 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024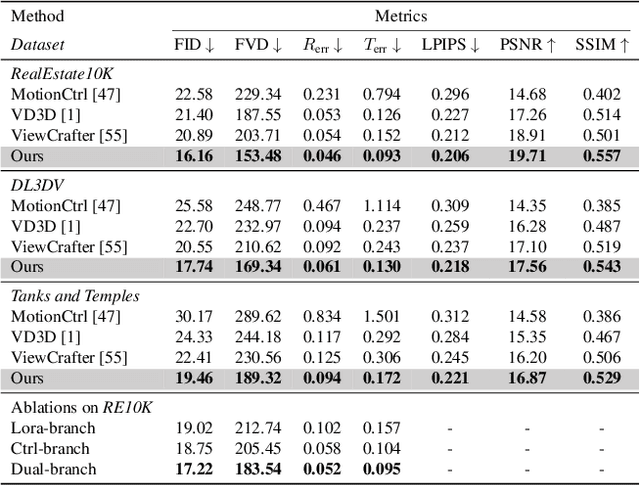
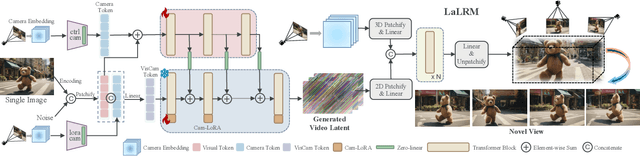
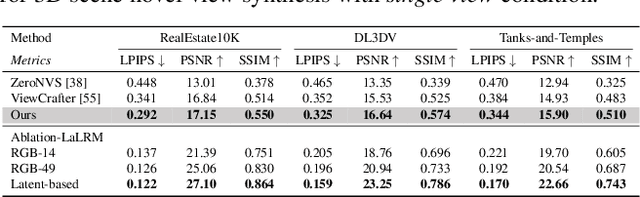

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
Omni-ID: Holistic Identity Representation Designed for Generative Tasks
Dec 12, 2024We introduce Omni-ID, a novel facial representation designed specifically for generative tasks. Omni-ID encodes holistic information about an individual's appearance across diverse expressions and poses within a fixed-size representation. It consolidates information from a varied number of unstructured input images into a structured representation, where each entry represents certain global or local identity features. Our approach uses a few-to-many identity reconstruction training paradigm, where a limited set of input images is used to reconstruct multiple target images of the same individual in various poses and expressions. A multi-decoder framework is further employed to leverage the complementary strengths of diverse decoders during training. Unlike conventional representations, such as CLIP and ArcFace, which are typically learned through discriminative or contrastive objectives, Omni-ID is optimized with a generative objective, resulting in a more comprehensive and nuanced identity capture for generative tasks. Trained on our MFHQ dataset -- a multi-view facial image collection, Omni-ID demonstrates substantial improvements over conventional representations across various generative tasks.
AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
Dec 02, 2024



Numerous works have recently integrated 3D camera control into foundational text-to-video models, but the resulting camera control is often imprecise, and video generation quality suffers. In this work, we analyze camera motion from a first principles perspective, uncovering insights that enable precise 3D camera manipulation without compromising synthesis quality. First, we determine that motion induced by camera movements in videos is low-frequency in nature. This motivates us to adjust train and test pose conditioning schedules, accelerating training convergence while improving visual and motion quality. Then, by probing the representations of an unconditional video diffusion transformer, we observe that they implicitly perform camera pose estimation under the hood, and only a sub-portion of their layers contain the camera information. This suggested us to limit the injection of camera conditioning to a subset of the architecture to prevent interference with other video features, leading to 4x reduction of training parameters, improved training speed and 10% higher visual quality. Finally, we complement the typical dataset for camera control learning with a curated dataset of 20K diverse dynamic videos with stationary cameras. This helps the model disambiguate the difference between camera and scene motion, and improves the dynamics of generated pose-conditioned videos. We compound these findings to design the Advanced 3D Camera Control (AC3D) architecture, the new state-of-the-art model for generative video modeling with camera control.
FastPCI: Motion-Structure Guided Fast Point Cloud Frame Interpolation
Oct 25, 2024



