 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025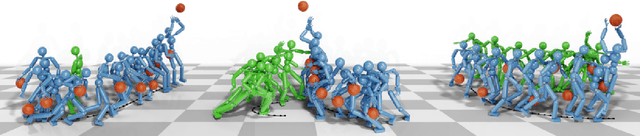

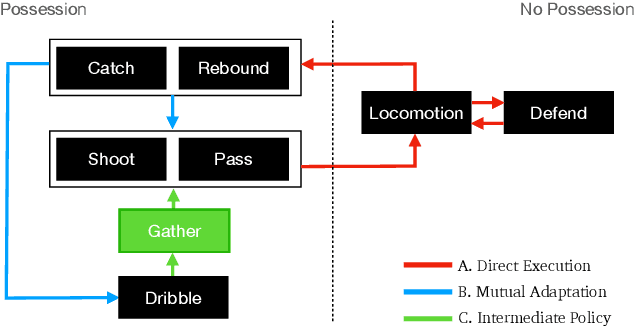

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
Self-Generated In-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
May 02, 2025Many methods for improving Large Language Model (LLM) agents for sequential decision-making tasks depend on task-specific knowledge engineering--such as prompt tuning, curated in-context examples, or customized observation and action spaces. Using these approaches, agent performance improves with the quality or amount of knowledge engineering invested. Instead, we investigate how LLM agents can automatically improve their performance by learning in-context from their own successful experiences on similar tasks. Rather than relying on task-specific knowledge engineering, we focus on constructing and refining a database of self-generated examples. We demonstrate that even a naive accumulation of successful trajectories across training tasks boosts test performance on three benchmarks: ALFWorld (73% to 89%), Wordcraft (55% to 64%), and InterCode-SQL (75% to 79%)--matching the performance the initial agent achieves if allowed two to three attempts per task. We then introduce two extensions: (1) database-level selection through population-based training to identify high-performing example collections, and (2) exemplar-level selection that retains individual trajectories based on their empirical utility as in-context examples. These extensions further enhance performance, achieving 91% on ALFWorld--matching more complex approaches that employ task-specific components and prompts. Our results demonstrate that automatic trajectory database construction offers a compelling alternative to labor-intensive knowledge engineering.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Generative Motion Infilling From Imprecisely Timed Keyframes
Mar 02, 2025

