 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowPath: Knowledge-enhanced Reasoning via LLM-generated Inference Paths over Knowledge Graphs
Feb 17, 2025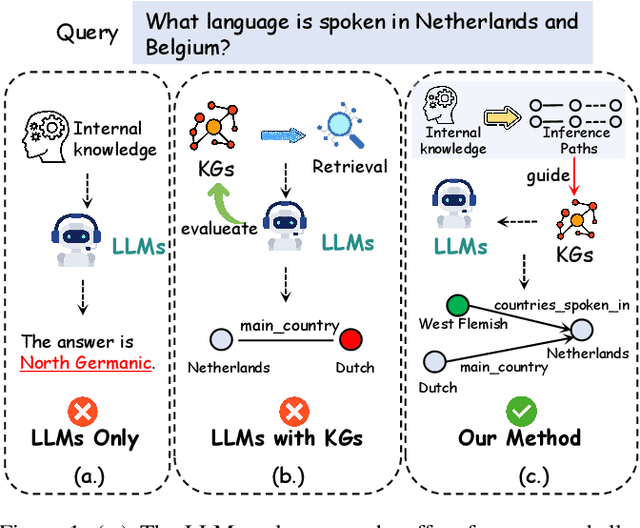
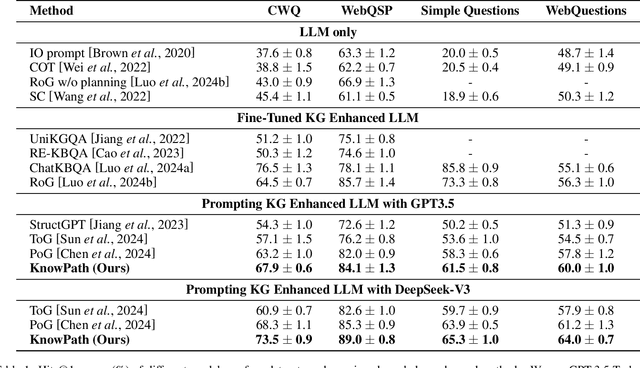
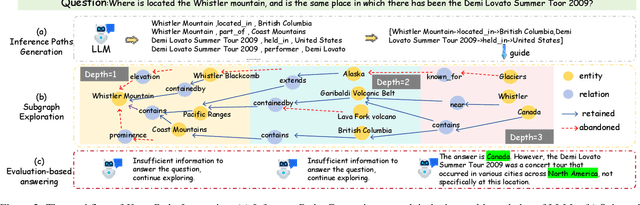
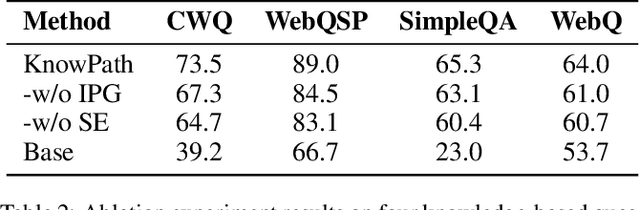
Large language models (LLMs) have demonstrated remarkable capabilities in various complex tasks, yet they still suffer from hallucinations. Introducing external knowledge, such as knowledge graph, can enhance the LLMs' ability to provide factual answers. LLMs have the ability to interactively explore knowledge graphs. However, most approaches have been affected by insufficient internal knowledge excavation in LLMs, limited generation of trustworthy knowledge reasoning paths, and a vague integration between internal and external knowledge. Therefore, we propose KnowPath, a knowledge-enhanced large model framework driven by the collaboration of internal and external knowledge. It relies on the internal knowledge of the LLM to guide the exploration of interpretable directed subgraphs in external knowledge graphs, better integrating the two knowledge sources for more accurate reasoning. Extensive experiments on multiple real-world datasets confirm the superiority of KnowPath.
