 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Object-to-Zone Graph for Object Navigation
Sep 09, 2021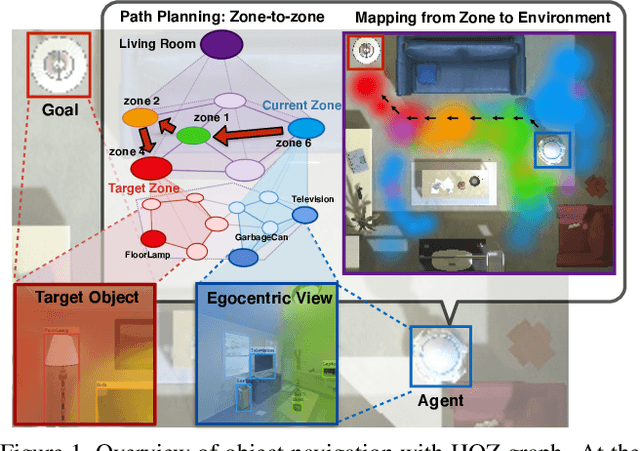
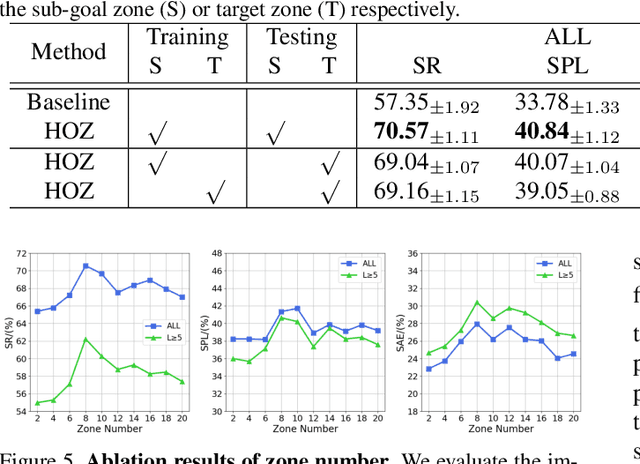
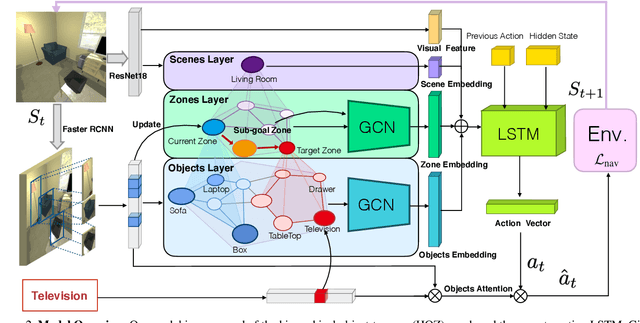
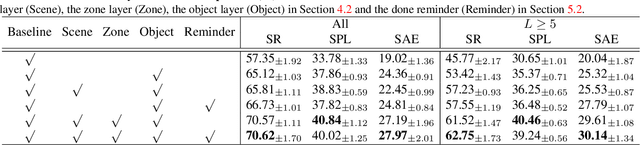
The goal of object navigation is to reach the expected objects according to visual information in the unseen environments. Previous works usually implement deep models to train an agent to predict actions in real-time. However, in the unseen environment, when the target object is not in egocentric view, the agent may not be able to make wise decisions due to the lack of guidance. In this paper, we propose a hierarchical object-to-zone (HOZ) graph to guide the agent in a coarse-to-fine manner, and an online-learning mechanism is also proposed to update HOZ according to the real-time observation in new environments. In particular, the HOZ graph is composed of scene nodes, zone nodes and object nodes. With the pre-learned HOZ graph, the real-time observation and the target goal, the agent can constantly plan an optimal path from zone to zone. In the estimated path, the next potential zone is regarded as sub-goal, which is also fed into the deep reinforcement learning model for action prediction. Our methods are evaluated on the AI2-Thor simulator. In addition to widely used evaluation metrics SR and SPL, we also propose a new evaluation metric of SAE that focuses on the effective action rate. Experimental results demonstrate the effectiveness and efficiency of our proposed method.