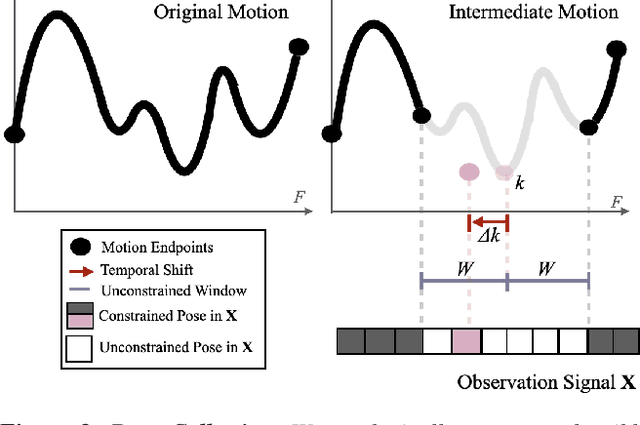

Keyframes are a standard representation for kinematic motion specification. Recent learned motion-inbetweening methods use keyframes as a way to control generative motion models, and are trained to generate life-like motion that matches the exact poses and timings of input keyframes. However, the quality of generated motion may degrade if the timing of these constraints is not perfectly consistent with the desired motion. Unfortunately, correctly specifying keyframe timings is a tedious and challenging task in practice. Our goal is to create a system that synthesizes high-quality motion from keyframes, even if keyframes are imprecisely timed. We present a method that allows constraints to be retimed as part of the generation process. Specifically, we introduce a novel model architecture that explicitly outputs a time-warping function to correct mistimed keyframes, and spatial residuals that add pose details. We demonstrate how our method can automatically turn approximately timed keyframe constraints into diverse, realistic motions with plausible timing and detailed submovements.
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Nov 05, 2024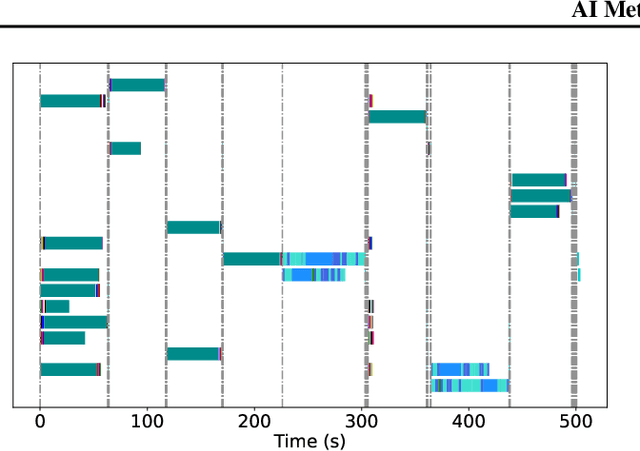
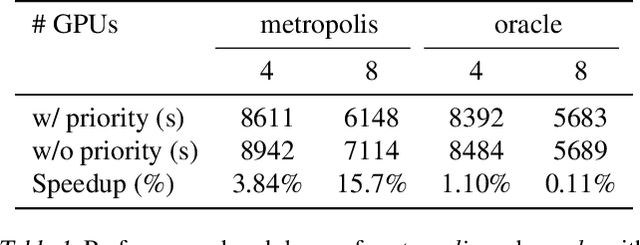
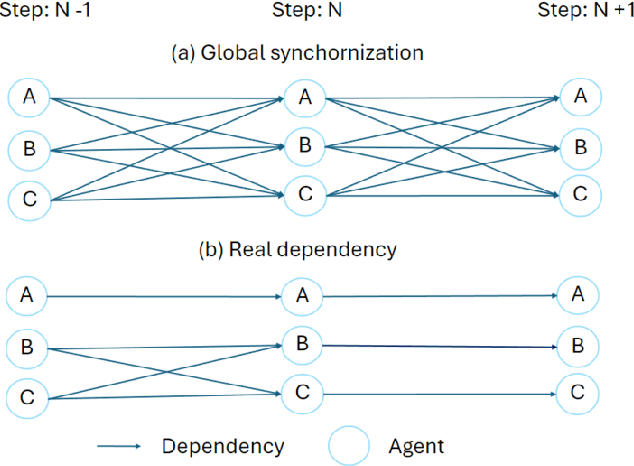
With more advanced natural language understanding and reasoning capabilities, large language model (LLM)-powered agents are increasingly developed in simulated environments to perform complex tasks, interact with other agents, and exhibit emergent behaviors relevant to social science and gaming. However, current multi-agent simulations frequently suffer from inefficiencies due to the limited parallelism caused by false dependencies, resulting in performance bottlenecks. In this paper, we introduce AI Metropolis, a simulation engine that improves the efficiency of LLM agent simulations by incorporating out-of-order execution scheduling. By dynamically tracking real dependencies between agents, AI Metropolis minimizes false dependencies, enhancing parallelism and enabling efficient hardware utilization. Our evaluations demonstrate that AI Metropolis achieves speedups from 1.3x to 4.15x over standard parallel simulation with global synchronization, approaching optimal performance as the number of agents increases.
Automated Rewards via LLM-Generated Progress Functions
Oct 11, 2024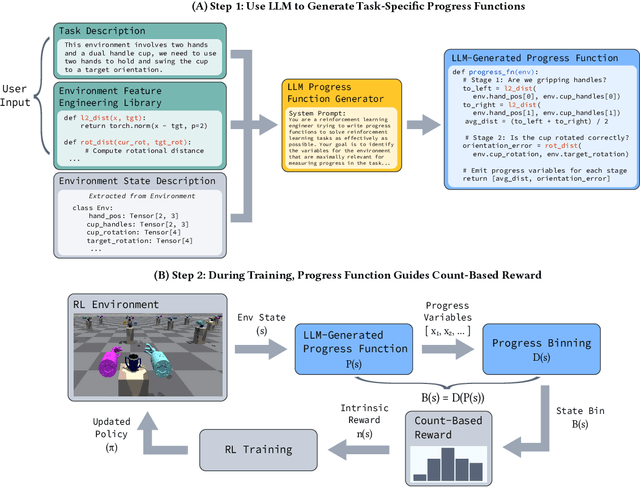
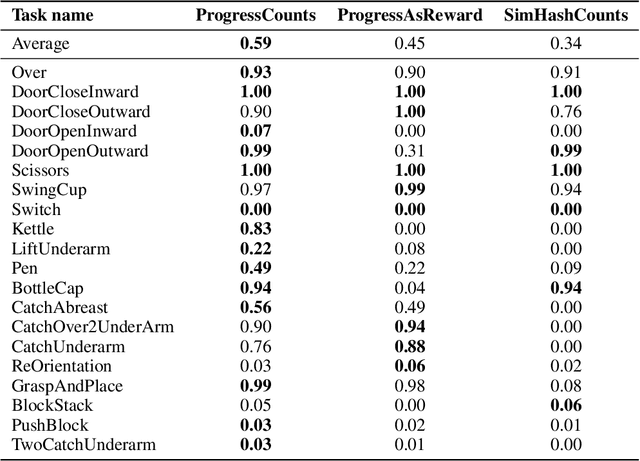
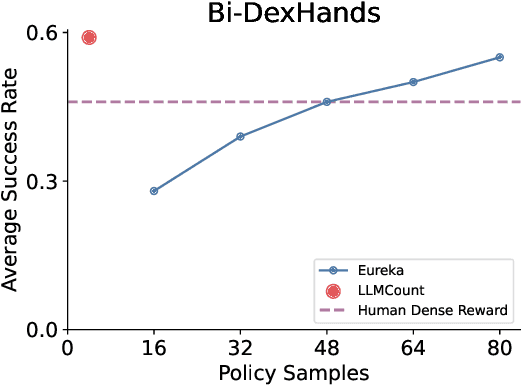