Multi-Grained Preference Enhanced Transformer for Multi-Behavior Sequential Recommendation
Nov 19, 2024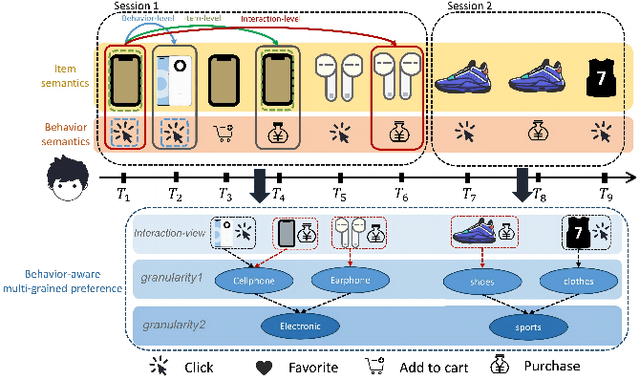
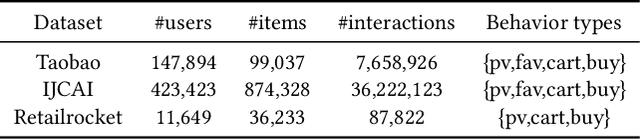
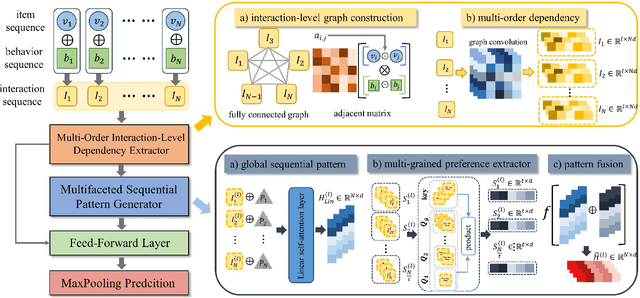
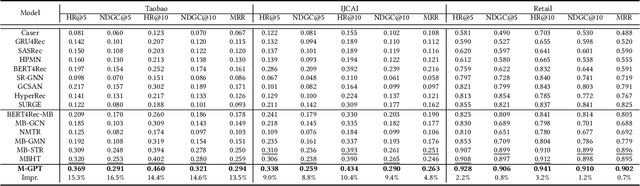
Sequential recommendation (SR) aims to predict the next purchasing item according to users' dynamic preference learned from their historical user-item interactions. To improve the performance of recommendation, learning dynamic heterogeneous cross-type behavior dependencies is indispensable for recommender system. However, there still exists some challenges in Multi-Behavior Sequential Recommendation (MBSR). On the one hand, existing methods only model heterogeneous multi-behavior dependencies at behavior-level or item-level, and modelling interaction-level dependencies is still a challenge. On the other hand, the dynamic multi-grained behavior-aware preference is hard to capture in interaction sequences, which reflects interaction-aware sequential pattern. To tackle these challenges, we propose a Multi-Grained Preference enhanced Transformer framework (M-GPT). First, M-GPT constructs a interaction-level graph of historical cross-typed interactions in a sequence. Then graph convolution is performed to derive interaction-level multi-behavior dependency representation repeatedly, in which the complex correlation between historical cross-typed interactions at specific orders can be well learned. Secondly, a novel multi-scale transformer architecture equipped with multi-grained user preference extraction is proposed to encode the interaction-aware sequential pattern enhanced by capturing temporal behavior-aware multi-grained preference . Experiments on the real-world datasets indicate that our method M-GPT consistently outperforms various state-of-the-art recommendation methods.
Iterative Text-based Editing of Talking-heads Using Neural Retargeting
Nov 21, 2020

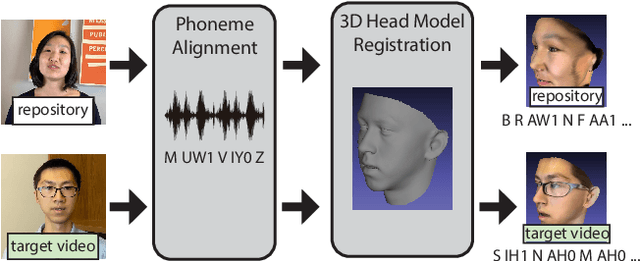

We present a text-based tool for editing talking-head video that enables an iterative editing workflow. On each iteration users can edit the wording of the speech, further refine mouth motions if necessary to reduce artifacts and manipulate non-verbal aspects of the performance by inserting mouth gestures (e.g. a smile) or changing the overall performance style (e.g. energetic, mumble). Our tool requires only 2-3 minutes of the target actor video and it synthesizes the video for each iteration in about 40 seconds, allowing users to quickly explore many editing possibilities as they iterate. Our approach is based on two key ideas. (1) We develop a fast phoneme search algorithm that can quickly identify phoneme-level subsequences of the source repository video that best match a desired edit. This enables our fast iteration loop. (2) We leverage a large repository of video of a source actor and develop a new self-supervised neural retargeting technique for transferring the mouth motions of the source actor to the target actor. This allows us to work with relatively short target actor videos, making our approach applicable in many real-world editing scenarios. Finally, our refinement and performance controls give users the ability to further fine-tune the synthesized results.