Point cloud frame interpolation is a challenging task that involves accurate scene flow estimation across frames and maintaining the geometry structure. Prevailing techniques often rely on pre-trained motion estimators or intensive testing-time optimization, resulting in compromised interpolation accuracy or prolonged inference. This work presents FastPCI that introduces Pyramid Convolution-Transformer architecture for point cloud frame interpolation. Our hybrid Convolution-Transformer improves the local and long-range feature learning, while the pyramid network offers multilevel features and reduces the computation. In addition, FastPCI proposes a unique Dual-Direction Motion-Structure block for more accurate scene flow estimation. Our design is motivated by two facts: (1) accurate scene flow preserves 3D structure, and (2) point cloud at the previous timestep should be reconstructable using reverse motion from future timestep. Extensive experiments show that FastPCI significantly outperforms the state-of-the-art PointINet and NeuralPCI with notable gains (e.g. 26.6% and 18.3% reduction in Chamfer Distance in KITTI), while being more than 10x and 600x faster, respectively. Code is available at https://github.com/genuszty/FastPCI
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024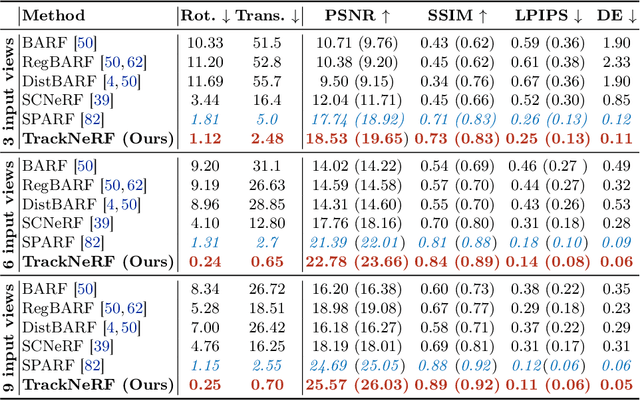
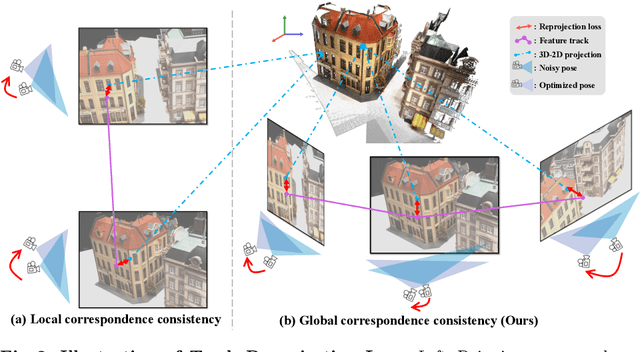
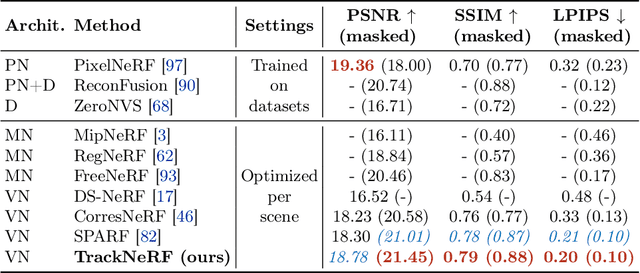

Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control
Jul 17, 2024



Modern text-to-video synthesis models demonstrate coherent, photorealistic generation of complex videos from a text description. However, most existing models lack fine-grained control over camera movement, which is critical for downstream applications related to content creation, visual effects, and 3D vision. Recently, new methods demonstrate the ability to generate videos with controllable camera poses these techniques leverage pre-trained U-Net-based diffusion models that explicitly disentangle spatial and temporal generation. Still, no existing approach enables camera control for new, transformer-based video diffusion models that process spatial and temporal information jointly. Here, we propose to tame video transformers for 3D camera control using a ControlNet-like conditioning mechanism that incorporates spatiotemporal camera embeddings based on Plucker coordinates. The approach demonstrates state-of-the-art performance for controllable video generation after fine-tuning on the RealEstate10K dataset. To the best of our knowledge, our work is the first to enable camera control for transformer-based video diffusion models.
GES: Generalized Exponential Splatting for Efficient Radiance Field Rendering
Feb 15, 2024



