 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinner: Shining Light on Digital Twins in a Few Snaps
Mar 11, 2025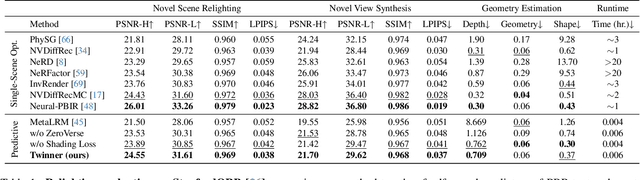
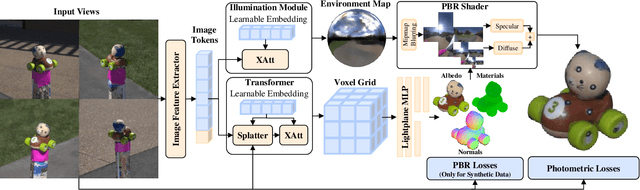
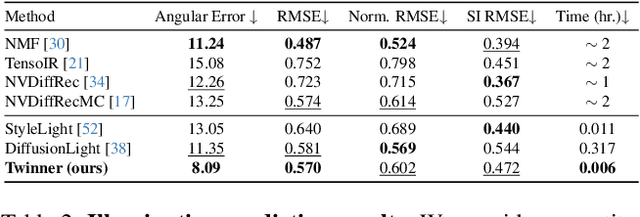
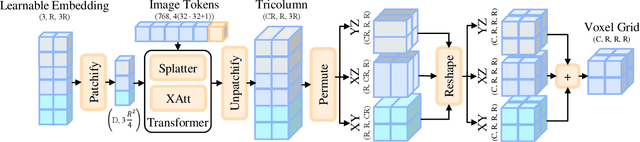
We present the first large reconstruction model, Twinner, capable of recovering a scene's illumination as well as an object's geometry and material properties from only a few posed images. Twinner is based on the Large Reconstruction Model and innovates in three key ways: 1) We introduce a memory-efficient voxel-grid transformer whose memory scales only quadratically with the size of the voxel grid. 2) To deal with scarcity of high-quality ground-truth PBR-shaded models, we introduce a large fully-synthetic dataset of procedurally-generated PBR-textured objects lit with varied illumination. 3) To narrow the synthetic-to-real gap, we finetune the model on real life datasets by means of a differentiable physically-based shading model, eschewing the need for ground-truth illumination or material properties which are challenging to obtain in real life. We demonstrate the efficacy of our model on the real life StanfordORB benchmark where, given few input views, we achieve reconstruction quality significantly superior to existing feedforward reconstruction networks, and comparable to significantly slower per-scene optimization methods.
UnCommon Objects in 3D
Jan 13, 2025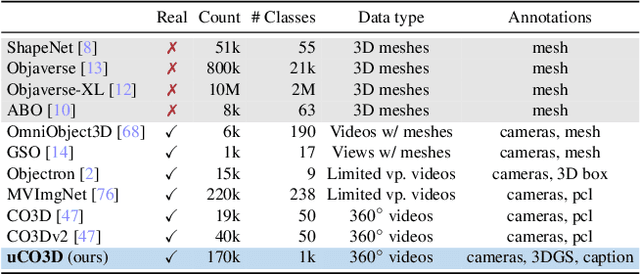