Dataset Bias in Few-shot Image Recognition
Sep 07, 2020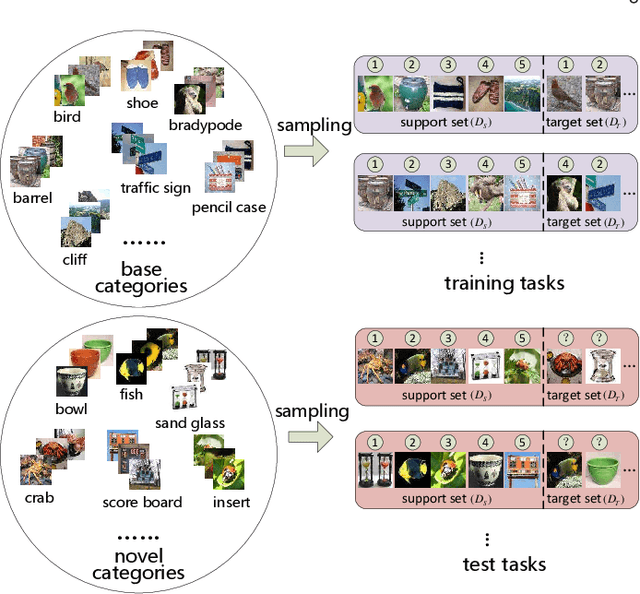

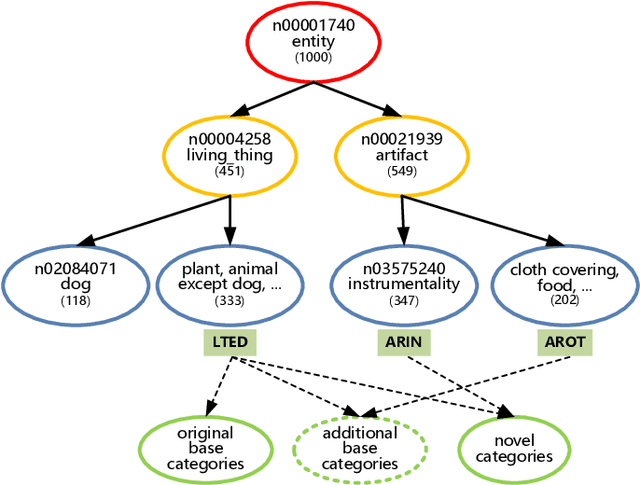

The goal of few-shot image recognition (FSIR) is to identify novel categories with a small number of annotated samples by exploiting transferable knowledge from training data (base categories). Most current studies assume that the transferable knowledge can be well used to identify novel categories. However, such transferable capability may be impacted by the dataset bias, and this problem has rarely been investigated before. Besides, most of few-shot learning methods are biased to different datasets, which is also an important issue that needs to be investigated deeply. In this paper, we first investigate the impact of transferable capabilities learned from base categories. Specifically, we use the relevance to measure relationships between base categories and novel categories. Distributions of base categories are depicted via the instance density and category diversity. The FSIR model learns better transferable knowledge from relevant training data. In the relevant data, dense instances or diverse categories can further enrich the learned knowledge. Experimental results on different sub-datasets of ImagNet demonstrate category relevance, instance density and category diversity can depict transferable bias from base categories. Second, we investigate performance differences on different datasets from dataset structures and different few-shot learning methods. Specifically, we introduce image complexity, intra-concept visual consistency, and inter-concept visual similarity to quantify characteristics of dataset structures. We use these quantitative characteristics and four few-shot learning methods to analyze performance differences on five different datasets. Based on the experimental analysis, some insightful observations are obtained from the perspective of both dataset structures and few-shot learning methods. We hope these observations are useful to guide future FSIR research.
Scene Recognition with Prototype-agnostic Scene Layout
Sep 07, 2019
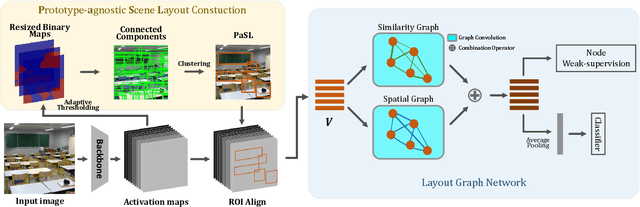

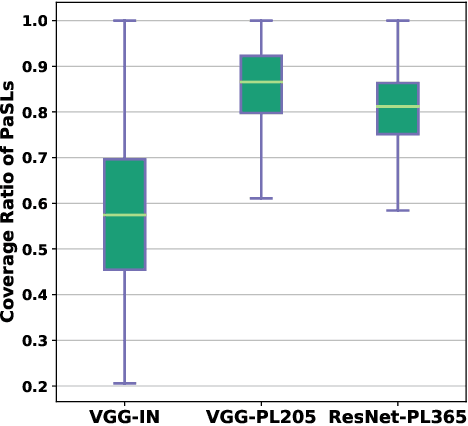
Abstract--- Exploiting the spatial structure in scene images is a key research direction for scene recognition. Due to the large intra-class structural diversity, building and modeling flexible structural layout to adapt various image characteristics is a challenge. Existing structural modeling methods in scene recognition either focus on predefined grids or rely on learned prototypes, which all have limited representative ability. In this paper, we propose Prototype-agnostic Scene Layout (PaSL) construction method to build the spatial structure for each image without conforming to any prototype. Our PaSL can flexibly capture the diverse spatial characteristic of scene images and have considerable generalization capability. Given a PaSL, we build Layout Graph Network (LGN) where regions in PaSL are defined as nodes and two kinds of independent relations between regions are encoded as edges. The LGN aims to incorporate two topological structures (formed in spatial and semantic similarity dimensions) into image representations through graph convolution. Extensive experiments show that our approach achieves state-of-the-art results on widely recognized MIT67 and SUN397 datasets without multi-model or multi-scale fusion. Moreover, we also conduct the experiments on one of the largest scale datasets, Places365. The results demonstrate the proposed method can be well generalized and obtains competitive performance.