Advancements in 3D Gaussian Splatting have significantly accelerated 3D reconstruction and generation. However, it may require a large number of Gaussians, which creates a substantial memory footprint. This paper introduces GES (Generalized Exponential Splatting), a novel representation that employs Generalized Exponential Function (GEF) to model 3D scenes, requiring far fewer particles to represent a scene and thus significantly outperforming Gaussian Splatting methods in efficiency with a plug-and-play replacement ability for Gaussian-based utilities. GES is validated theoretically and empirically in both principled 1D setup and realistic 3D scenes. It is shown to represent signals with sharp edges more accurately, which are typically challenging for Gaussians due to their inherent low-pass characteristics. Our empirical analysis demonstrates that GEF outperforms Gaussians in fitting natural-occurring signals (e.g. squares, triangles, and parabolic signals), thereby reducing the need for extensive splitting operations that increase the memory footprint of Gaussian Splatting. With the aid of a frequency-modulated loss, GES achieves competitive performance in novel-view synthesis benchmarks while requiring less than half the memory storage of Gaussian Splatting and increasing the rendering speed by up to 39%. The code is available on the project website https://abdullahamdi.com/ges .
SPAD : Spatially Aware Multiview Diffusers
Feb 07, 2024

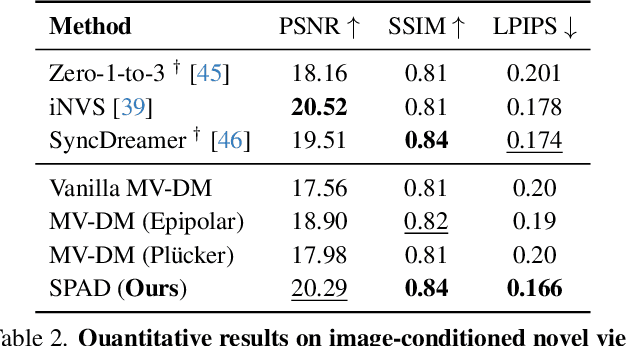

We present SPAD, a novel approach for creating consistent multi-view images from text prompts or single images. To enable multi-view generation, we repurpose a pretrained 2D diffusion model by extending its self-attention layers with cross-view interactions, and fine-tune it on a high quality subset of Objaverse. We find that a naive extension of the self-attention proposed in prior work (e.g. MVDream) leads to content copying between views. Therefore, we explicitly constrain the cross-view attention based on epipolar geometry. To further enhance 3D consistency, we utilize Plucker coordinates derived from camera rays and inject them as positional encoding. This enables SPAD to reason over spatial proximity in 3D well. In contrast to recent works that can only generate views at fixed azimuth and elevation, SPAD offers full camera control and achieves state-of-the-art results in novel view synthesis on unseen objects from the Objaverse and Google Scanned Objects datasets. Finally, we demonstrate that text-to-3D generation using SPAD prevents the multi-face Janus issue. See more details at our webpage: https://yashkant.github.io/spad
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024



We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.
Diffusion Priors for Dynamic View Synthesis from Monocular Videos
Jan 10, 2024Dynamic novel view synthesis aims to capture the temporal evolution of visual content within videos. Existing methods struggle to distinguishing between motion and structure, particularly in scenarios where camera poses are either unknown or constrained compared to object motion. Furthermore, with information solely from reference images, it is extremely challenging to hallucinate unseen regions that are occluded or partially observed in the given videos. To address these issues, we first finetune a pretrained RGB-D diffusion model on the video frames using a customization technique. Subsequently, we distill the knowledge from the finetuned model to a 4D representations encompassing both dynamic and static Neural Radiance Fields (NeRF) components. The proposed pipeline achieves geometric consistency while preserving the scene identity. We perform thorough experiments to evaluate the efficacy of the proposed method qualitatively and quantitatively. Our results demonstrate the robustness and utility of our approach in challenging cases, further advancing dynamic novel view synthesis.