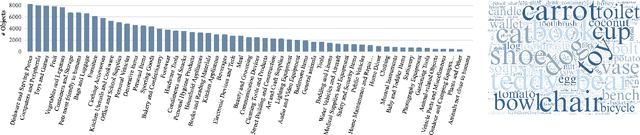


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024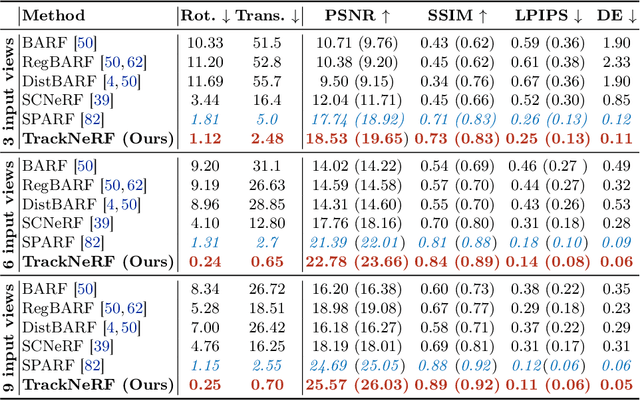
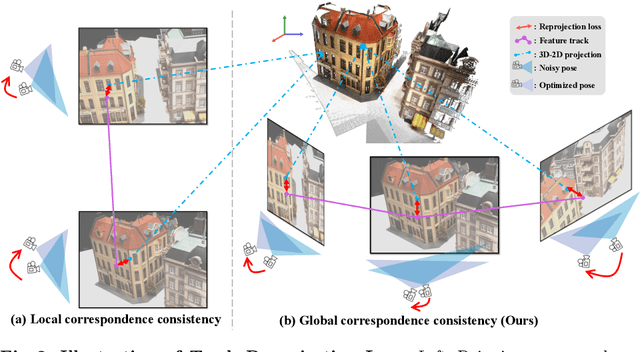
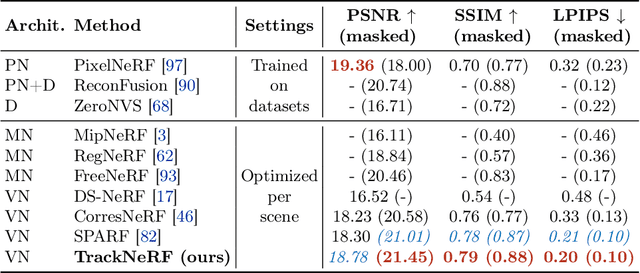

Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
SplitNeRF: Split Sum Approximation Neural Field for Joint Geometry, Illumination, and Material Estimation
Nov 28, 2023



We present a novel approach for digitizing real-world objects by estimating their geometry, material properties, and environmental lighting from a set of posed images with fixed lighting. Our method incorporates into Neural Radiance Field (NeRF) pipelines the split sum approximation used with image-based lighting for real-time physical-based rendering. We propose modeling the scene's lighting with a single scene-specific MLP representing pre-integrated image-based lighting at arbitrary resolutions. We achieve accurate modeling of pre-integrated lighting by exploiting a novel regularizer based on efficient Monte Carlo sampling. Additionally, we propose a new method of supervising self-occlusion predictions by exploiting a similar regularizer based on Monte Carlo sampling. Experimental results demonstrate the efficiency and effectiveness of our approach in estimating scene geometry, material properties, and lighting. Our method is capable of attaining state-of-the-art relighting quality after only ${\sim}1$ hour of training in a single NVIDIA A100 GPU.
