 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023



Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Learn More for Food Recognition via Progressive Self-Distillation
Mar 09, 2023



Food recognition has a wide range of applications, such as health-aware recommendation and self-service restaurants. Most previous methods of food recognition firstly locate informative regions in some weakly-supervised manners and then aggregate their features. However, location errors of informative regions limit the effectiveness of these methods to some extent. Instead of locating multiple regions, we propose a Progressive Self-Distillation (PSD) method, which progressively enhances the ability of network to mine more details for food recognition. The training of PSD simultaneously contains multiple self-distillations, in which a teacher network and a student network share the same embedding network. Since the student network receives a modified image from its teacher network by masking some informative regions, the teacher network outputs stronger semantic representations than the student network. Guided by such teacher network with stronger semantics, the student network is encouraged to mine more useful regions from the modified image by enhancing its own ability. The ability of the teacher network is also enhanced with the shared embedding network. By using progressive training, the teacher network incrementally improves its ability to mine more discriminative regions. In inference phase, only the teacher network is used without the help of the student network. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method and state-of-the-art performance.
Rethinking Ranking-based Loss Functions: Only Penalizing Negative Instances before Positive Ones is Enough
Feb 09, 2021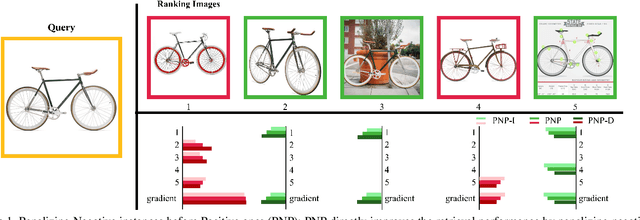
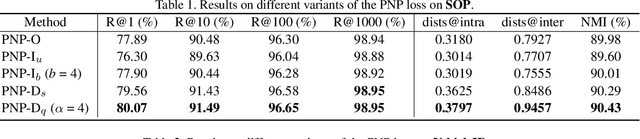
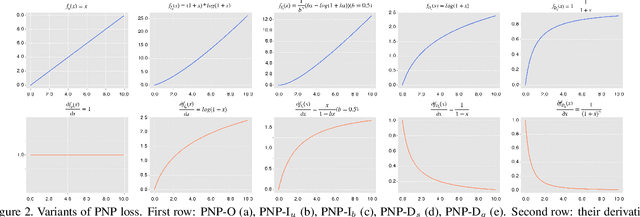
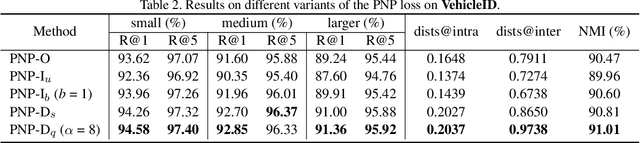
Optimising the approximation of Average Precision (AP) has been widely studied for retrieval. Such methods consider both negative and positive instances before each target positive one according to the definition of AP. However, we argue that only penalizing negative instances before positive ones is enough, because the loss only comes from them. To this end, instead of following the AP-based loss, we propose a new loss, namely Penalizing Negative instances before Positive ones (PNP), which directly minimizes the number of negative instances before each positive one. Meanwhile, limited by the definition of AP, AP-based methods only adopt a specific gradient assignment strategy. We wonder whether there exists better ones. Instead, we systematically investigate different gradient assignment solutions via constructing derivative functions of the loss, resulting in PNP-I with increasing derivative functions and PNP-D with decreasing ones. Because of their gradient assignment strategies, PNP-I tries to make all the relevant instances together, while PNP-D only quickly corrects positive one with fewer negative instances before. Thus, PNP-D may be more suitable for real-world data, which usually contains several local clusters for one class. Extensive evaluations on three standard retrieval datasets also show that PNP-D achieves the state-of-the-art performance.
Dataset Bias in Few-shot Image Recognition
Sep 07, 2020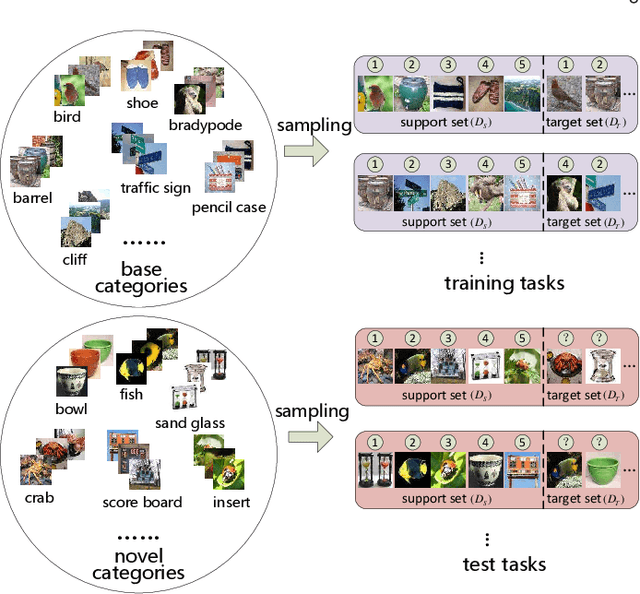

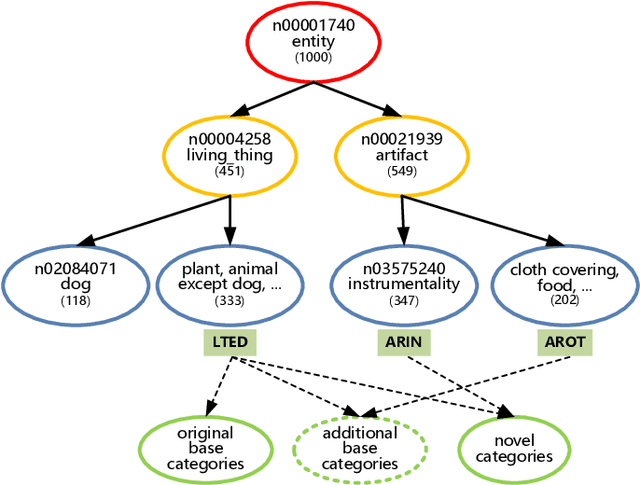

The goal of few-shot image recognition (FSIR) is to identify novel categories with a small number of annotated samples by exploiting transferable knowledge from training data (base categories). Most current studies assume that the transferable knowledge can be well used to identify novel categories. However, such transferable capability may be impacted by the dataset bias, and this problem has rarely been investigated before. Besides, most of few-shot learning methods are biased to different datasets, which is also an important issue that needs to be investigated deeply. In this paper, we first investigate the impact of transferable capabilities learned from base categories. Specifically, we use the relevance to measure relationships between base categories and novel categories. Distributions of base categories are depicted via the instance density and category diversity. The FSIR model learns better transferable knowledge from relevant training data. In the relevant data, dense instances or diverse categories can further enrich the learned knowledge. Experimental results on different sub-datasets of ImagNet demonstrate category relevance, instance density and category diversity can depict transferable bias from base categories. Second, we investigate performance differences on different datasets from dataset structures and different few-shot learning methods. Specifically, we introduce image complexity, intra-concept visual consistency, and inter-concept visual similarity to quantify characteristics of dataset structures. We use these quantitative characteristics and four few-shot learning methods to analyze performance differences on five different datasets. Based on the experimental analysis, some insightful observations are obtained from the perspective of both dataset structures and few-shot learning methods. We hope these observations are useful to guide future FSIR research.