 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
SentGraph: Hierarchical Sentence Graph for Multi-hop Retrieval-Augmented Question Answering
Jan 06, 2026Traditional Retrieval-Augmented Generation (RAG) effectively supports single-hop question answering with large language models but faces significant limitations in multi-hop question answering tasks, which require combining evidence from multiple documents. Existing chunk-based retrieval often provides irrelevant and logically incoherent context, leading to incomplete evidence chains and incorrect reasoning during answer generation. To address these challenges, we propose SentGraph, a sentence-level graph-based RAG framework that explicitly models fine-grained logical relationships between sentences for multi-hop question answering. Specifically, we construct a hierarchical sentence graph offline by first adapting Rhetorical Structure Theory to distinguish nucleus and satellite sentences, and then organizing them into topic-level subgraphs with cross-document entity bridges. During online retrieval, SentGraph performs graph-guided evidence selection and path expansion to retrieve fine-grained sentence-level evidence. Extensive experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of SentGraph, validating the importance of explicitly modeling sentence-level logical dependencies for multi-hop reasoning.
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Nov 12, 2025
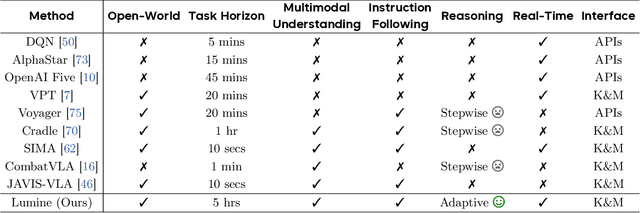


We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-language model. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.
Humanity's Last Code Exam: Can Advanced LLMs Conquer Human's Hardest Code Competition?
Jun 15, 2025Code generation is a core capability of large language models (LLMs), yet mainstream benchmarks (e.g., APPs and LiveCodeBench) contain questions with medium-level difficulty and pose no challenge to advanced LLMs. To better reflected the advanced reasoning and code generation ability, We introduce Humanity's Last Code Exam (HLCE), comprising 235 most challenging problems from the International Collegiate Programming Contest (ICPC World Finals) and the International Olympiad in Informatics (IOI) spanning 2010 - 2024. As part of HLCE, we design a harmonized online-offline sandbox that guarantees fully reproducible evaluation. Through our comprehensive evaluation, we observe that even the strongest reasoning LLMs: o4-mini(high) and Gemini-2.5 Pro, achieve pass@1 rates of only 15.9% and 11.4%, respectively. Meanwhile, we propose a novel "self-recognition" task to measure LLMs' awareness of their own capabilities. Results indicate that LLMs' self-recognition abilities are not proportionally correlated with their code generation performance. Finally, our empirical validation of test-time scaling laws reveals that current advanced LLMs have substantial room for improvement on complex programming tasks. We expect HLCE to become a milestone challenge for code generation and to catalyze advances in high-performance reasoning and human-AI collaborative programming. Our code and dataset are also public available(https://github.com/Humanity-s-Last-Code-Exam/HLCE).
CrossLinear: Plug-and-Play Cross-Correlation Embedding for Time Series Forecasting with Exogenous Variables
May 29, 2025Time series forecasting with exogenous variables is a critical emerging paradigm that presents unique challenges in modeling dependencies between variables. Traditional models often struggle to differentiate between endogenous and exogenous variables, leading to inefficiencies and overfitting. In this paper, we introduce CrossLinear, a novel Linear-based forecasting model that addresses these challenges by incorporating a plug-and-play cross-correlation embedding module. This lightweight module captures the dependencies between variables with minimal computational cost and seamlessly integrates into existing neural networks. Specifically, it captures time-invariant and direct variable dependencies while disregarding time-varying or indirect dependencies, thereby mitigating the risk of overfitting in dependency modeling and contributing to consistent performance improvements. Furthermore, CrossLinear employs patch-wise processing and a global linear head to effectively capture both short-term and long-term temporal dependencies, further improving its forecasting precision. Extensive experiments on 12 real-world datasets demonstrate that CrossLinear achieves superior performance in both short-term and long-term forecasting tasks. The ablation study underscores the effectiveness of the cross-correlation embedding module. Additionally, the generalizability of this module makes it a valuable plug-in for various forecasting tasks across different domains. Codes are available at https://github.com/mumiao2000/CrossLinear.
Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning
May 20, 2025Retrieval-augmented generation (RAG) enhances the text generation capabilities of large language models (LLMs) by integrating external knowledge and up-to-date information. However, traditional RAG systems are limited by static workflows and lack the adaptability required for multistep reasoning and complex task management. To address these limitations, agentic RAG systems (e.g., DeepResearch) have been proposed, enabling dynamic retrieval strategies, iterative context refinement, and adaptive workflows for handling complex search queries beyond the capabilities of conventional RAG. Recent advances, such as Search-R1, have demonstrated promising gains using outcome-based reinforcement learning, where the correctness of the final answer serves as the reward signal. Nevertheless, such outcome-supervised agentic RAG methods face challenges including low exploration efficiency, gradient conflict, and sparse reward signals. To overcome these challenges, we propose to utilize fine-grained, process-level rewards to improve training stability, reduce computational costs, and enhance efficiency. Specifically, we introduce a novel method ReasonRAG that automatically constructs RAG-ProGuide, a high-quality dataset providing process-level rewards for (i) query generation, (ii) evidence extraction, and (iii) answer generation, thereby enhancing model inherent capabilities via process-supervised reinforcement learning. With the process-level policy optimization, the proposed framework empowers LLMs to autonomously invoke search, generate queries, extract relevant evidence, and produce final answers. Compared to existing approaches such as Search-R1 and traditional RAG systems, ReasonRAG, leveraging RAG-ProGuide, achieves superior performance on five benchmark datasets using only 5k training instances, significantly fewer than the 90k training instances required by Search-R1.
A Survey of Personalization: From RAG to Agent
Apr 14, 2025Personalization has become an essential capability in modern AI systems, enabling customized interactions that align with individual user preferences, contexts, and goals. Recent research has increasingly concentrated on Retrieval-Augmented Generation (RAG) frameworks and their evolution into more advanced agent-based architectures within personalized settings to enhance user satisfaction. Building on this foundation, this survey systematically examines personalization across the three core stages of RAG: pre-retrieval, retrieval, and generation. Beyond RAG, we further extend its capabilities into the realm of Personalized LLM-based Agents, which enhance traditional RAG systems with agentic functionalities, including user understanding, personalized planning and execution, and dynamic generation. For both personalization in RAG and agent-based personalization, we provide formal definitions, conduct a comprehensive review of recent literature, and summarize key datasets and evaluation metrics. Additionally, we discuss fundamental challenges, limitations, and promising research directions in this evolving field. Relevant papers and resources are continuously updated at https://github.com/Applied-Machine-Learning-Lab/Awesome-Personalized-RAG-Agent.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025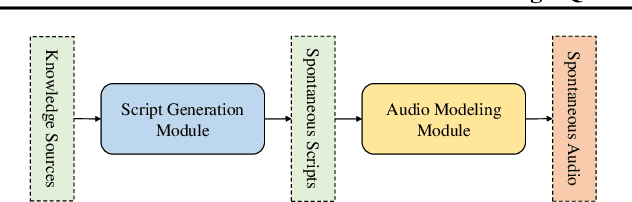


Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
Purest Quantum State Identification
Feb 20, 2025
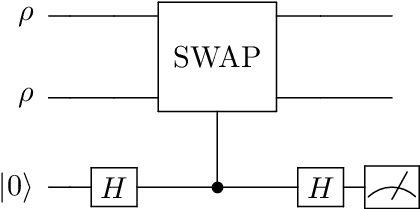
Precise identification of quantum states under noise constraints is essential for quantum information processing. In this study, we generalize the classical best arm identification problem to quantum domains, designing methods for identifying the purest one within $K$ unknown $n$-qubit quantum states using $N$ samples. %, with direct applications in quantum computation and quantum communication. We propose two distinct algorithms: (1) an algorithm employing incoherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_1}{\log(K) 2^n }\right) \right)$, and (2) an algorithm utilizing coherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_2}{\log(K) }\right) \right)$, highlighting the power of quantum memory. Furthermore, we establish a lower bound by proving that all strategies with fixed two-outcome incoherent POVM must suffer error probability exceeding $ \exp\left( - O\left(\frac{NH_1}{2^n}\right)\right)$. This framework provides concrete design principles for overcoming sampling bottlenecks in quantum technologies.