Enhancing Neural Rendering Methods with Image Augmentations
Jun 15, 2023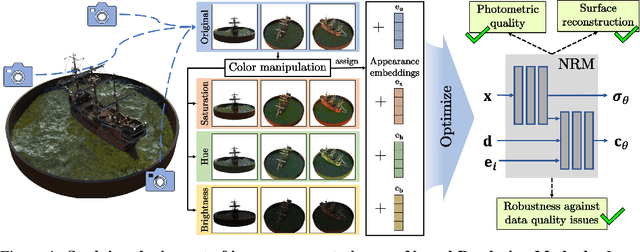
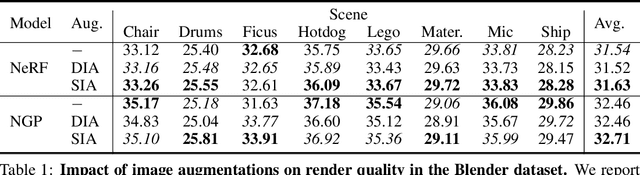


Faithfully reconstructing 3D geometry and generating novel views of scenes are critical tasks in 3D computer vision. Despite the widespread use of image augmentations across computer vision applications, their potential remains underexplored when learning neural rendering methods (NRMs) for 3D scenes. This paper presents a comprehensive analysis of the use of image augmentations in NRMs, where we explore different augmentation strategies. We found that introducing image augmentations during training presents challenges such as geometric and photometric inconsistencies for learning NRMs from images. Specifically, geometric inconsistencies arise from alterations in shapes, positions, and orientations from the augmentations, disrupting spatial cues necessary for accurate 3D reconstruction. On the other hand, photometric inconsistencies arise from changes in pixel intensities introduced by the augmentations, affecting the ability to capture the underlying 3D structures of the scene. We alleviate these issues by focusing on color manipulations and introducing learnable appearance embeddings that allow NRMs to explain away photometric variations. Our experiments demonstrate the benefits of incorporating augmentations when learning NRMs, including improved photometric quality and surface reconstruction, as well as enhanced robustness against data quality issues, such as reduced training data and image degradations.
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023



This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 22, 2022



Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation. In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
PointRGCN: Graph Convolution Networks for 3D Vehicles Detection Refinement
Nov 27, 2019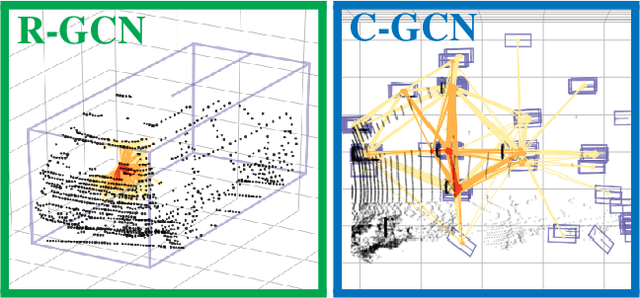

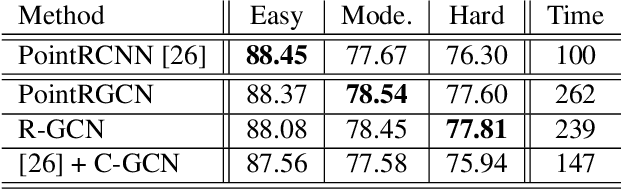
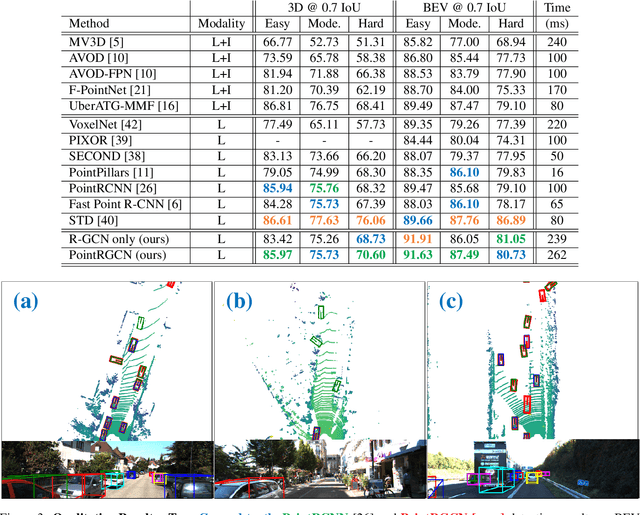
In autonomous driving pipelines, perception modules provide a visual understanding of the surrounding road scene. Among the perception tasks, vehicle detection is of paramount importance for a safe driving as it identifies the position of other agents sharing the road. In our work, we propose PointRGCN: a graph-based 3D object detection pipeline based on graph convolutional networks (GCNs) which operates exclusively on 3D LiDAR point clouds. To perform more accurate 3D object detection, we leverage a graph representation that performs proposal feature and context aggregation. We integrate residual GCNs in a two-stage 3D object detection pipeline, where 3D object proposals are refined using a novel graph representation. In particular, R-GCN is a residual GCN that classifies and regresses 3D proposals, and C-GCN is a contextual GCN that further refines proposals by sharing contextual information between multiple proposals. We integrate our refinement modules into a novel 3D detection pipeline, PointRGCN, and achieve state-of-the-art performance on the easy difficulty for the bird eye view detection task.
