 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGD$^2$PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
Jun 15, 2026As LLMs advance, post-training reinforcement learning (RL) increasingly relies on multi-dimensional rewards to cultivate comprehensive capabilities. This shift demands new algorithms capable of optimizing diverse and potentially competing objectives simultaneously. To address this, existing methods such as Group reward-Decoupled Policy Optimization (GDPO) decompose the overall score into independent reward groups, then compute the RL loss separately within each group. However, this strategy still encounters multi-reward conflicts: a single rollout can yield positive advantages on certain reward dimensions but negative ones on others, causing opposing signals to cancel each other out during aggregation, further hindering RL training efficiency. Inspired by Dynamic sAmpling Policy Optimization (DAPO), which improves RL training efficiency by filtering out ineffective rollouts with near-zero advantages, we propose Group-Dynamic reward-Decoupled Policy Optimization (GD$^2$PO). Specifically, GD$^2$PO employs a conflict-aware filtering mechanism to mask out rollouts suffering from severe reward-wise disagreement. By preventing conflicting signals from canceling each other out, this masking strategy preserves and enhances the magnitude of effective RL advantages, thereby significantly accelerating learning efficiency. Furthermore, we introduce query-level reweighting to dynamically adjust the update intensity of each query based on its overall reward consensus. Experiments on various multi-reward scenarios, including tool calling and human preference alignment, demonstrate that GD$^2$PO consistently and significantly outperforms existing baselines. The code is available at https://github.com/Qwen-Applications/GD2PO.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
Mar 30, 2026We introduce Multilingual Document Parsing Benchmark, the first benchmark for multilingual digital and photographed document parsing. Document parsing has made remarkable strides, yet almost exclusively on clean, digital, well-formatted pages in a handful of dominant languages. No systematic benchmark exists to evaluate how models perform on digital and photographed documents across diverse scripts and low-resource languages. MDPBench comprises 3,400 document images spanning 17 languages, diverse scripts, and varied photographic conditions, with high-quality annotations produced through a rigorous pipeline of expert model labeling, manual correction, and human verification. To ensure fair comparison and prevent data leakage, we maintain separate public and private evaluation splits. Our comprehensive evaluation of both open-source and closed-source models uncovers a striking finding: while closed-source models (notably Gemini3-Pro) prove relatively robust, open-source alternatives suffer dramatic performance collapse, particularly on non-Latin scripts and real-world photographed documents, with an average drop of 17.8% on photographed documents and 14.0% on non-Latin scripts. These results reveal significant performance imbalances across languages and conditions, and point to concrete directions for building more inclusive, deployment-ready parsing systems. Source available at https://github.com/Yuliang-Liu/MultimodalOCR.
MARCH: Multi-Agent Reinforced Self-Check for LLM Hallucination
Mar 25, 2026Hallucination remains a critical bottleneck for large language models (LLMs), undermining their reliability in real-world applications, especially in Retrieval-Augmented Generation (RAG) systems. While existing hallucination detection methods employ LLM-as-a-judge to verify LLM outputs against retrieved evidence, they suffer from inherent confirmation bias, where the verifier inadvertently reproduces the errors of the original generation. To address this, we introduce Multi-Agent Reinforced Self-Check for Hallucination (MARCH), a framework that enforces rigorous factual alignment by leveraging deliberate information asymmetry. MARCH orchestrates a collaborative pipeline of three specialized agents: a Solver, a Proposer, and a Checker. The Solver generates an initial RAG response, which the Proposer decomposes into claim-level verifiable atomic propositions. Crucially, the Checker validates these propositions against retrieved evidence in isolation, deprived of the Solver's original output. This well-crafted information asymmetry scheme breaks the cycle of self-confirmation bias. By training this pipeline with multi-agent reinforcement learning (MARL), we enable the agents to co-evolve and optimize factual adherence. Extensive experiments across hallucination benchmarks demonstrate that MARCH substantially reduces hallucination rates. Notably, an 8B-parameter LLM equipped with MARCH achieves performance competitive with powerful closed-source models. MARCH paves a scalable path for factual self-improvement of LLMs through co-evolution. The code is at https://github.com/Qwen-Applications/MARCH.
CLIPO: Contrastive Learning in Policy Optimization Generalizes RLVR
Mar 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced the reasoning capacity of Large Language Models (LLMs). However, RLVR solely relies on final answers as outcome rewards, neglecting the correctness of intermediate reasoning steps. Training on these process-wrong but outcome-correct rollouts can lead to hallucination and answer-copying, severely undermining the model's generalization and robustness. To address this, we incorporate a Contrastive Learning mechanism into the Policy Optimization (CLIPO) to generalize the RLVR process. By optimizing a contrastive loss over successful rollouts, CLIPO steers the LLM to capture the invariant structure shared across correct reasoning paths. This provides a more robust cross-trajectory regularization than the original single-path supervision in RLVR, effectively mitigating step-level reasoning inconsistencies and suppressing hallucinatory artifacts. In experiments, CLIPO consistently improves multiple RLVR baselines across diverse reasoning benchmarks, demonstrating uniform improvements in generalization and robustness for policy optimization of LLMs. Our code and training recipes are available at https://github.com/Qwen-Applications/CLIPO.