Large Language Models (LLMs) have the potential to automate reward engineering by leveraging their broad domain knowledge across various tasks. However, they often need many iterations of trial-and-error to generate effective reward functions. This process is costly because evaluating every sampled reward function requires completing the full policy optimization process for each function. In this paper, we introduce an LLM-driven reward generation framework that is able to produce state-of-the-art policies on the challenging Bi-DexHands benchmark \textbf{with 20$\times$ fewer reward function samples} than the prior state-of-the-art work. Our key insight is that we reduce the problem of generating task-specific rewards to the problem of coarsely estimating \emph{task progress}. Our two-step solution leverages the task domain knowledge and the code synthesis abilities of LLMs to author \emph{progress functions} that estimate task progress from a given state. Then, we use this notion of progress to discretize states, and generate count-based intrinsic rewards using the low-dimensional state space. We show that the combination of LLM-generated progress functions and count-based intrinsic rewards is essential for our performance gains, while alternatives such as generic hash-based counts or using progress directly as a reward function fall short.
Learning to Move Like Professional Counter-Strike Players
Aug 25, 2024
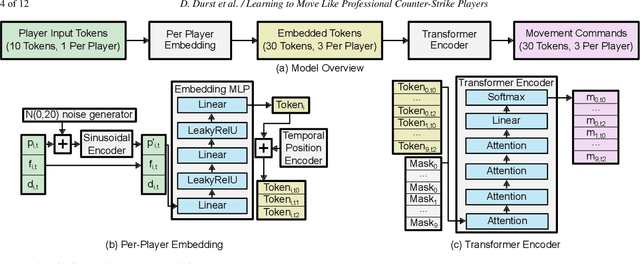
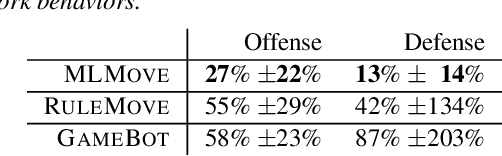
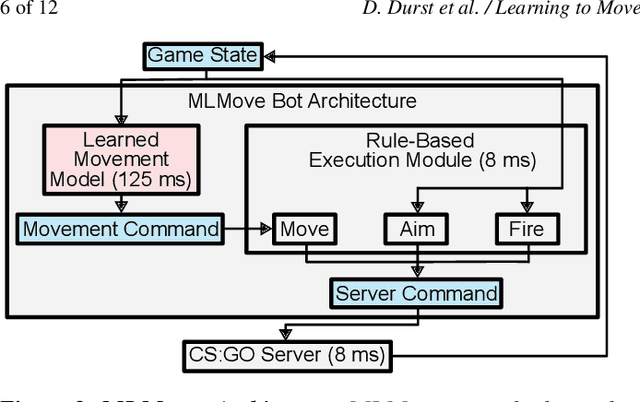
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
Block and Detail: Scaffolding Sketch-to-Image Generation
Feb 28, 2024We introduce a novel sketch-to-image tool that aligns with the iterative refinement process of artists. Our tool lets users sketch blocking strokes to coarsely represent the placement and form of objects and detail strokes to refine their shape and silhouettes. We develop a two-pass algorithm for generating high-fidelity images from such sketches at any point in the iterative process. In the first pass we use a ControlNet to generate an image that strictly follows all the strokes (blocking and detail) and in the second pass we add variation by renoising regions surrounding blocking strokes. We also present a dataset generation scheme that, when used to train a ControlNet architecture, allows regions that do not contain strokes to be interpreted as not-yet-specified regions rather than empty space. We show that this partial-sketch-aware ControlNet can generate coherent elements from partial sketches that only contain a small number of strokes. The high-fidelity images produced by our approach serve as scaffolds that can help the user adjust the shape and proportions of objects or add additional elements to the composition. We demonstrate the effectiveness of our approach with a variety of examples and evaluative comparisons.
Learning Subject-Aware Cropping by Outpainting Professional Photos
Dec 19, 2023



