 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Layer Relevance in Large Language Models Beyond Cosine Similarity
May 13, 2026Large language models (LLMs) have revolutionized natural language processing. Understanding their internal mechanisms is crucial for developing more interpretable and optimized architectures. Mechanistic interpretability has led to the development of various methods for assessing layer relevance, with cosine similarity being a widely used tool in the field. On this work, we demonstrate that cosine similarity is a poor proxy for the actual performance degradation caused by layer removal. Our theoretical analysis shows that a layer can exhibit an arbitrarily low cosine similarity score while still being crucial to the model's performance. On the other hand, empirical evidence from a range of LLMs confirms that the correlation between cosine similarity and actual performance degradation is often weak or moderate, leading to misleading interpretations of a transformer's internal mechanisms. We propose a more robust metric for assessing layer relevance: the actual drop in model accuracy resulting from the removal of a layer. Even though it is a computationally costly metric, this approach offers a more accurate picture of layer importance, allowing for more informed pruning strategies and lightweight models. Our findings have significant implications for the development of interpretable LLMs and highlight the need to move beyond cosine similarity in assessing layer relevance.
* Published at ICLR 2026
ViT-Explainer: An Interactive Walkthrough of the Vision Transformer Pipeline
Apr 02, 2026Transformer-based architectures have become the shared backbone of natural language processing and computer vision. However, understanding how these models operate remains challenging, particularly in vision settings, where images are processed as sequences of patch tokens. Existing interpretability tools often focus on isolated components or expert-oriented analysis, leaving a gap in guided, end-to-end understanding of the full inference pipeline. To bridge this gap, we present ViT-Explainer, a web-based interactive system that provides an integrated visualization of Vision Transformer inference, from patch tokenization to final classification. The system combines animated walkthroughs, patch-level attention overlays, and a vision-adapted Logit Lens within both guided and free exploration modes. A user study with six participants suggests that ViT-Explainer is easy to learn and use, helping users interpret and understand Vision Transformer behavior.
Seeing to Generalize: How Visual Data Corrects Binding Shortcuts
Feb 16, 2026Vision Language Models (VLMs) are designed to extend Large Language Models (LLMs) with visual capabilities, yet in this work we observe a surprising phenomenon: VLMs can outperform their underlying LLMs on purely text-only tasks, particularly in long-context information retrieval. To investigate this effect, we build a controlled synthetic retrieval task and find that a transformer trained only on text achieves perfect in-distribution accuracy but fails to generalize out of distribution, while subsequent training on an image-tokenized version of the same task nearly doubles text-only OOD performance. Mechanistic interpretability reveals that visual training changes the model's internal binding strategy: text-only training encourages positional shortcuts, whereas image-based training disrupts them through spatial translation invariance, forcing the model to adopt a more robust symbolic binding mechanism that persists even after text-only examples are reintroduced. We further characterize how binding strategies vary across training regimes, visual encoders, and initializations, and show that analogous shifts occur during pretrained LLM-to-VLM transitions. Our findings suggest that cross-modal training can enhance reasoning and generalization even for tasks grounded in a single modality.
CURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation
Jan 21, 2026Medical vision-language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present CURE, an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE fine-tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance, emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.37 IoU, boosts report quality by +0.188 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure
Perceptual Evaluation of GANs and Diffusion Models for Generating X-rays
Aug 10, 2025
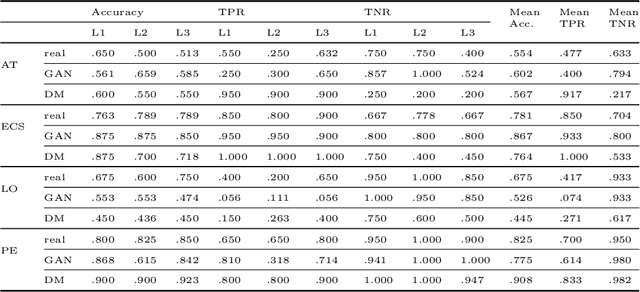
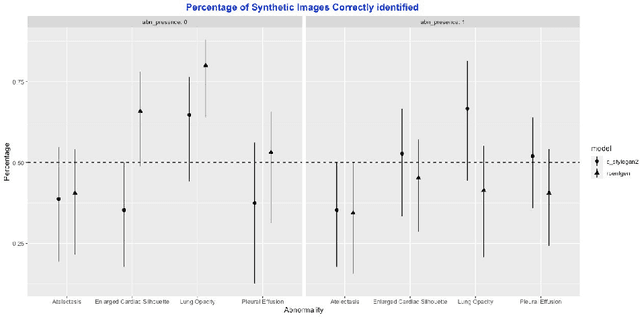
Generative image models have achieved remarkable progress in both natural and medical imaging. In the medical context, these techniques offer a potential solution to data scarcity-especially for low-prevalence anomalies that impair the performance of AI-driven diagnostic and segmentation tools. However, questions remain regarding the fidelity and clinical utility of synthetic images, since poor generation quality can undermine model generalizability and trust. In this study, we evaluate the effectiveness of state-of-the-art generative models-Generative Adversarial Networks (GANs) and Diffusion Models (DMs)-for synthesizing chest X-rays conditioned on four abnormalities: Atelectasis (AT), Lung Opacity (LO), Pleural Effusion (PE), and Enlarged Cardiac Silhouette (ECS). Using a benchmark composed of real images from the MIMIC-CXR dataset and synthetic images from both GANs and DMs, we conducted a reader study with three radiologists of varied experience. Participants were asked to distinguish real from synthetic images and assess the consistency between visual features and the target abnormality. Our results show that while DMs generate more visually realistic images overall, GANs can report better accuracy for specific conditions, such as absence of ECS. We further identify visual cues radiologists use to detect synthetic images, offering insights into the perceptual gaps in current models. These findings underscore the complementary strengths of GANs and DMs and point to the need for further refinement to ensure generative models can reliably augment training datasets for AI diagnostic systems.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
A Comunication Framework for Compositional Generation
Jan 31, 2025Compositionality and compositional generalization--the ability to understand novel combinations of known concepts--are central characteristics of human language and are hypothesized to be essential for human cognition. In machine learning, the emergence of this property has been studied in a communication game setting, where independent agents (a sender and a receiver) converge to a shared encoding policy from a set of states to a space of discrete messages, where the receiver can correctly reconstruct the states observed by the sender using only the sender's messages. The use of communication games in generation tasks is still largely unexplored, with recent methods for compositional generation focusing mainly on the use of supervised guidance (either through class labels or text). In this work, we take the first steps to fill this gap, and we present a self-supervised generative communication game-based framework for creating compositional encodings in learned representations from pre-trained encoder-decoder models. In an Iterated Learning (IL) protocol involving a sender and a receiver, we apply alternating pressures for compression and diversity of encoded discrete messages, so that the protocol converges to an efficient but unambiguous encoding. Approximate message entropy regularization is used to favor compositional encodings. Our framework is based on rigorous justifications and proofs of defining and balancing the concepts of Eficiency, Unambiguity and Non-Holisticity in encoding. We test our method on the compositional image dataset Shapes3D, demonstrating robust performance in both reconstruction and compositionality metrics, surpassing other tested discrete message frameworks.