Rekall: Specifying Video Events using Compositions of Spatiotemporal Labels
Oct 07, 2019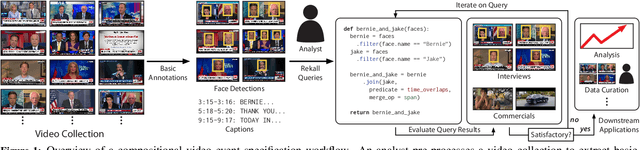
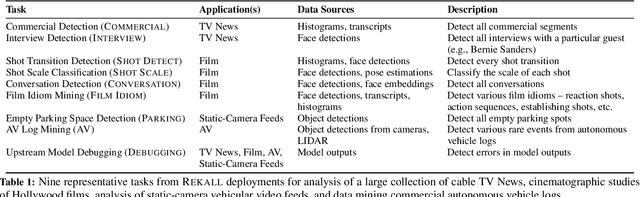
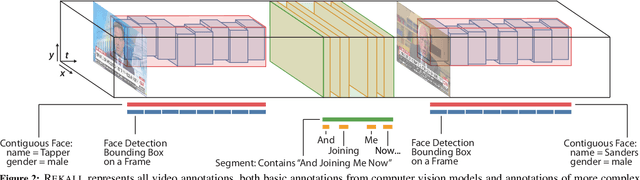

Many real-world video analysis applications require the ability to identify domain-specific events in video, such as interviews and commercials in TV news broadcasts, or action sequences in film. Unfortunately, pre-trained models to detect all the events of interest in video may not exist, and training new models from scratch can be costly and labor-intensive. In this paper, we explore the utility of specifying new events in video in a more traditional manner: by writing queries that compose outputs of existing, pre-trained models. To write these queries, we have developed Rekall, a library that exposes a data model and programming model for compositional video event specification. Rekall represents video annotations from different sources (object detectors, transcripts, etc.) as spatiotemporal labels associated with continuous volumes of spacetime in a video, and provides operators for composing labels into queries that model new video events. We demonstrate the use of Rekall in analyzing video from cable TV news broadcasts, films, static-camera vehicular video streams, and commercial autonomous vehicle logs. In these efforts, domain experts were able to quickly (in a few hours to a day) author queries that enabled the accurate detection of new events (on par with, and in some cases much more accurate than, learned approaches) and to rapidly retrieve video clips for human-in-the-loop tasks such as video content curation and training data curation. Finally, in a user study, novice users of Rekall were able to author queries to retrieve new events in video given just one hour of query development time.
Deep Energies for Estimating Three-Dimensional Facial Pose and Expression
Dec 07, 2018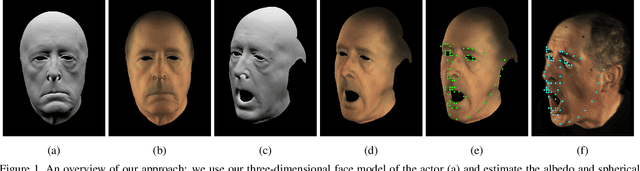


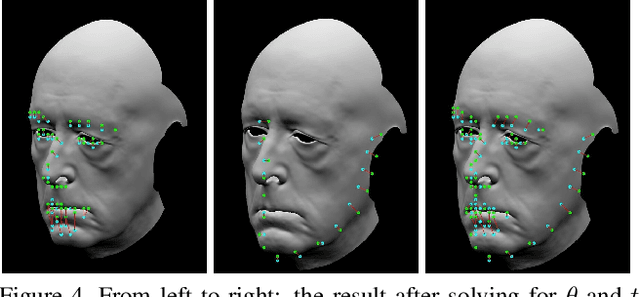
While much progress has been made in capturing high-quality facial performances using motion capture markers and shape-from-shading, high-end systems typically also rely on rotoscope curves hand-drawn on the image. These curves are subjective and difficult to draw consistently; moreover, ad-hoc procedural methods are required for generating matching rotoscope curves on synthetic renders embedded in the optimization used to determine three-dimensional facial pose and expression. We propose an alternative approach whereby these curves and other keypoints are detected automatically on both the image and the synthetic renders using trained neural networks, eliminating artist subjectivity and the ad-hoc procedures meant to mimic it. More generally, we propose using machine learning networks to implicitly define deep energies which when minimized using classical optimization techniques lead to three-dimensional facial pose and expression estimation.