 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels or Positions? Benchmarking Modalities in Group Activity Recognition
Nov 16, 2025Group Activity Recognition (GAR) is well studied on the video modality for surveillance and indoor team sports (e.g., volleyball, basketball). Yet, other modalities such as agent positions and trajectories over time, i.e. tracking, remain comparatively under-explored despite being compact, agent-centric signals that explicitly encode spatial interactions. Understanding whether pixel (video) or position (tracking) modalities leads to better group activity recognition is therefore important to drive further research on the topic. However, no standardized benchmark currently exists that aligns broadcast video and tracking data for the same group activities, leading to a lack of apples-to-apples comparison between these modalities for GAR. In this work, we introduce SoccerNet-GAR, a multimodal dataset built from the $64$ matches of the football World Cup 2022. Specifically, the broadcast videos and player tracking modalities for $94{,}285$ group activities are synchronized and annotated with $10$ categories. Furthermore, we define a unified evaluation protocol to benchmark two strong unimodal approaches: (i) a competitive video-based classifiers and (ii) a tracking-based classifiers leveraging graph neural networks. In particular, our novel role-aware graph architecture for tracking-based GAR directly encodes tactical structure through positional edges and temporal attention. Our tracking model achieves $67.2\%$ balanced accuracy compared to $58.1\%$ for the best video baseline, while training $4.25 \times$ faster with $438 \times$ fewer parameters ($197K$ \vs $86.3M$). This study provides new insights into the relative strengths of pixels and positions for group activity recognition. Overall, it highlights the importance of modality choice and role-aware modeling for GAR.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Triangle Splatting for Real-Time Radiance Field Rendering
May 25, 2025



The field of computer graphics was revolutionized by models such as Neural Radiance Fields and 3D Gaussian Splatting, displacing triangles as the dominant representation for photogrammetry. In this paper, we argue for a triangle comeback. We develop a differentiable renderer that directly optimizes triangles via end-to-end gradients. We achieve this by rendering each triangle as differentiable splats, combining the efficiency of triangles with the adaptive density of representations based on independent primitives. Compared to popular 2D and 3D Gaussian Splatting methods, our approach achieves higher visual fidelity, faster convergence, and increased rendering throughput. On the Mip-NeRF360 dataset, our method outperforms concurrent non-volumetric primitives in visual fidelity and achieves higher perceptual quality than the state-of-the-art Zip-NeRF on indoor scenes. Triangles are simple, compatible with standard graphics stacks and GPU hardware, and highly efficient: for the \textit{Garden} scene, we achieve over 2,400 FPS at 1280x720 resolution using an off-the-shelf mesh renderer. These results highlight the efficiency and effectiveness of triangle-based representations for high-quality novel view synthesis. Triangles bring us closer to mesh-based optimization by combining classical computer graphics with modern differentiable rendering frameworks. The project page is https://trianglesplatting.github.io/
Action Anticipation from SoccerNet Football Video Broadcasts
Apr 16, 2025Artificial intelligence has revolutionized the way we analyze sports videos, whether to understand the actions of games in long untrimmed videos or to anticipate the player's motion in future frames. Despite these efforts, little attention has been given to anticipating game actions before they occur. In this work, we introduce the task of action anticipation for football broadcast videos, which consists in predicting future actions in unobserved future frames, within a five- or ten-second anticipation window. To benchmark this task, we release a new dataset, namely the SoccerNet Ball Action Anticipation dataset, based on SoccerNet Ball Action Spotting. Additionally, we propose a Football Action ANticipation TRAnsformer (FAANTRA), a baseline method that adapts FUTR, a state-of-the-art action anticipation model, to predict ball-related actions. To evaluate action anticipation, we introduce new metrics, including mAP@$\delta$, which evaluates the temporal precision of predicted future actions, as well as mAP@$\infty$, which evaluates their occurrence within the anticipation window. We also conduct extensive ablation studies to examine the impact of various task settings, input configurations, and model architectures. Experimental results highlight both the feasibility and challenges of action anticipation in football videos, providing valuable insights into the design of predictive models for sports analytics. By forecasting actions before they unfold, our work will enable applications in automated broadcasting, tactical analysis, and player decision-making. Our dataset and code are publicly available at https://github.com/MohamadDalal/FAANTRA.
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
3D Convex Splatting: Radiance Field Rendering with 3D Smooth Convexes
Nov 26, 2024


