 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation
Jan 21, 2026Medical vision-language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present CURE, an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE fine-tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance, emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.37 IoU, boosts report quality by +0.188 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
EAGLE: Enhanced Visual Grounding Minimizes Hallucinations in Instructional Multimodal Models
Jan 06, 2025Large language models and vision transformers have demonstrated impressive zero-shot capabilities, enabling significant transferability in downstream tasks. The fusion of these models has resulted in multi-modal architectures with enhanced instructional capabilities. Despite incorporating vast image and language pre-training, these multi-modal architectures often generate responses that deviate from the ground truth in the image data. These failure cases are known as hallucinations. Current methods for mitigating hallucinations generally focus on regularizing the language component, improving the fusion module, or ensembling multiple visual encoders to improve visual representation. In this paper, we address the hallucination issue by directly enhancing the capabilities of the visual component. Our approach, named EAGLE, is fully agnostic to the LLM or fusion module and works as a post-pretraining approach that improves the grounding and language alignment of the visual encoder. We show that a straightforward reformulation of the original contrastive pre-training task results in an improved visual encoder that can be incorporated into the instructional multi-modal architecture without additional instructional training. As a result, EAGLE achieves a significant reduction in hallucinations across multiple challenging benchmarks and tasks.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
vCLIMB: A Novel Video Class Incremental Learning Benchmark
Jan 23, 2022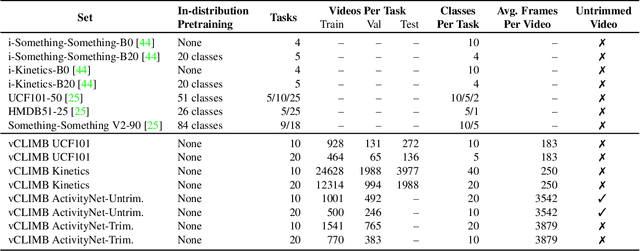
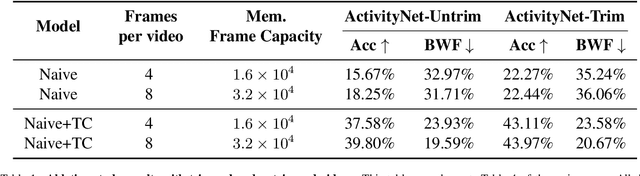
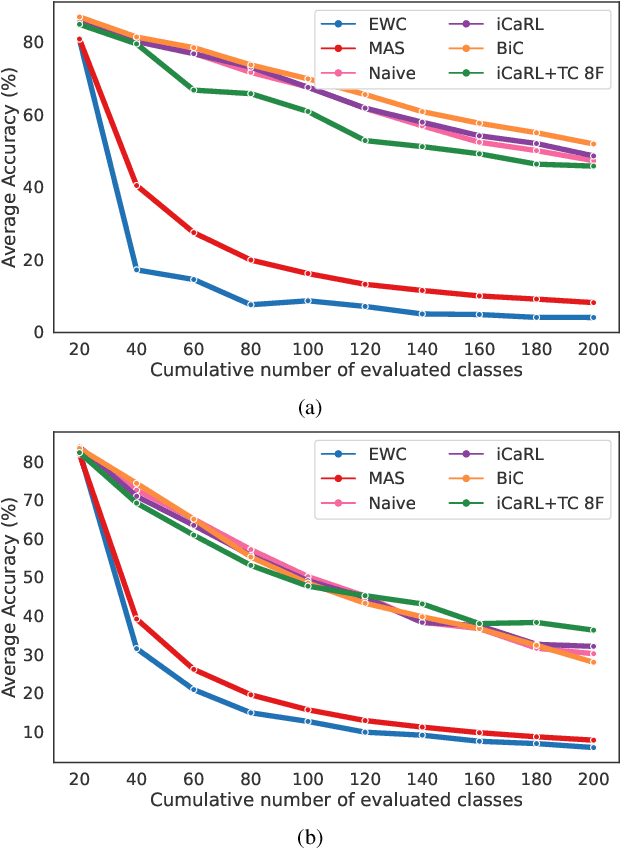
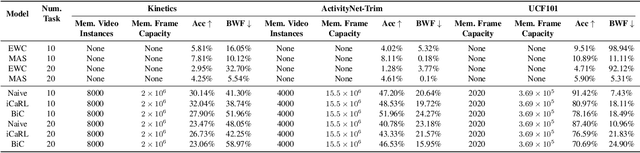
Continual learning (CL) is under-explored in the video domain. The few existing works contain splits with imbalanced class distributions over the tasks, or study the problem in unsuitable datasets. We introduce vCLIMB, a novel video continual learning benchmark. vCLIMB is a standardized test-bed to analyze catastrophic forgetting of deep models in video continual learning. In contrast to previous work, we focus on class incremental continual learning with models trained on a sequence of disjoint tasks, and distribute the number of classes uniformly across the tasks. We perform in-depth evaluations of existing CL methods in vCLIMB, and observe two unique challenges in video data. The selection of instances to store in episodic memory is performed at the frame level. Second, untrimmed training data influences the effectiveness of frame sampling strategies. We address these two challenges by proposing a temporal consistency regularization that can be applied on top of memory-based continual learning methods. Our approach significantly improves the baseline, by up to 24% on the untrimmed continual learning task. To streamline and foster future research in video continual learning, we will publicly release the code for our benchmark and method.
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Dec 01, 2021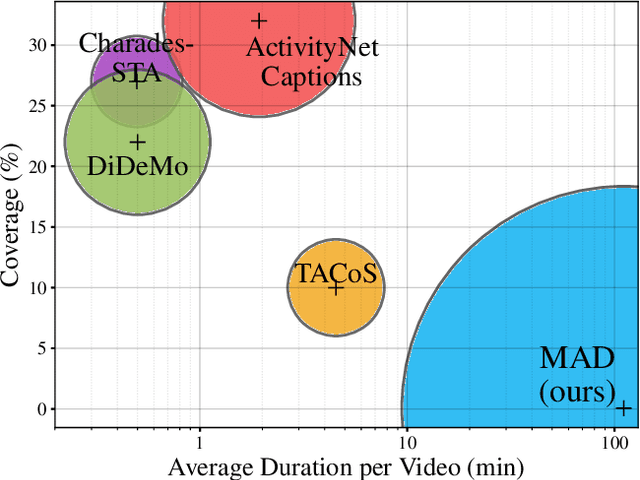
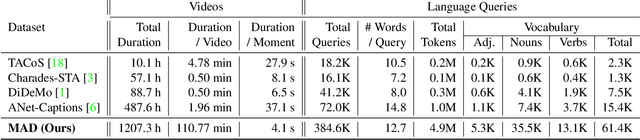


