 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Bias in Few-shot Image Recognition
Sep 07, 2020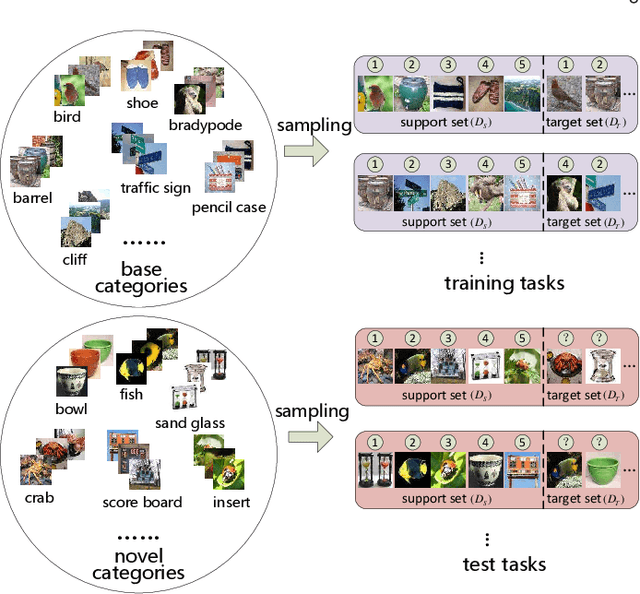

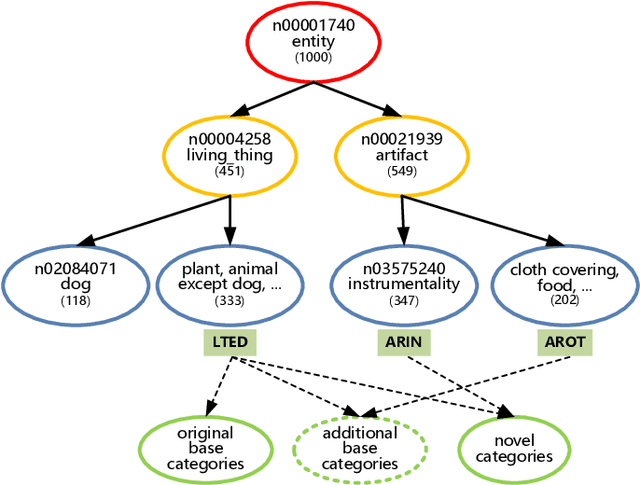

The goal of few-shot image recognition (FSIR) is to identify novel categories with a small number of annotated samples by exploiting transferable knowledge from training data (base categories). Most current studies assume that the transferable knowledge can be well used to identify novel categories. However, such transferable capability may be impacted by the dataset bias, and this problem has rarely been investigated before. Besides, most of few-shot learning methods are biased to different datasets, which is also an important issue that needs to be investigated deeply. In this paper, we first investigate the impact of transferable capabilities learned from base categories. Specifically, we use the relevance to measure relationships between base categories and novel categories. Distributions of base categories are depicted via the instance density and category diversity. The FSIR model learns better transferable knowledge from relevant training data. In the relevant data, dense instances or diverse categories can further enrich the learned knowledge. Experimental results on different sub-datasets of ImagNet demonstrate category relevance, instance density and category diversity can depict transferable bias from base categories. Second, we investigate performance differences on different datasets from dataset structures and different few-shot learning methods. Specifically, we introduce image complexity, intra-concept visual consistency, and inter-concept visual similarity to quantify characteristics of dataset structures. We use these quantitative characteristics and four few-shot learning methods to analyze performance differences on five different datasets. Based on the experimental analysis, some insightful observations are obtained from the perspective of both dataset structures and few-shot learning methods. We hope these observations are useful to guide future FSIR research.