 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRFT: Consistent-Recurrent Feature Flow Transformer for Cross-Modal Image Registration
Apr 07, 2026We present Consistent-Recurrent Feature Flow Transformer (CRFT), a unified coarse-to-fine framework based on feature flow learning for robust cross-modal image registration. CRFT learns a modality-independent feature flow representation within a transformer-based architecture that jointly performs feature alignment and flow estimation. The coarse stage establishes global correspondences through multi-scale feature correlation, while the fine stage refines local details via hierarchical feature fusion and adaptive spatial reasoning. To enhance geometric adaptability, an iterative discrepancy-guided attention mechanism with a Spatial Geometric Transform (SGT) recurrently refines the flow field, progressively capturing subtle spatial inconsistencies and enforcing feature-level consistency. This design enables accurate alignment under large affine and scale variations while maintaining structural coherence across modalities. Extensive experiments on diverse cross-modal datasets demonstrate that CRFT consistently outperforms state-of-the-art registration methods in both accuracy and robustness. Beyond registration, CRFT provides a generalizable paradigm for multimodal spatial correspondence, offering broad applicability to remote sensing, autonomous navigation, and medical imaging. Code and datasets are publicly available at https://github.com/NEU-Liuxuecong/CRFT.
MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
Mar 30, 2026We introduce Multilingual Document Parsing Benchmark, the first benchmark for multilingual digital and photographed document parsing. Document parsing has made remarkable strides, yet almost exclusively on clean, digital, well-formatted pages in a handful of dominant languages. No systematic benchmark exists to evaluate how models perform on digital and photographed documents across diverse scripts and low-resource languages. MDPBench comprises 3,400 document images spanning 17 languages, diverse scripts, and varied photographic conditions, with high-quality annotations produced through a rigorous pipeline of expert model labeling, manual correction, and human verification. To ensure fair comparison and prevent data leakage, we maintain separate public and private evaluation splits. Our comprehensive evaluation of both open-source and closed-source models uncovers a striking finding: while closed-source models (notably Gemini3-Pro) prove relatively robust, open-source alternatives suffer dramatic performance collapse, particularly on non-Latin scripts and real-world photographed documents, with an average drop of 17.8% on photographed documents and 14.0% on non-Latin scripts. These results reveal significant performance imbalances across languages and conditions, and point to concrete directions for building more inclusive, deployment-ready parsing systems. Source available at https://github.com/Yuliang-Liu/MultimodalOCR.
Ridge Estimation-Based Vision and Laser Ranging Fusion Localization Method for UAVs
Dec 18, 2025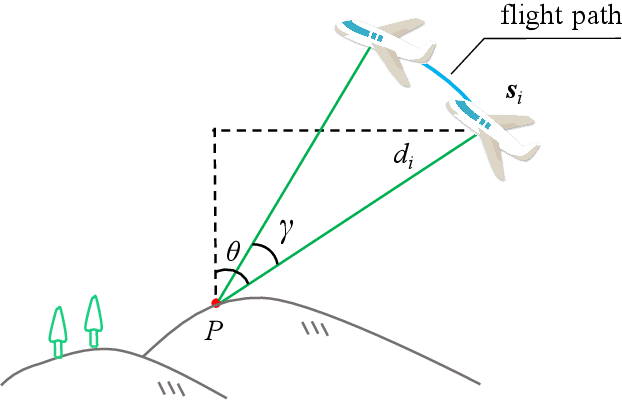

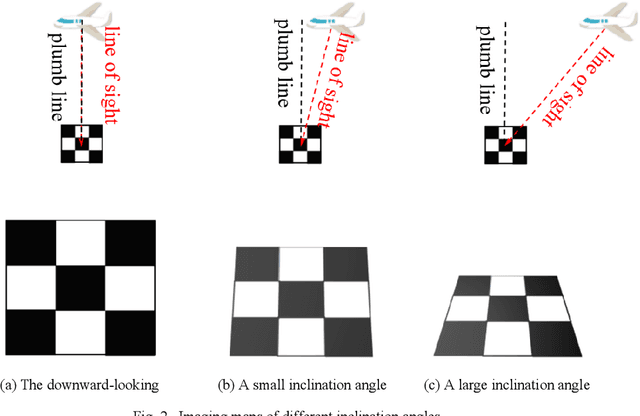
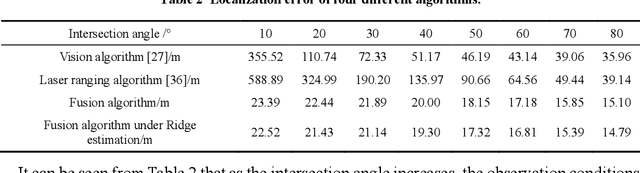
Tracking and measuring targets using a variety of sensors mounted on UAVs is an effective means to quickly and accurately locate the target. This paper proposes a fusion localization method based on ridge estimation, combining the advantages of rich scene information from sequential imagery with the high precision of laser ranging to enhance localization accuracy. Under limited conditions such as long distances, small intersection angles, and large inclination angles, the column vectors of the design matrix have serious multicollinearity when using the least squares estimation algorithm. The multicollinearity will lead to ill-conditioned problems, resulting in significant instability and low robustness. Ridge estimation is introduced to mitigate the serious multicollinearity under the condition of limited observation. Experimental results demonstrate that our method achieves higher localization accuracy compared to ground localization algorithms based on single information. Moreover, the introduction of ridge estimation effectively enhances the robustness, particularly under limited observation conditions.
MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
Nov 16, 2025Document parsing is a core task in document intelligence, supporting applications such as information extraction, retrieval-augmented generation, and automated document analysis. However, real-world documents often feature complex layouts with multi-level tables, embedded images or formulas, and cross-page structures, which remain challenging for existing OCR systems. We introduce MonkeyOCR v1.5, a unified vision-language framework that enhances both layout understanding and content recognition through a two-stage pipeline. The first stage employs a large multimodal model to jointly predict layout and reading order, leveraging visual information to ensure sequential consistency. The second stage performs localized recognition of text, formulas, and tables within detected regions, maintaining high visual fidelity while reducing error propagation. To address complex table structures, we propose a visual consistency-based reinforcement learning scheme that evaluates recognition quality via render-and-compare alignment, improving structural accuracy without manual annotations. Additionally, two specialized modules, Image-Decoupled Table Parsing and Type-Guided Table Merging, are introduced to enable reliable parsing of tables containing embedded images and reconstruction of tables crossing pages or columns. Comprehensive experiments on OmniDocBench v1.5 demonstrate that MonkeyOCR v1.5 achieves state-of-the-art performance, outperforming PPOCR-VL and MinerU 2.5 while showing exceptional robustness in visually complex document scenarios. A trial link can be found at https://github.com/Yuliang-Liu/MonkeyOCR .
MSTAR: Box-free Multi-query Scene Text Retrieval with Attention Recycling
Jun 12, 2025Scene text retrieval has made significant progress with the assistance of accurate text localization. However, existing approaches typically require costly bounding box annotations for training. Besides, they mostly adopt a customized retrieval strategy but struggle to unify various types of queries to meet diverse retrieval needs. To address these issues, we introduce Muti-query Scene Text retrieval with Attention Recycling (MSTAR), a box-free approach for scene text retrieval. It incorporates progressive vision embedding to dynamically capture the multi-grained representation of texts and harmonizes free-style text queries with style-aware instructions. Additionally, a multi-instance matching module is integrated to enhance vision-language alignment. Furthermore, we build the Multi-Query Text Retrieval (MQTR) dataset, the first benchmark designed to evaluate the multi-query scene text retrieval capability of models, comprising four query types and 16k images. Extensive experiments demonstrate the superiority of our method across seven public datasets and the MQTR dataset. Notably, MSTAR marginally surpasses the previous state-of-the-art model by 6.4% in MAP on Total-Text while eliminating box annotation costs. Moreover, on the MQTR benchmark, MSTAR significantly outperforms the previous models by an average of 8.5%. The code and datasets are available at https://github.com/yingift/MSTAR.
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Jun 05, 2025We introduce MonkeyOCR, a vision-language model for document parsing that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline (as in MinerU's modular approach) and avoids the inefficiencies of processing full pages with giant end-to-end models (e.g., large multimodal LLMs like Qwen-VL). In SRR, document parsing is abstracted into three fundamental questions - "Where is it?" (structure), "What is it?" (recognition), and "How is it organized?" (relation) - corresponding to layout analysis, content identification, and logical ordering. This focused decomposition balances accuracy and speed: it enables efficient, scalable processing without sacrificing precision. To train and evaluate this approach, we introduce the MonkeyDoc (the most comprehensive document parsing dataset to date), with 3.9 million instances spanning over ten document types in both Chinese and English. Experiments show that MonkeyOCR outperforms MinerU by an average of 5.1%, with particularly notable improvements on challenging content such as formulas (+15.0%) and tables (+8.6%). Remarkably, our 3B-parameter model surpasses much larger and top-performing models, including Qwen2.5-VL (72B) and Gemini 2.5 Pro, achieving state-of-the-art average performance on English document parsing tasks. In addition, MonkeyOCR processes multi-page documents significantly faster (0.84 pages per second compared to 0.65 for MinerU and 0.12 for Qwen2.5-VL-7B). The 3B model can be efficiently deployed for inference on a single NVIDIA 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.