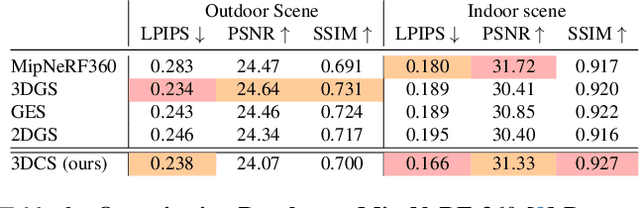
Recent advances in radiance field reconstruction, such as 3D Gaussian Splatting (3DGS), have achieved high-quality novel view synthesis and fast rendering by representing scenes with compositions of Gaussian primitives. However, 3D Gaussians present several limitations for scene reconstruction. Accurately capturing hard edges is challenging without significantly increasing the number of Gaussians, creating a large memory footprint. Moreover, they struggle to represent flat surfaces, as they are diffused in space. Without hand-crafted regularizers, they tend to disperse irregularly around the actual surface. To circumvent these issues, we introduce a novel method, named 3D Convex Splatting (3DCS), which leverages 3D smooth convexes as primitives for modeling geometrically-meaningful radiance fields from multi-view images. Smooth convex shapes offer greater flexibility than Gaussians, allowing for a better representation of 3D scenes with hard edges and dense volumes using fewer primitives. Powered by our efficient CUDA-based rasterizer, 3DCS achieves superior performance over 3DGS on benchmarks such as Mip-NeRF360, Tanks and Temples, and Deep Blending. Specifically, our method attains an improvement of up to 0.81 in PSNR and 0.026 in LPIPS compared to 3DGS while maintaining high rendering speeds and reducing the number of required primitives. Our results highlight the potential of 3D Convex Splatting to become the new standard for high-quality scene reconstruction and novel view synthesis. Project page: convexsplatting.github.io.
Deep learning for action spotting in association football videos
Oct 02, 2024
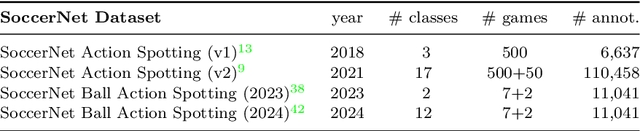
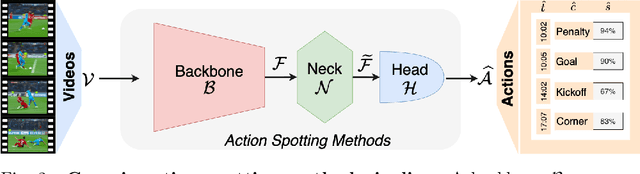

The task of action spotting consists in both identifying actions and precisely localizing them in time with a single timestamp in long, untrimmed video streams. Automatically extracting those actions is crucial for many sports applications, including sports analytics to produce extended statistics on game actions, coaching to provide support to video analysts, or fan engagement to automatically overlay content in the broadcast when specific actions occur. However, before 2018, no large-scale datasets for action spotting in sports were publicly available, which impeded benchmarking action spotting methods. In response, our team built the largest dataset and the most comprehensive benchmarks for sports video understanding, under the umbrella of SoccerNet. Particularly, our dataset contains a subset specifically dedicated to action spotting, called SoccerNet Action Spotting, containing more than 550 complete broadcast games annotated with almost all types of actions that can occur in a football game. This dataset is tailored to develop methods for automatic spotting of actions of interest, including deep learning approaches, by providing a large amount of manually annotated actions. To engage with the scientific community, the SoccerNet initiative organizes yearly challenges, during which participants from all around the world compete to achieve state-of-the-art performances. Thanks to our dataset and challenges, more than 60 methods were developed or published over the past five years, improving on the first baselines and making action spotting a viable option for the sports industry. This paper traces the history of action spotting in sports, from the creation of the task back in 2018, to the role it plays today in research and the sports industry.
SoccerNet 2024 Challenges Results
Sep 16, 2024

