 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
Development and Evaluation of a Learning-based Model for Real-time Haptic Texture Rendering
Dec 27, 2022Current Virtual Reality (VR) environments lack the rich haptic signals that humans experience during real-life interactions, such as the sensation of texture during lateral movement on a surface. Adding realistic haptic textures to VR environments requires a model that generalizes to variations of a user's interaction and to the wide variety of existing textures in the world. Current methodologies for haptic texture rendering exist, but they usually develop one model per texture, resulting in low scalability. We present a deep learning-based action-conditional model for haptic texture rendering and evaluate its perceptual performance in rendering realistic texture vibrations through a multi part human user study. This model is unified over all materials and uses data from a vision-based tactile sensor (GelSight) to render the appropriate surface conditioned on the user's action in real time. For rendering texture, we use a high-bandwidth vibrotactile transducer attached to a 3D Systems Touch device. The result of our user study shows that our learning-based method creates high-frequency texture renderings with comparable or better quality than state-of-the-art methods without the need for learning a separate model per texture. Furthermore, we show that the method is capable of rendering previously unseen textures using a single GelSight image of their surface.
Visuomotor Control in Multi-Object Scenes Using Object-Aware Representations
May 12, 2022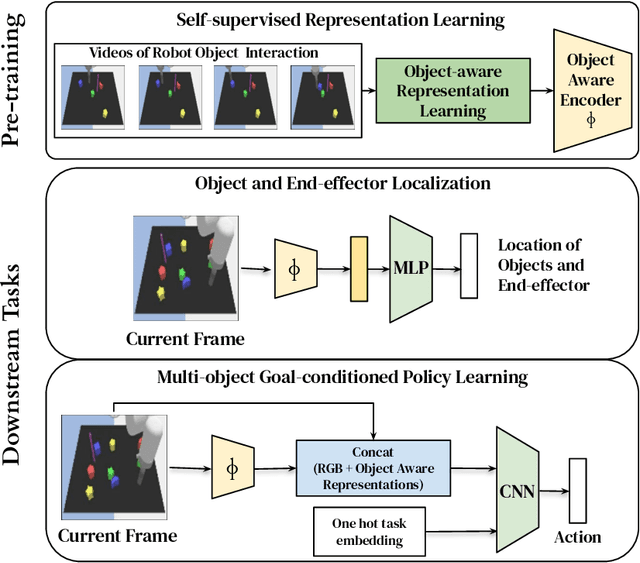
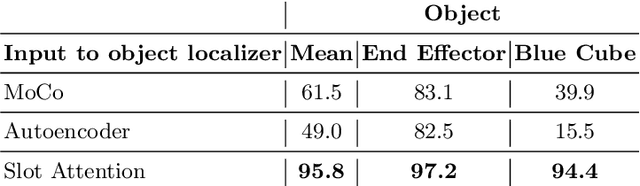

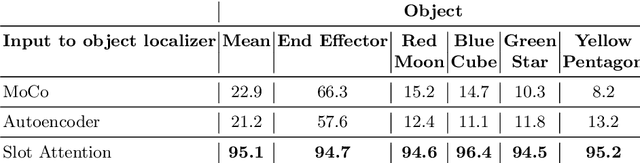
Perceptual understanding of the scene and the relationship between its different components is important for successful completion of robotic tasks. Representation learning has been shown to be a powerful technique for this, but most of the current methodologies learn task specific representations that do not necessarily transfer well to other tasks. Furthermore, representations learned by supervised methods require large labeled datasets for each task that are expensive to collect in the real world. Using self-supervised learning to obtain representations from unlabeled data can mitigate this problem. However, current self-supervised representation learning methods are mostly object agnostic, and we demonstrate that the resulting representations are insufficient for general purpose robotics tasks as they fail to capture the complexity of scenes with many components. In this paper, we explore the effectiveness of using object-aware representation learning techniques for robotic tasks. Our self-supervised representations are learned by observing the agent freely interacting with different parts of the environment and is queried in two different settings: (i) policy learning and (ii) object location prediction. We show that our model learns control policies in a sample-efficient manner and outperforms state-of-the-art object agnostic techniques as well as methods trained on raw RGB images. Our results show a 20 percent increase in performance in low data regimes (1000 trajectories) in policy training using implicit behavioral cloning (IBC). Furthermore, our method outperforms the baselines for the task of object localization in multi-object scenes.
