 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation
Jan 21, 2026Medical vision-language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present CURE, an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE fine-tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance, emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.37 IoU, boosts report quality by +0.188 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure
Towards Faster and More Compact Foundation Models for Molecular Property Prediction
Apr 28, 2025Advancements in machine learning for molecular property prediction have improved accuracy but at the expense of higher computational cost and longer training times. Recently, the Joint Multi-domain Pre-training (JMP) foundation model has demonstrated strong performance across various downstream tasks with reduced training time over previous models. Despite JMP's advantages, fine-tuning it on molecular datasets ranging from small-scale to large-scale requires considerable time and computational resources. In this work, we investigate strategies to enhance efficiency by reducing model size while preserving performance. To better understand the model's efficiency, we analyze the layer contributions of JMP and find that later interaction blocks provide diminishing returns, suggesting an opportunity for model compression. We explore block reduction strategies by pruning the pre-trained model and evaluating its impact on efficiency and accuracy during fine-tuning. Our analysis reveals that removing two interaction blocks results in a minimal performance drop, reducing the model size by 32% while increasing inference throughput by 1.3x. These results suggest that JMP-L is over-parameterized and that a smaller, more efficient variant can achieve comparable performance with lower computational cost. Our study provides insights for developing lighter, faster, and more scalable foundation models for molecular and materials discovery. The code is publicly available at: https://github.com/Yasir-Ghunaim/efficient-jmp.
EAGLE: Enhanced Visual Grounding Minimizes Hallucinations in Instructional Multimodal Models
Jan 06, 2025Large language models and vision transformers have demonstrated impressive zero-shot capabilities, enabling significant transferability in downstream tasks. The fusion of these models has resulted in multi-modal architectures with enhanced instructional capabilities. Despite incorporating vast image and language pre-training, these multi-modal architectures often generate responses that deviate from the ground truth in the image data. These failure cases are known as hallucinations. Current methods for mitigating hallucinations generally focus on regularizing the language component, improving the fusion module, or ensembling multiple visual encoders to improve visual representation. In this paper, we address the hallucination issue by directly enhancing the capabilities of the visual component. Our approach, named EAGLE, is fully agnostic to the LLM or fusion module and works as a post-pretraining approach that improves the grounding and language alignment of the visual encoder. We show that a straightforward reformulation of the original contrastive pre-training task results in an improved visual encoder that can be incorporated into the instructional multi-modal architecture without additional instructional training. As a result, EAGLE achieves a significant reduction in hallucinations across multiple challenging benchmarks and tasks.
Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
Dec 03, 2023



Large Vision and Language Models have enabled significant advances in fully supervised and zero-shot vision tasks. These large pre-trained architectures serve as the baseline to what is currently known as Instruction Tuning Large Vision and Language models (IT-LVLMs). IT-LVLMs are general-purpose multi-modal assistants whose responses are modulated by natural language instructions and arbitrary visual data. Despite this versatility, IT-LVLM effectiveness in fundamental computer vision problems remains unclear, primarily due to the absence of a standardized evaluation benchmark. This paper introduces a Multi-modal Evaluation Benchmark named MERLIM, a scalable test-bed to assess the performance of IT-LVLMs on fundamental computer vision tasks. MERLIM contains over 279K image-question pairs, and has a strong focus on detecting cross-modal "hallucination" events in IT-LVLMs, where the language output refers to visual concepts that lack any effective grounding in the image. Our results show that state-of-the-art IT-LVMLs are still limited at identifying fine-grained visual concepts, object hallucinations are common across tasks, and their results are strongly biased by small variations in the input query, even if the queries have the very same semantics. Our findings also suggest that these models have weak visual groundings but they can still make adequate guesses by global visual patterns or textual biases contained in the LLM component.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
vCLIMB: A Novel Video Class Incremental Learning Benchmark
Jan 23, 2022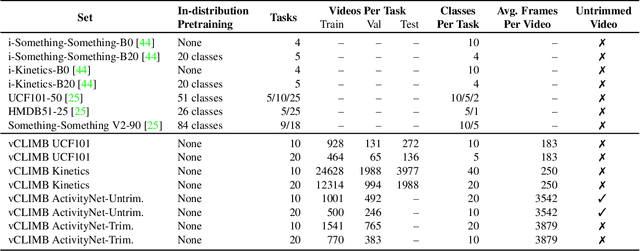
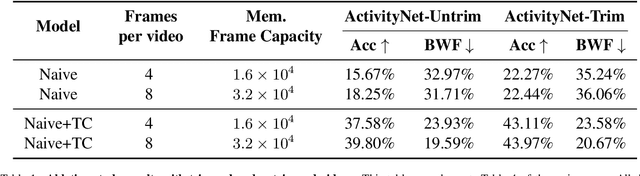
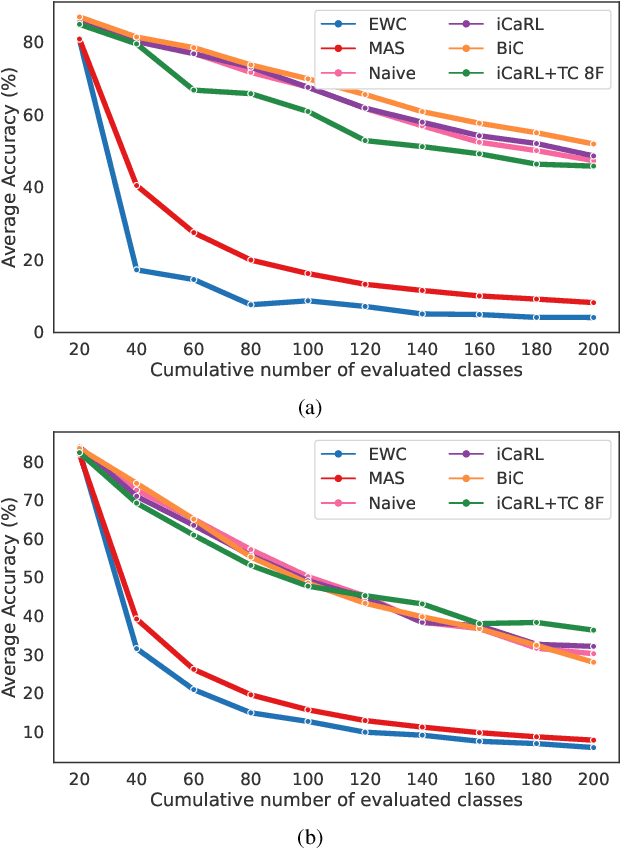
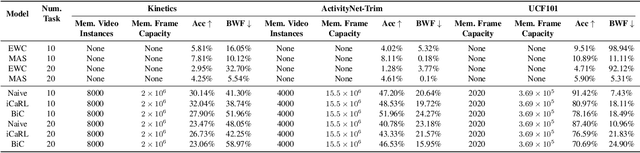
Continual learning (CL) is under-explored in the video domain. The few existing works contain splits with imbalanced class distributions over the tasks, or study the problem in unsuitable datasets. We introduce vCLIMB, a novel video continual learning benchmark. vCLIMB is a standardized test-bed to analyze catastrophic forgetting of deep models in video continual learning. In contrast to previous work, we focus on class incremental continual learning with models trained on a sequence of disjoint tasks, and distribute the number of classes uniformly across the tasks. We perform in-depth evaluations of existing CL methods in vCLIMB, and observe two unique challenges in video data. The selection of instances to store in episodic memory is performed at the frame level. Second, untrimmed training data influences the effectiveness of frame sampling strategies. We address these two challenges by proposing a temporal consistency regularization that can be applied on top of memory-based continual learning methods. Our approach significantly improves the baseline, by up to 24% on the untrimmed continual learning task. To streamline and foster future research in video continual learning, we will publicly release the code for our benchmark and method.
Augmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations
Sep 10, 2021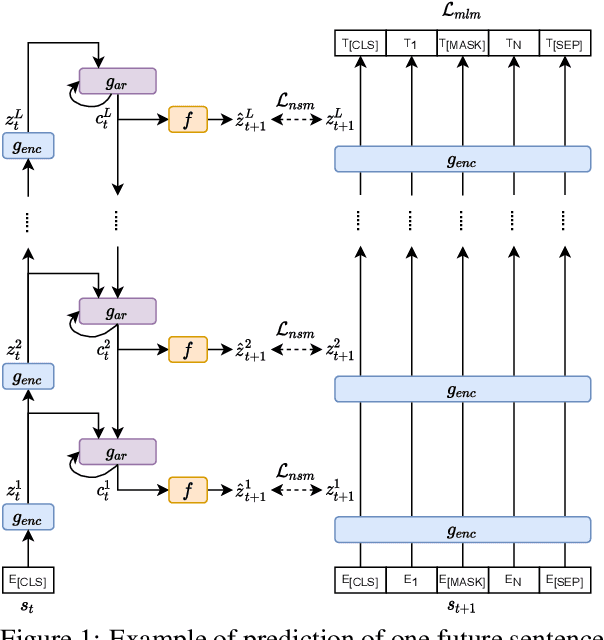
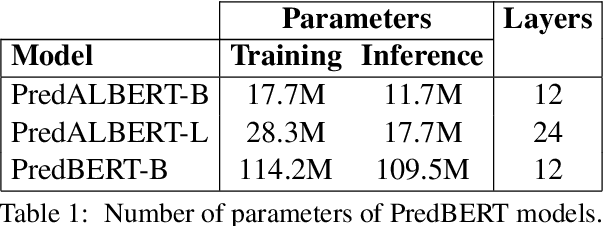
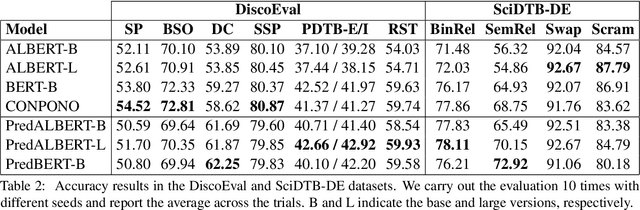
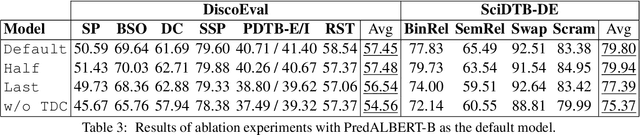
Current language models are usually trained using a self-supervised scheme, where the main focus is learning representations at the word or sentence level. However, there has been limited progress in generating useful discourse-level representations. In this work, we propose to use ideas from predictive coding theory to augment BERT-style language models with a mechanism that allows them to learn suitable discourse-level representations. As a result, our proposed approach is able to predict future sentences using explicit top-down connections that operate at the intermediate layers of the network. By experimenting with benchmarks designed to evaluate discourse-related knowledge using pre-trained sentence representations, we demonstrate that our approach improves performance in 6 out of 11 tasks by excelling in discourse relationship detection.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021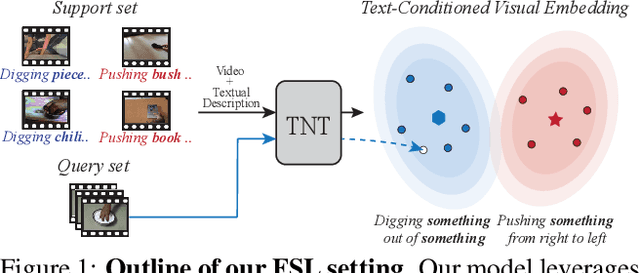
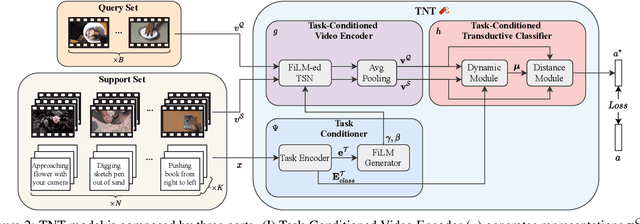
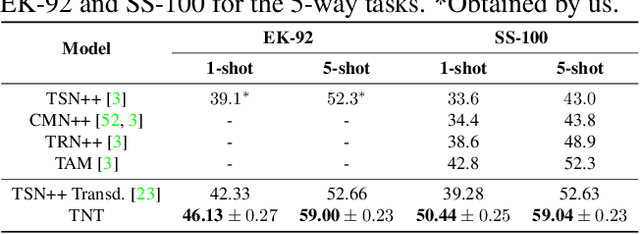
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Interpretable Contextual Team-aware Item Recommendation: Application in Multiplayer Online Battle Arena Games
Jul 30, 2020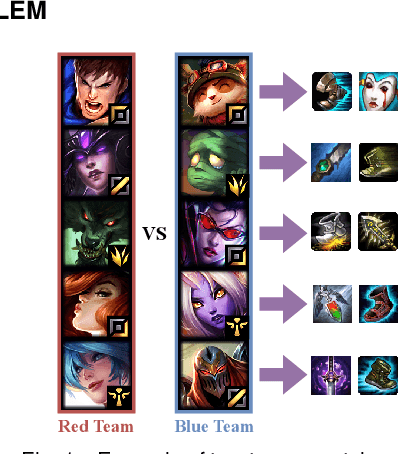
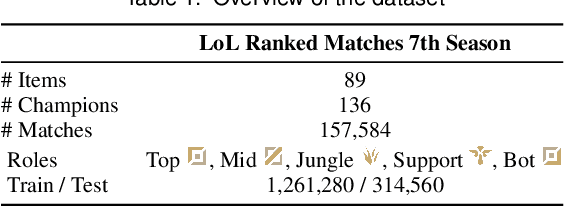