A Unified Representation Underlying the Judgment of Large Language Models
Oct 31, 2025A central architectural question for both biological and artificial intelligence is whether judgment relies on specialized modules or a unified, domain-general resource. While the discovery of decodable neural representations for distinct concepts in Large Language Models (LLMs) has suggested a modular architecture, whether these representations are truly independent systems remains an open question. Here we provide evidence for a convergent architecture. Across a range of LLMs, we find that diverse evaluative judgments are computed along a dominant dimension, which we term the Valence-Assent Axis (VAA). This axis jointly encodes subjective valence ("what is good") and the model's assent to factual claims ("what is true"). Through direct interventions, we show this unified representation creates a critical dependency: the VAA functions as a control signal that steers the generative process to construct a rationale consistent with its evaluative state, even at the cost of factual accuracy. This mechanism, which we term the subordination of reasoning, shifts the process of reasoning from impartial inference toward goal-directed justification. Our discovery offers a mechanistic account for systemic bias and hallucination, revealing how an architecture that promotes coherent judgment can systematically undermine faithful reasoning.
VARMA-Enhanced Transformer for Time Series Forecasting
Sep 05, 2025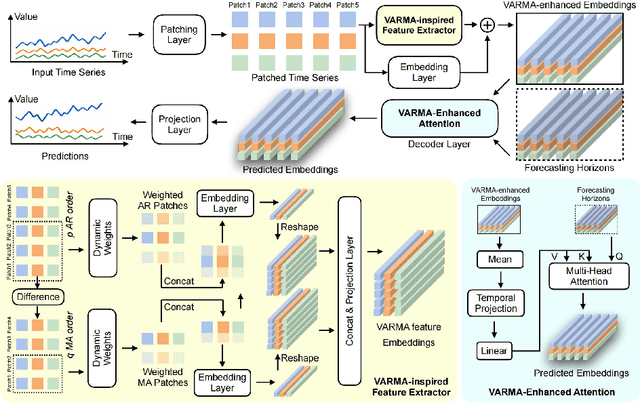
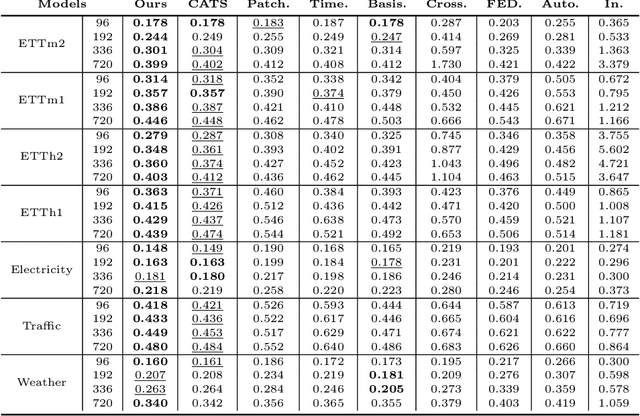
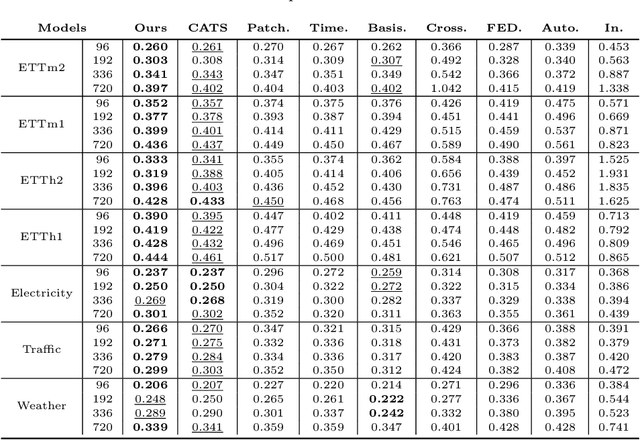
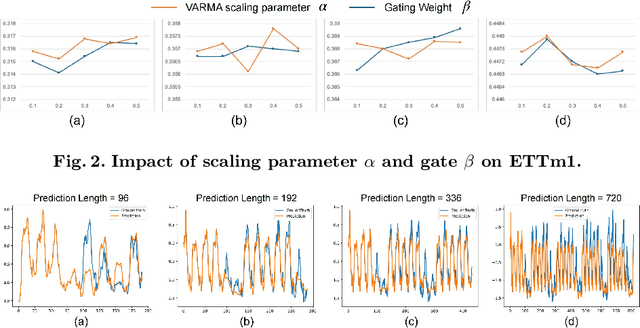
Transformer-based models have significantly advanced time series forecasting. Recent work, like the Cross-Attention-only Time Series transformer (CATS), shows that removing self-attention can make the model more accurate and efficient. However, these streamlined architectures may overlook the fine-grained, local temporal dependencies effectively captured by classical statistical models like Vector AutoRegressive Moving Average model (VARMA). To address this gap, we propose VARMAformer, a novel architecture that synergizes the efficiency of a cross-attention-only framework with the principles of classical time series analysis. Our model introduces two key innovations: (1) a dedicated VARMA-inspired Feature Extractor (VFE) that explicitly models autoregressive (AR) and moving-average (MA) patterns at the patch level, and (2) a VARMA-Enhanced Attention (VE-atten) mechanism that employs a temporal gate to make queries more context-aware. By fusing these classical insights into a modern backbone, VARMAformer captures both global, long-range dependencies and local, statistical structures. Through extensive experiments on widely-used benchmark datasets, we demonstrate that our model consistently outperforms existing state-of-the-art methods. Our work validates the significant benefit of integrating classical statistical insights into modern deep learning frameworks for time series forecasting.