The recent and increasing interest in video-language research has driven the development of large-scale datasets that enable data-intensive machine learning techniques. In comparison, limited effort has been made at assessing the fitness of these datasets for the video-language grounding task. Recent works have begun to discover significant limitations in these datasets, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions), a novel benchmark that departs from the paradigm of augmenting existing video datasets with text annotations and focuses on crawling and aligning available audio descriptions of mainstream movies. MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD's collection strategy enables a novel and more challenging version of video-language grounding, where short temporal moments (typically seconds long) must be accurately grounded in diverse long-form videos that can last up to three hours.
MovieCuts: A New Dataset and Benchmark for Cut Type Recognition
Sep 19, 2021
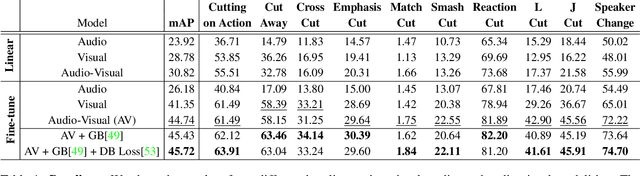

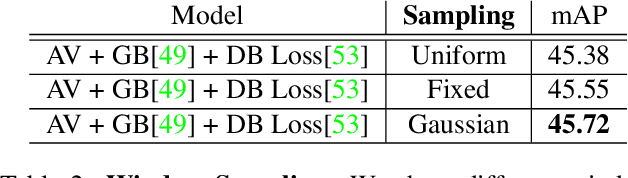
Understanding movies and their structural patterns is a crucial task to decode the craft of video editing. While previous works have developed tools for general analysis such as detecting characters or recognizing cinematography properties at the shot level, less effort has been devoted to understanding the most basic video edit, the Cut. This paper introduces the cut type recognition task, which requires modeling of multi-modal information. To ignite research in the new task, we construct a large-scale dataset called MovieCuts, which contains more than 170K videoclips labeled among ten cut types. We benchmark a series of audio-visual approaches, including some that deal with the problem's multi-modal and multi-label nature. Our best model achieves 45.7% mAP, which suggests that the task is challenging and that attaining highly accurate cut type recognition is an open research problem.
Learning to Cut by Watching Movies
Aug 09, 2021



Video content creation keeps growing at an incredible pace; yet, creating engaging stories remains challenging and requires non-trivial video editing expertise. Many video editing components are astonishingly hard to automate primarily due to the lack of raw video materials. This paper focuses on a new task for computational video editing, namely the task of raking cut plausibility. Our key idea is to leverage content that has already been edited to learn fine-grained audiovisual patterns that trigger cuts. To do this, we first collected a data source of more than 10K videos, from which we extract more than 255K cuts. We devise a model that learns to discriminate between real and artificial cuts via contrastive learning. We set up a new task and a set of baselines to benchmark video cut generation. We observe that our proposed model outperforms the baselines by large margins. To demonstrate our model in real-world applications, we conduct human studies in a collection of unedited videos. The results show that our model does a better job at cutting than random and alternative baselines.