Learning Effective RGB-D Representations for Scene Recognition
Sep 17, 2018
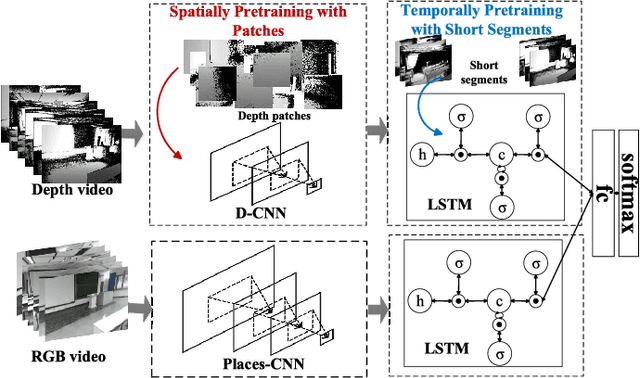
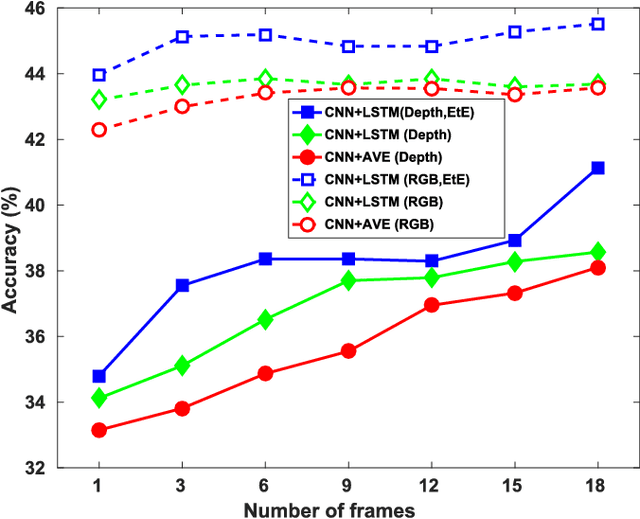
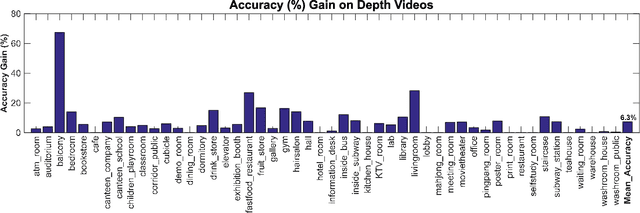
Deep convolutional networks (CNN) can achieve impressive results on RGB scene recognition thanks to large datasets such as Places. In contrast, RGB-D scene recognition is still underdeveloped in comparison, due to two limitations of RGB-D data we address in this paper. The first limitation is the lack of depth data for training deep learning models. Rather than fine tuning or transferring RGB-specific features, we address this limitation by proposing an architecture and a two-step training approach that directly learns effective depth-specific features using weak supervision via patches. The resulting RGB-D model also benefits from more complementary multimodal features. Another limitation is the short range of depth sensors (typically 0.5m to 5.5m), resulting in depth images not capturing distant objects in the scenes that RGB images can. We show that this limitation can be addressed by using RGB-D videos, where more comprehensive depth information is accumulated as the camera travels across the scene. Focusing on this scenario, we introduce the ISIA RGB-D video dataset to evaluate RGB-D scene recognition with videos. Our video recognition architecture combines convolutional and recurrent neural networks (RNNs) that are trained in three steps with increasingly complex data to learn effective features (i.e. patches, frames and sequences). Our approach obtains state-of-the-art performances on RGB-D image (NYUD2 and SUN RGB-D) and video (ISIA RGB-D) scene recognition.