High-precision visual navigation device calibration method based on collimator
Feb 25, 2025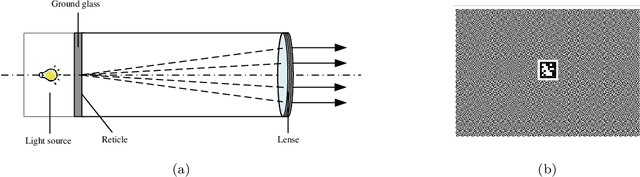
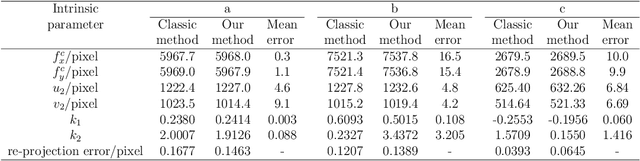
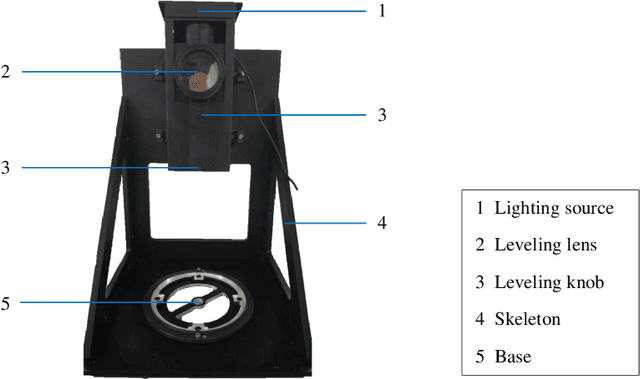

Visual navigation devices require precise calibration to achieve high-precision localization and navigation, which includes camera and attitude calibration. To address the limitations of time-consuming camera calibration and complex attitude adjustment processes, this study presents a collimator-based calibration method and system. Based on the optical characteristics of the collimator, a single-image camera calibration algorithm is introduced. In addition, integrated with the precision adjustment mechanism of the calibration frame, a rotation transfer model between coordinate systems enables efficient attitude calibration. Experimental results demonstrate that the proposed method achieves accuracy and stability comparable to traditional multi-image calibration techniques. Specifically, the re-projection errors are less than 0.1463 pixels, and average attitude angle errors are less than 0.0586 degrees with a standard deviation less than 0.0257 degrees, demonstrating high precision and robustness.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Jul 22, 2024
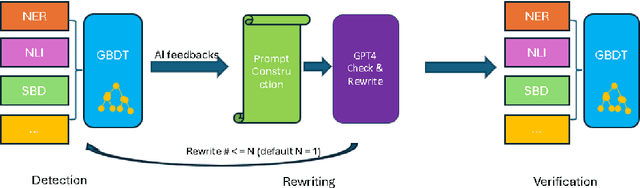
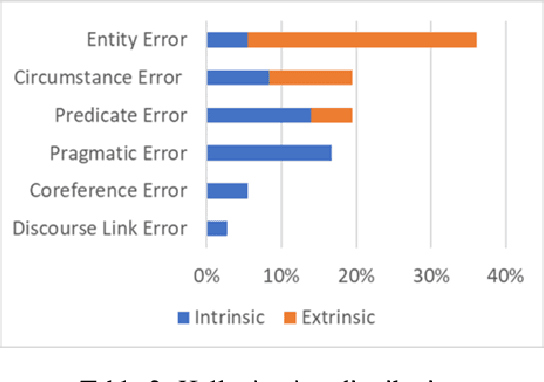
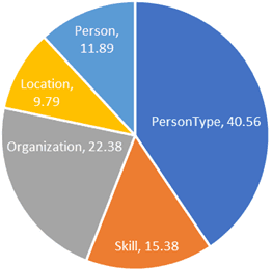
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Exploring the Capabilities of Large Multimodal Models on Dense Text
May 09, 2024



While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.