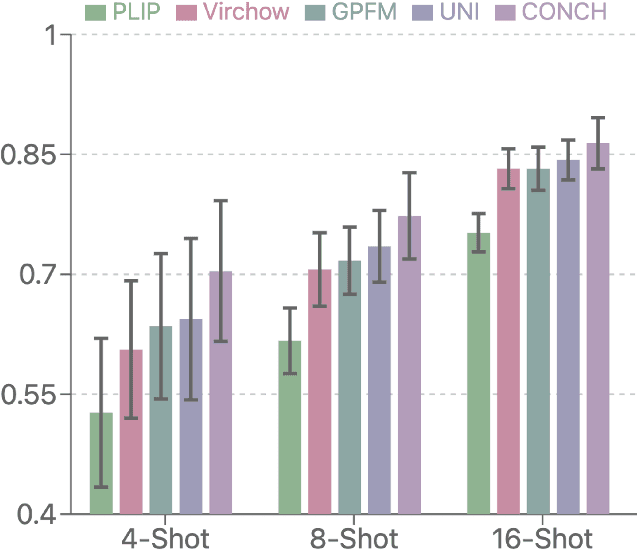
Few-shot learning presents a critical solution for cancer diagnosis in computational pathology (CPath), addressing fundamental limitations in data availability, particularly the scarcity of expert annotations and patient privacy constraints. A key challenge in this paradigm stems from the inherent disparity between the limited training set of whole slide images (WSIs) and the enormous number of contained patches, where a significant portion of these patches lacks diagnostically relevant information, potentially diluting the model's ability to learn and focus on critical diagnostic features. While recent works attempt to address this by incorporating additional knowledge, several crucial gaps hinder further progress: (1) despite the emergence of powerful pathology foundation models (FMs), their potential remains largely untapped, with most approaches limiting their use to basic feature extraction; (2) current language guidance mechanisms attempt to align text prompts with vast numbers of WSI patches all at once, struggling to leverage rich pathological semantic information. To this end, we introduce the knowledge-enhanced adaptive visual compression framework, dubbed FOCUS, which uniquely combines pathology FMs with language prior knowledge to enable a focused analysis of diagnostically relevant regions by prioritizing discriminative WSI patches. Our approach implements a progressive three-stage compression strategy: we first leverage FMs for global visual redundancy elimination, and integrate compressed features with language prompts for semantic relevance assessment, then perform neighbor-aware visual token filtering while preserving spatial coherence. Extensive experiments on pathological datasets spanning breast, lung, and ovarian cancers demonstrate its superior performance in few-shot pathology diagnosis. Code will be made available at https://github.com/dddavid4real/FOCUS.