SalientFusion: Context-Aware Compositional Zero-Shot Food Recognition
Sep 04, 2025Food recognition has gained significant attention, but the rapid emergence of new dishes requires methods for recognizing unseen food categories, motivating Zero-Shot Food Learning (ZSFL). We propose the task of Compositional Zero-Shot Food Recognition (CZSFR), where cuisines and ingredients naturally align with attributes and objects in Compositional Zero-Shot learning (CZSL). However, CZSFR faces three challenges: (1) Redundant background information distracts models from learning meaningful food features, (2) Role confusion between staple and side dishes leads to misclassification, and (3) Semantic bias in a single attribute can lead to confusion of understanding. Therefore, we propose SalientFusion, a context-aware CZSFR method with two components: SalientFormer, which removes background redundancy and uses depth features to resolve role confusion; DebiasAT, which reduces the semantic bias by aligning prompts with visual features. Using our proposed benchmarks, CZSFood-90 and CZSFood-164, we show that SalientFusion achieves state-of-the-art results on these benchmarks and the most popular general datasets for the general CZSL. The code is avaliable at https://github.com/Jiajun-RUC/SalientFusion.
Mind the Gap: The Divergence Between Human and LLM-Generated Tasks
Aug 01, 2025Humans constantly generate a diverse range of tasks guided by internal motivations. While generative agents powered by large language models (LLMs) aim to simulate this complex behavior, it remains uncertain whether they operate on similar cognitive principles. To address this, we conducted a task-generation experiment comparing human responses with those of an LLM agent (GPT-4o). We find that human task generation is consistently influenced by psychological drivers, including personal values (e.g., Openness to Change) and cognitive style. Even when these psychological drivers are explicitly provided to the LLM, it fails to reflect the corresponding behavioral patterns. They produce tasks that are markedly less social, less physical, and thematically biased toward abstraction. Interestingly, while the LLM's tasks were perceived as more fun and novel, this highlights a disconnect between its linguistic proficiency and its capacity to generate human-like, embodied goals.We conclude that there is a core gap between the value-driven, embodied nature of human cognition and the statistical patterns of LLMs, highlighting the necessity of incorporating intrinsic motivation and physical grounding into the design of more human-aligned agents.
ToM-RL: Reinforcement Learning Unlocks Theory of Mind in Small LLMs
Apr 02, 2025Recent advancements in rule-based reinforcement learning (RL), applied during the post-training phase of large language models (LLMs), have significantly enhanced their capabilities in structured reasoning tasks such as mathematics and logical inference. However, the effectiveness of RL in social reasoning, particularly in Theory of Mind (ToM), the ability to infer others' mental states, remains largely unexplored. In this study, we demonstrate that RL methods effectively unlock ToM reasoning capabilities even in small-scale LLMs (0.5B to 7B parameters). Using a modest dataset comprising 3200 questions across diverse scenarios, our RL-trained 7B model achieves 84.50\% accuracy on the Hi-ToM benchmark, surpassing models like GPT-4o and DeepSeek-v3 despite significantly fewer parameters. While smaller models ($\leq$3B parameters) suffer from reasoning collapse, larger models (7B parameters) maintain stable performance through consistent belief tracking. Additionally, our RL-based models demonstrate robust generalization to higher-order, out-of-distribution ToM problems, novel textual presentations, and previously unseen datasets. These findings highlight RL's potential to enhance social cognitive reasoning, bridging the gap between structured problem-solving and nuanced social inference in LLMs.