* Accepted at IEEE Transactions on Image Processing
Depth CNNs for RGB-D scene recognition: learning from scratch better than transferring from RGB-CNNs
Jan 21, 2018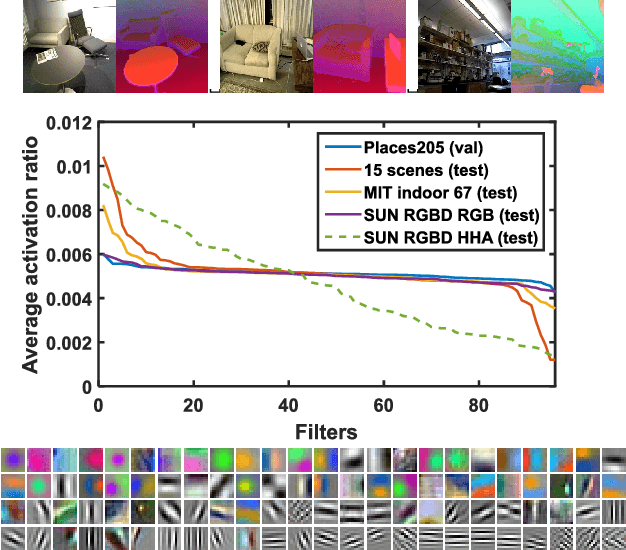
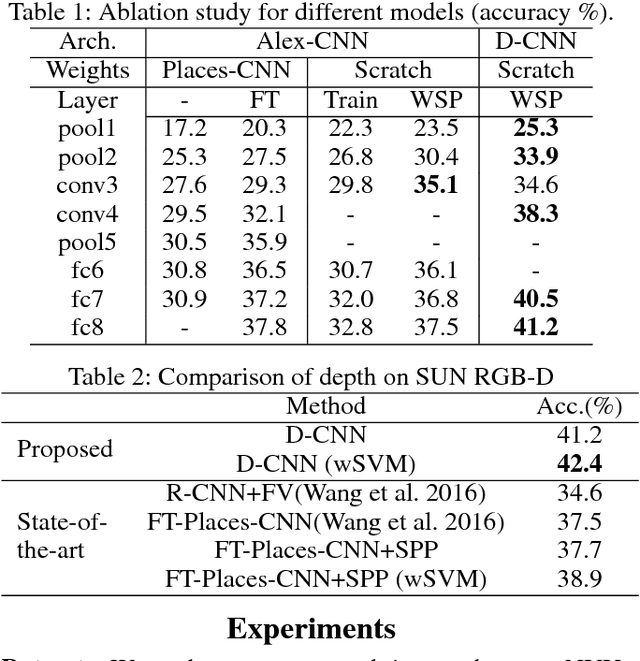
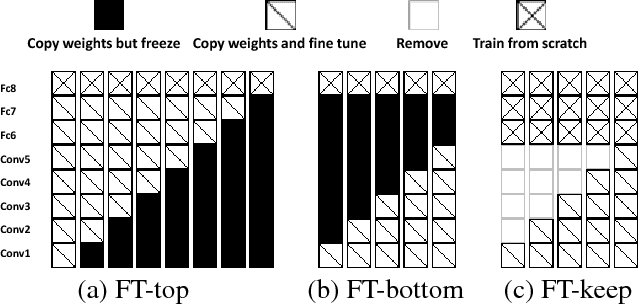
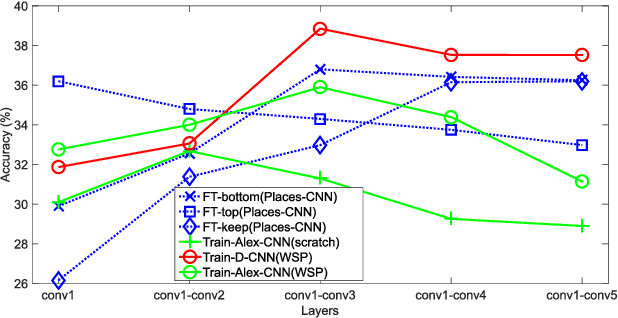
Scene recognition with RGB images has been extensively studied and has reached very remarkable recognition levels, thanks to convolutional neural networks (CNN) and large scene datasets. In contrast, current RGB-D scene data is much more limited, so often leverages RGB large datasets, by transferring pretrained RGB CNN models and fine-tuning with the target RGB-D dataset. However, we show that this approach has the limitation of hardly reaching bottom layers, which is key to learn modality-specific features. In contrast, we focus on the bottom layers, and propose an alternative strategy to learn depth features combining local weakly supervised training from patches followed by global fine tuning with images. This strategy is capable of learning very discriminative depth-specific features with limited depth images, without resorting to Places-CNN. In addition we propose a modified CNN architecture to further match the complexity of the model and the amount of data available. For RGB-D scene recognition, depth and RGB features are combined by projecting them in a common space and further leaning a multilayer classifier, which is jointly optimized in an end-to-end network. Our framework achieves state-of-the-art accuracy on NYU2 and SUN RGB-D in both depth only and combined RGB-D data.
* AAAI Conference on Artificial Intelligence 2017