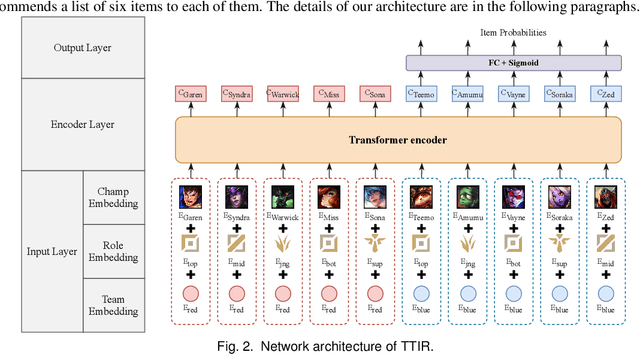
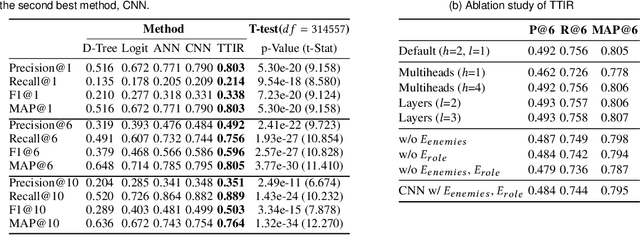
The video game industry has adopted recommendation systems to boost users interest with a focus on game sales. Other exciting applications within video games are those that help the player make decisions that would maximize their playing experience, which is a desirable feature in real-time strategy video games such as Multiplayer Online Battle Arena (MOBA) like as DotA and LoL. Among these tasks, the recommendation of items is challenging, given both the contextual nature of the game and how it exposes the dependence on the formation of each team. Existing works on this topic do not take advantage of all the available contextual match data and dismiss potentially valuable information. To address this problem we develop TTIR, a contextual recommender model derived from the Transformer neural architecture that suggests a set of items to every team member, based on the contexts of teams and roles that describe the match. TTIR outperforms several approaches and provides interpretable recommendations through visualization of attention weights. Our evaluation indicates that both the Transformer architecture and the contextual information are essential to get the best results for this item recommendation task. Furthermore, a preliminary user survey indicates the usefulness of attention weights for explaining recommendations as well as ideas for future work. The code and dataset are available at: https://github.com/ojedaf/IC-TIR-Lol.