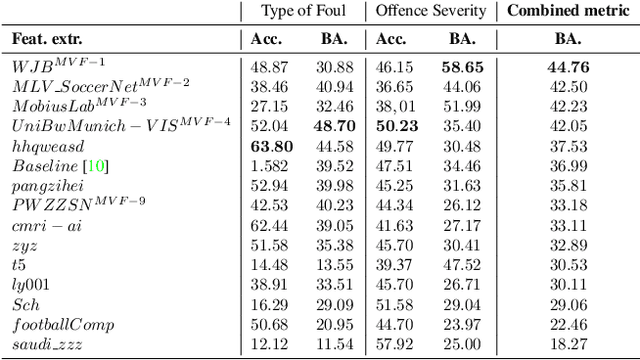
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024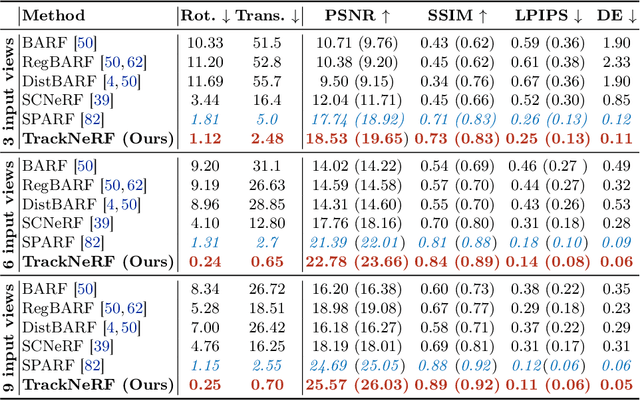
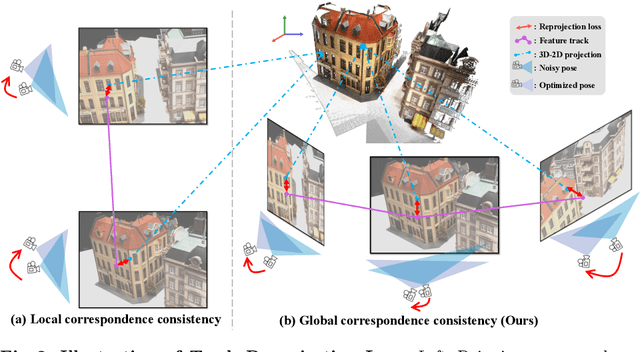
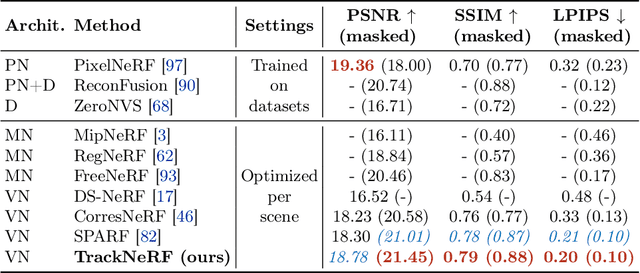

Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
Towards AI-Powered Video Assistant Referee System (VARS) for Association Football
Jul 18, 2024Over the past decade, the technology used by referees in football has improved substantially, enhancing the fairness and accuracy of decisions. This progress has culminated in the implementation of the Video Assistant Referee (VAR), an innovation that enables backstage referees to review incidents on the pitch from multiple points of view. However, the VAR is currently limited to professional leagues due to its expensive infrastructure and the lack of referees worldwide. In this paper, we present the semi-automated Video Assistant Referee System (VARS) that leverages the latest findings in multi-view video analysis. VARS sets a new state-of-the-art on the SoccerNet-MVFoul dataset, a multi-view video dataset of football fouls. Our VARS achieves a new state-of-the-art on the SoccerNet-MVFoul dataset by recognizing the type of foul in 50% of instances and the appropriate sanction in 46% of cases. Finally, we conducted a comparative study to investigate human performance in classifying fouls and their corresponding severity and compared these findings to our VARS. The results of our study highlight the potential of our VARS to reach human performance and support football refereeing across all levels of professional and amateur federations.