 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Group Inference for Diverse and High-Quality Generation
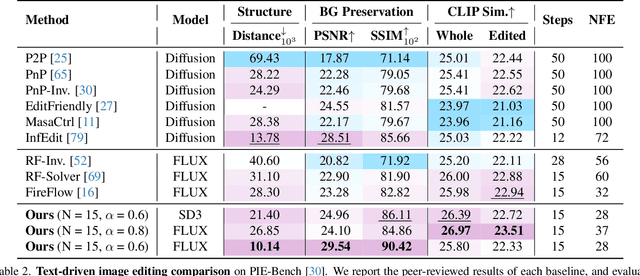
Aug 21, 2025Generative models typically sample outputs independently, and recent inference-time guidance and scaling algorithms focus on improving the quality of individual samples. However, in real-world applications, users are often presented with a set of multiple images (e.g., 4-8) for each prompt, where independent sampling tends to lead to redundant results, limiting user choices and hindering idea exploration. In this work, we introduce a scalable group inference method that improves both the diversity and quality of a group of samples. We formulate group inference as a quadratic integer assignment problem: candidate outputs are modeled as graph nodes, and a subset is selected to optimize sample quality (unary term) while maximizing group diversity (binary term). To substantially improve runtime efficiency, we progressively prune the candidate set using intermediate predictions, allowing our method to scale up to large candidate sets. Extensive experiments show that our method significantly improves group diversity and quality compared to independent sampling baselines and recent inference algorithms. Our framework generalizes across a wide range of tasks, including text-to-image, image-to-image, image prompting, and video generation, enabling generative models to treat multiple outputs as cohesive groups rather than independent samples.
UniEdit-Flow: Unleashing Inversion and Editing in the Era of Flow Models
Apr 17, 2025

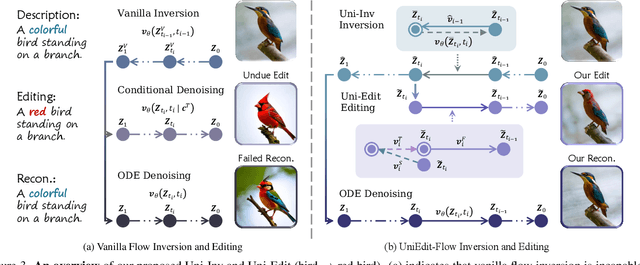
Flow matching models have emerged as a strong alternative to diffusion models, but existing inversion and editing methods designed for diffusion are often ineffective or inapplicable to them. The straight-line, non-crossing trajectories of flow models pose challenges for diffusion-based approaches but also open avenues for novel solutions. In this paper, we introduce a predictor-corrector-based framework for inversion and editing in flow models. First, we propose Uni-Inv, an effective inversion method designed for accurate reconstruction. Building on this, we extend the concept of delayed injection to flow models and introduce Uni-Edit, a region-aware, robust image editing approach. Our methodology is tuning-free, model-agnostic, efficient, and effective, enabling diverse edits while ensuring strong preservation of edit-irrelevant regions. Extensive experiments across various generative models demonstrate the superiority and generalizability of Uni-Inv and Uni-Edit, even under low-cost settings. Project page: https://uniedit-flow.github.io/
Object-level Visual Prompts for Compositional Image Generation
Jan 02, 2025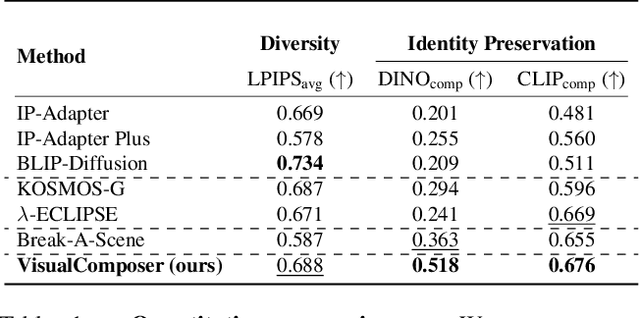