Leveraging Shape Completion for 3D Siamese Tracking
Mar 28, 2019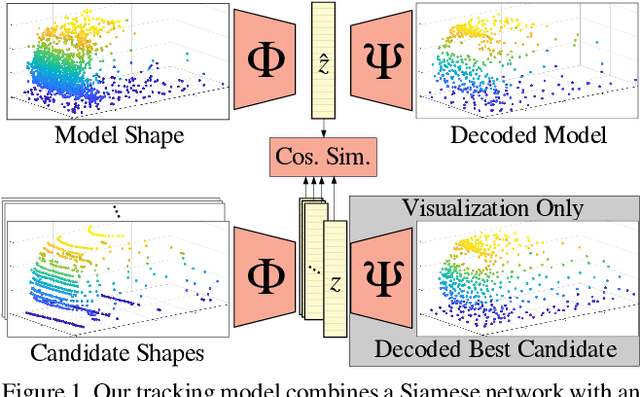

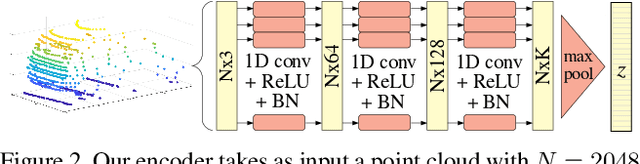
Point clouds are challenging to process due to their sparsity, therefore autonomous vehicles rely more on appearance attributes than pure geometric features. However, 3D LIDAR perception can provide crucial information for urban navigation in challenging light or weather conditions. In this paper, we investigate the versatility of Shape Completion for 3D Object Tracking in LIDAR point clouds. We design a Siamese tracker that encodes model and candidate shapes into a compact latent representation. We regularize the encoding by enforcing the latent representation to decode into an object model shape. We observe that 3D object tracking and 3D shape completion complement each other. Learning a more meaningful latent representation shows better discriminatory capabilities, leading to improved tracking performance. We test our method on the KITTI Tracking set using car 3D bounding boxes. Our model reaches a 76.94% Success rate and 81.38% Precision for 3D Object Tracking, with the shape completion regularization leading to an improvement of 3% in both metrics.