How to frame (or crop) a photo often depends on the image subject and its context; e.g., a human portrait. Recent works have defined the subject-aware image cropping task as a nuanced and practical version of image cropping. We propose a weakly-supervised approach (GenCrop) to learn what makes a high-quality, subject-aware crop from professional stock images. Unlike supervised prior work, GenCrop requires no new manual annotations beyond the existing stock image collection. The key challenge in learning from this data, however, is that the images are already cropped and we do not know what regions were removed. Our insight is combine a library of stock images with a modern, pre-trained text-to-image diffusion model. The stock image collection provides diversity and its images serve as pseudo-labels for a good crop, while the text-image diffusion model is used to out-paint (i.e., outward inpainting) realistic uncropped images. Using this procedure, we are able to automatically generate a large dataset of cropped-uncropped training pairs to train a cropping model. Despite being weakly-supervised, GenCrop is competitive with state-of-the-art supervised methods and significantly better than comparable weakly-supervised baselines on quantitative and qualitative evaluation metrics.
Iterative Motion Editing with Natural Language
Dec 15, 2023



Text-to-motion diffusion models can generate realistic animations from text prompts, but do not support fine-grained motion editing controls. In this paper we present a method for using natural language to iteratively specify local edits to existing character animations, a task that is common in most computer animation workflows. Our key idea is to represent a space of motion edits using a set of kinematic motion operators that have well-defined semantics for how to modify specific frames of a target motion. We provide an algorithm that leverages pre-existing language models to translate textual descriptions of motion edits to sequences of motion editing operators (MEOs). Given new keyframes produced by the MEOs, we use diffusion-based keyframe interpolation to generate final motions. Through a user study and quantitative evaluation, we demonstrate that our system can perform motion edits that respect the animator's editing intent, remain faithful to the original animation (they edit the original animation, not dramatically change it), and yield realistic character animation results.