KnowPath: Knowledge-enhanced Reasoning via LLM-generated Inference Paths over Knowledge Graphs
Feb 17, 2025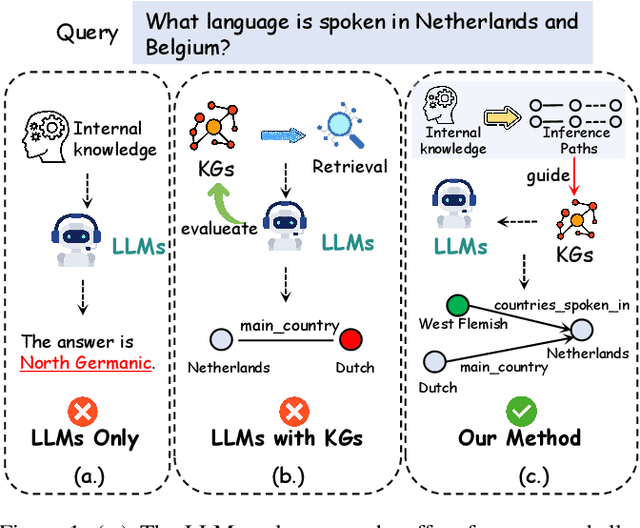
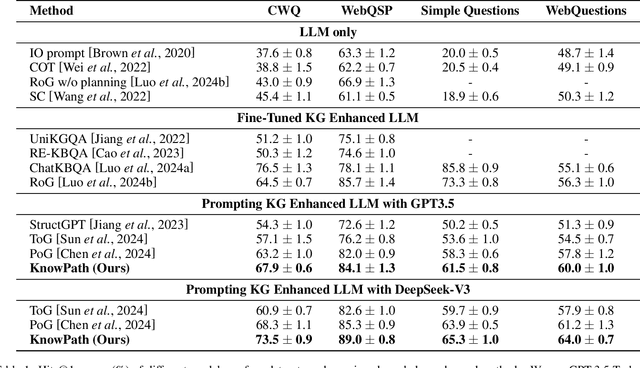
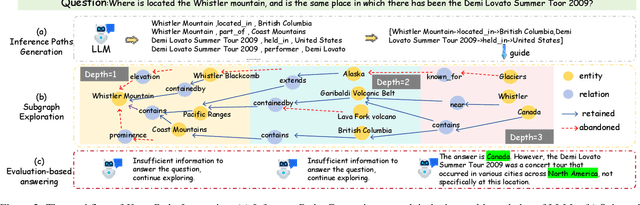
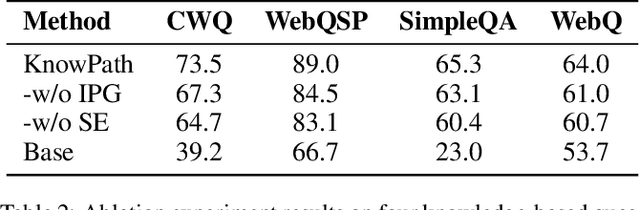
Large language models (LLMs) have demonstrated remarkable capabilities in various complex tasks, yet they still suffer from hallucinations. Introducing external knowledge, such as knowledge graph, can enhance the LLMs' ability to provide factual answers. LLMs have the ability to interactively explore knowledge graphs. However, most approaches have been affected by insufficient internal knowledge excavation in LLMs, limited generation of trustworthy knowledge reasoning paths, and a vague integration between internal and external knowledge. Therefore, we propose KnowPath, a knowledge-enhanced large model framework driven by the collaboration of internal and external knowledge. It relies on the internal knowledge of the LLM to guide the exploration of interpretable directed subgraphs in external knowledge graphs, better integrating the two knowledge sources for more accurate reasoning. Extensive experiments on multiple real-world datasets confirm the superiority of KnowPath.