Efficient Tracking Proposals using 2D-3D Siamese Networks on LIDAR
Mar 25, 2019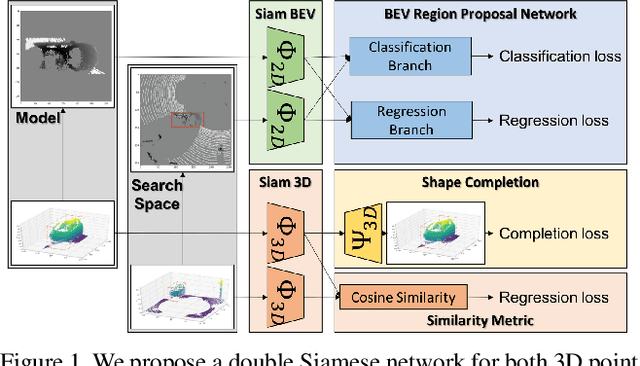
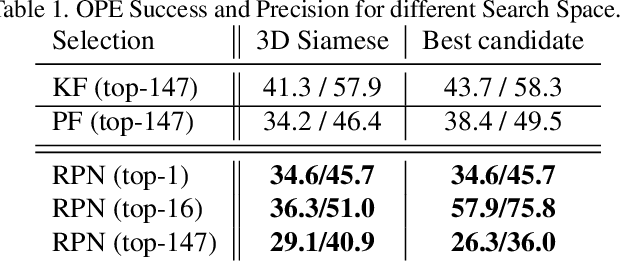
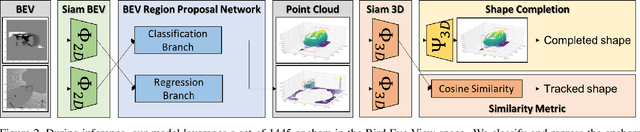
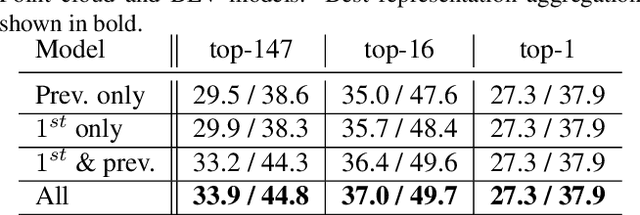
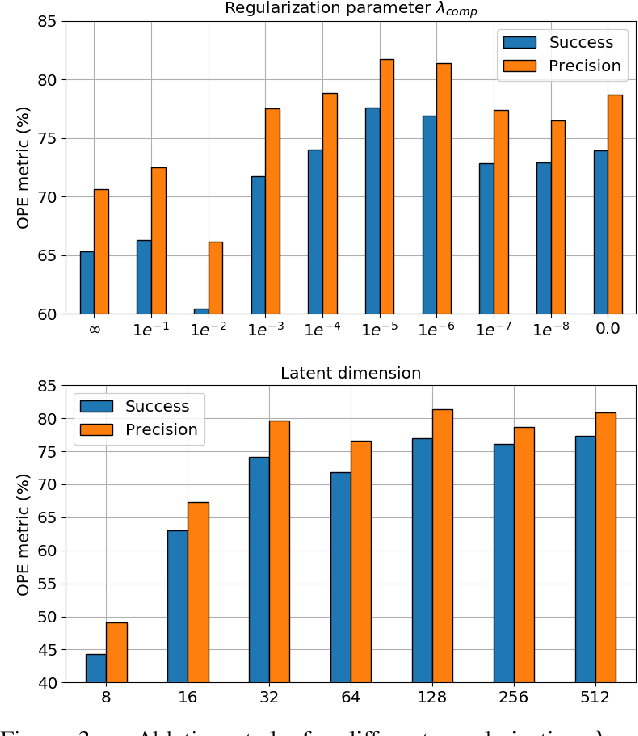
Tracking vehicles in LIDAR point clouds is a challenging task due to the sparsity of the data and the dense search space. The lack of structure in point clouds impedes the use of convolution and correlation filters usually employed in 2D object tracking. In addition, structuring point clouds is cumbersome and implies losing fine-grained information. As a result, generating proposals in 3D space is expensive and inefficient. In this paper, we leverage the dense and structured Bird Eye View (BEV) representation of LIDAR point clouds to efficiently search for objects of interest. We use an efficient Region Proposal Network and generate a small number of object proposals in 3D. Successively, we refine our selection of 3D object candidates by exploiting the similarity capability of a 3D Siamese network. We regularize the latter 3D Siamese network for shape completion to enhance its discrimination capability. Our method attempts to solve both for an efficient search space in the BEV space and a meaningful selection using 3D LIDAR point cloud. We show that the Region Proposal in the BEV outperforms Bayesian methods such as Kalman and Particle Filters in providing proposal by a significant margin and that such candidates are suitable for the 3D Siamese network. By training our method end-to-end, we outperform the previous baseline in vehicle tracking by 12% / 18% in Success and Precision when using only 16 candidates.