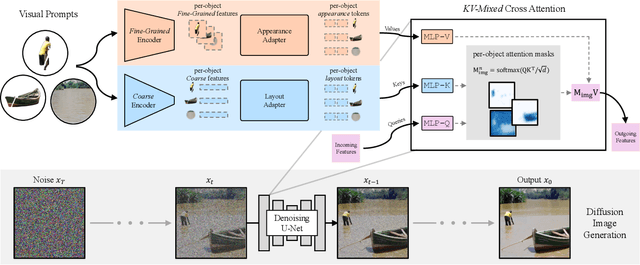
We introduce a method for composing object-level visual prompts within a text-to-image diffusion model. Our approach addresses the task of generating semantically coherent compositions across diverse scenes and styles, similar to the versatility and expressiveness offered by text prompts. A key challenge in this task is to preserve the identity of the objects depicted in the input visual prompts, while also generating diverse compositions across different images. To address this challenge, we introduce a new KV-mixed cross-attention mechanism, in which keys and values are learned from distinct visual representations. The keys are derived from an encoder with a small bottleneck for layout control, whereas the values come from a larger bottleneck encoder that captures fine-grained appearance details. By mixing keys and values from these complementary sources, our model preserves the identity of the visual prompts while supporting flexible variations in object arrangement, pose, and composition. During inference, we further propose object-level compositional guidance to improve the method's identity preservation and layout correctness. Results show that our technique produces diverse scene compositions that preserve the unique characteristics of each visual prompt, expanding the creative potential of text-to-image generation.
Omni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
Motion Diffusion-Guided 3D Global HMR from a Dynamic Camera
Nov 15, 2024



Motion capture technologies have transformed numerous fields, from the film and gaming industries to sports science and healthcare, by providing a tool to capture and analyze human movement in great detail. The holy grail in the topic of monocular global human mesh and motion reconstruction (GHMR) is to achieve accuracy on par with traditional multi-view capture on any monocular videos captured with a dynamic camera, in-the-wild. This is a challenging task as the monocular input has inherent depth ambiguity, and the moving camera adds additional complexity as the rendered human motion is now a product of both human and camera movement. Not accounting for this confusion, existing GHMR methods often output motions that are unrealistic, e.g. unaccounted root translation of the human causes foot sliding. We present DiffOpt, a novel 3D global HMR method using Diffusion Optimization. Our key insight is that recent advances in human motion generation, such as the motion diffusion model (MDM), contain a strong prior of coherent human motion. The core of our method is to optimize the initial motion reconstruction using the MDM prior. This step can lead to more globally coherent human motion. Our optimization jointly optimizes the motion prior loss and reprojection loss to correctly disentangle the human and camera motions. We validate DiffOpt with video sequences from the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild (EMDB) and Egobody, and demonstrate superior global human motion recovery capability over other state-of-the-art global HMR methods most prominently in long video settings.
Interpreting the Weight Space of Customized Diffusion Models
Jun 13, 2024


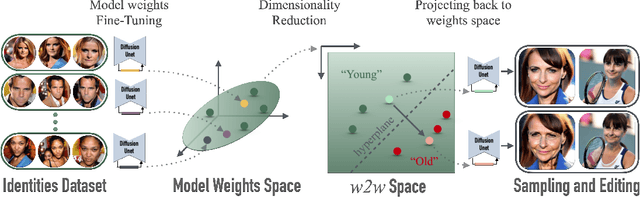
We investigate the space of weights spanned by a large collection of customized diffusion models. We populate this space by creating a dataset of over 60,000 models, each of which is a base model fine-tuned to insert a different person's visual identity. We model the underlying manifold of these weights as a subspace, which we term weights2weights. We demonstrate three immediate applications of this space -- sampling, editing, and inversion. First, as each point in the space corresponds to an identity, sampling a set of weights from it results in a model encoding a novel identity. Next, we find linear directions in this space corresponding to semantic edits of the identity (e.g., adding a beard). These edits persist in appearance across generated samples. Finally, we show that inverting a single image into this space reconstructs a realistic identity, even if the input image is out of distribution (e.g., a painting). Our results indicate that the weight space of fine-tuned diffusion models behaves as an interpretable latent space of identities.
MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
Apr 17, 2024We introduce a new architecture for personalization of text-to-image diffusion models, coined Mixture-of-Attention (MoA). Inspired by the Mixture-of-Experts mechanism utilized in large language models (LLMs), MoA distributes the generation workload between two attention pathways: a personalized branch and a non-personalized prior branch. MoA is designed to retain the original model's prior by fixing its attention layers in the prior branch, while minimally intervening in the generation process with the personalized branch that learns to embed subjects in the layout and context generated by the prior branch. A novel routing mechanism manages the distribution of pixels in each layer across these branches to optimize the blend of personalized and generic content creation. Once trained, MoA facilitates the creation of high-quality, personalized images featuring multiple subjects with compositions and interactions as diverse as those generated by the original model. Crucially, MoA enhances the distinction between the model's pre-existing capability and the newly augmented personalized intervention, thereby offering a more disentangled subject-context control that was previously unattainable. Project page: https://snap-research.github.io/mixture-of-attention
Iterative Motion Editing with Natural Language
Dec 15, 2023