Learning an Action-Conditional Model for Haptic Texture Generation
Sep 28, 2019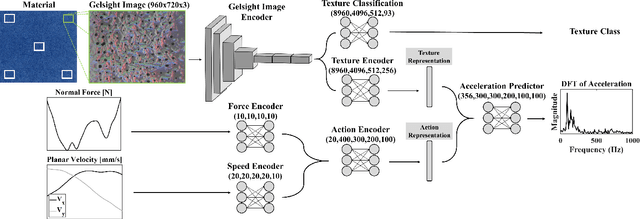
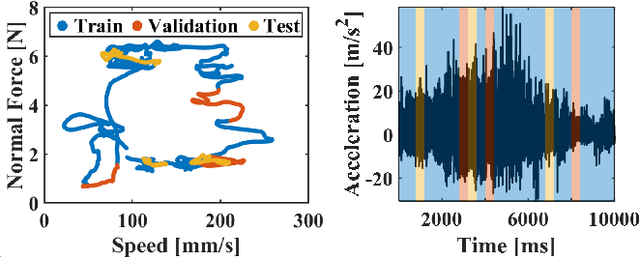
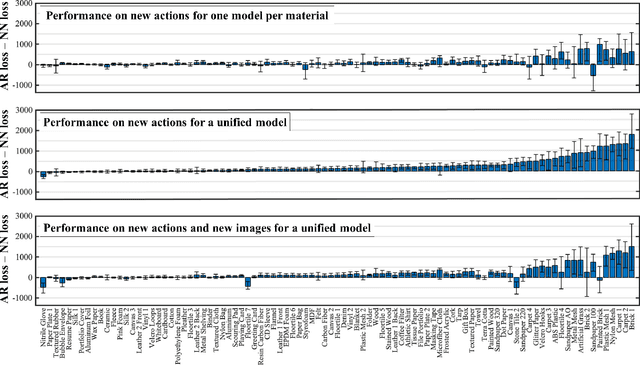
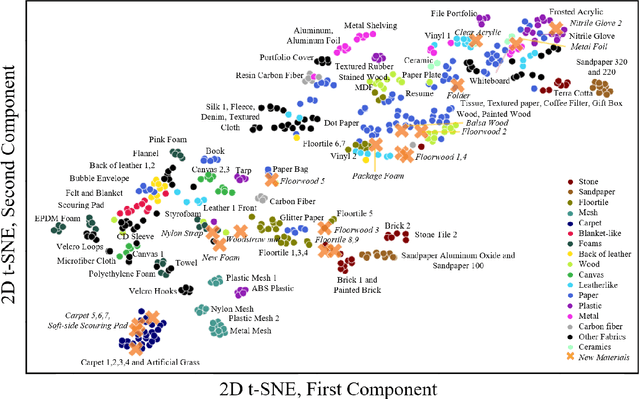
Rich haptic sensory feedback in response to user interactions is desirable for an effective, immersive virtual reality or teleoperation system. However, this feedback depends on material properties and user interactions in a complex, non-linear manner. Therefore, it is challenging to model the mapping from material and user interactions to haptic feedback in a way that generalizes over many variations of the user's input. Current methodologies are typically conditioned on user interactions, but require a separate model for each material. In this paper, we present a learned action-conditional model that uses data from a vision-based tactile sensor (GelSight) and user's action as input. This model predicts an induced acceleration that could be used to provide haptic vibration feedback to a user. We trained our proposed model on a publicly available dataset (Penn Haptic Texture Toolkit) that we augmented with GelSight measurements of the different materials. We show that a unified model over all materials outperforms previous methods and generalizes to new actions and new instances of the material categories in the dataset.