Text-to-motion diffusion models can generate realistic animations from text prompts, but do not support fine-grained motion editing controls. In this paper we present a method for using natural language to iteratively specify local edits to existing character animations, a task that is common in most computer animation workflows. Our key idea is to represent a space of motion edits using a set of kinematic motion operators that have well-defined semantics for how to modify specific frames of a target motion. We provide an algorithm that leverages pre-existing language models to translate textual descriptions of motion edits to sequences of motion editing operators (MEOs). Given new keyframes produced by the MEOs, we use diffusion-based keyframe interpolation to generate final motions. Through a user study and quantitative evaluation, we demonstrate that our system can perform motion edits that respect the animator's editing intent, remain faithful to the original animation (they edit the original animation, not dramatically change it), and yield realistic character animation results.
Open World Object Detection in the Era of Foundation Models
Dec 10, 2023Object detection is integral to a bevy of real-world applications, from robotics to medical image analysis. To be used reliably in such applications, models must be capable of handling unexpected - or novel - objects. The open world object detection (OWD) paradigm addresses this challenge by enabling models to detect unknown objects and learn discovered ones incrementally. However, OWD method development is hindered due to the stringent benchmark and task definitions. These definitions effectively prohibit foundation models. Here, we aim to relax these definitions and investigate the utilization of pre-trained foundation models in OWD. First, we show that existing benchmarks are insufficient in evaluating methods that utilize foundation models, as even naive integration methods nearly saturate these benchmarks. This result motivated us to curate a new and challenging benchmark for these models. Therefore, we introduce a new benchmark that includes five real-world application-driven datasets, including challenging domains such as aerial and surgical images, and establish baselines. We exploit the inherent connection between classes in application-driven datasets and introduce a novel method, Foundation Object detection Model for the Open world, or FOMO, which identifies unknown objects based on their shared attributes with the base known objects. FOMO has ~3x unknown object mAP compared to baselines on our benchmark. However, our results indicate a significant place for improvement - suggesting a great research opportunity in further scaling object detection methods to real-world domains. Our code and benchmark are available at https://orrzohar.github.io/projects/fomo/.
Viewpoint Textual Inversion: Unleashing Novel View Synthesis with Pretrained 2D Diffusion Models
Sep 14, 2023Text-to-image diffusion models understand spatial relationship between objects, but do they represent the true 3D structure of the world from only 2D supervision? We demonstrate that yes, 3D knowledge is encoded in 2D image diffusion models like Stable Diffusion, and we show that this structure can be exploited for 3D vision tasks. Our method, Viewpoint Neural Textual Inversion (ViewNeTI), controls the 3D viewpoint of objects in generated images from frozen diffusion models. We train a small neural mapper to take camera viewpoint parameters and predict text encoder latents; the latents then condition the diffusion generation process to produce images with the desired camera viewpoint. ViewNeTI naturally addresses Novel View Synthesis (NVS). By leveraging the frozen diffusion model as a prior, we can solve NVS with very few input views; we can even do single-view novel view synthesis. Our single-view NVS predictions have good semantic details and photorealism compared to prior methods. Our approach is well suited for modeling the uncertainty inherent in sparse 3D vision problems because it can efficiently generate diverse samples. Our view-control mechanism is general, and can even change the camera view in images generated by user-defined prompts.