Extracting and Encoding: Leveraging Large Language Models and Medical Knowledge to Enhance Radiological Text Representation
Jul 02, 2024
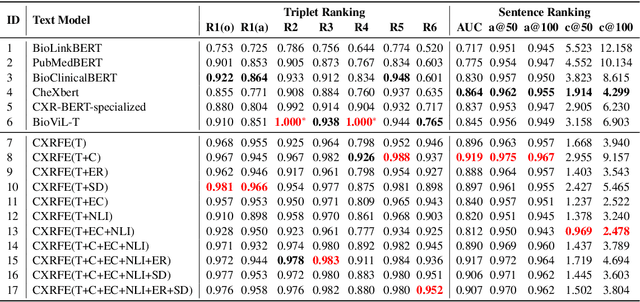
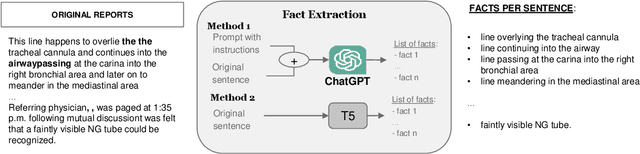
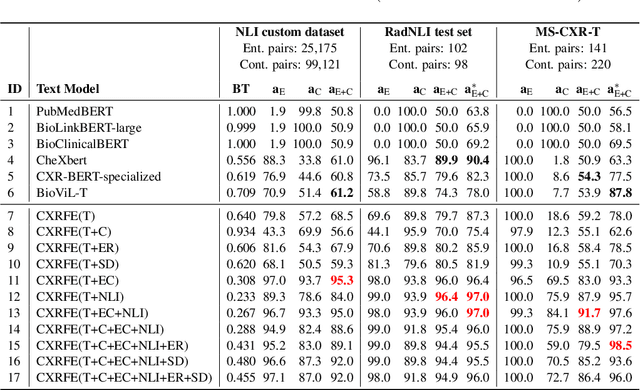
Advancing representation learning in specialized fields like medicine remains challenging due to the scarcity of expert annotations for text and images. To tackle this issue, we present a novel two-stage framework designed to extract high-quality factual statements from free-text radiology reports in order to improve the representations of text encoders and, consequently, their performance on various downstream tasks. In the first stage, we propose a \textit{Fact Extractor} that leverages large language models (LLMs) to identify factual statements from well-curated domain-specific datasets. In the second stage, we introduce a \textit{Fact Encoder} (CXRFE) based on a BERT model fine-tuned with objective functions designed to improve its representations using the extracted factual data. Our framework also includes a new embedding-based metric (CXRFEScore) for evaluating chest X-ray text generation systems, leveraging both stages of our approach. Extensive evaluations show that our fact extractor and encoder outperform current state-of-the-art methods in tasks such as sentence ranking, natural language inference, and label extraction from radiology reports. Additionally, our metric proves to be more robust and effective than existing metrics commonly used in the radiology report generation literature. The code of this project is available at \url{https://github.com/PabloMessina/CXR-Fact-Encoder}.
Long Tail Image Generation Through Feature Space Augmentation and Iterated Learning
May 02, 2024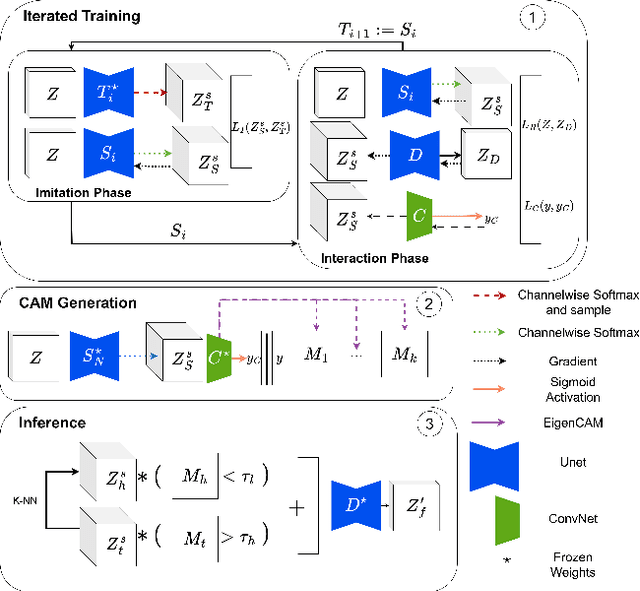
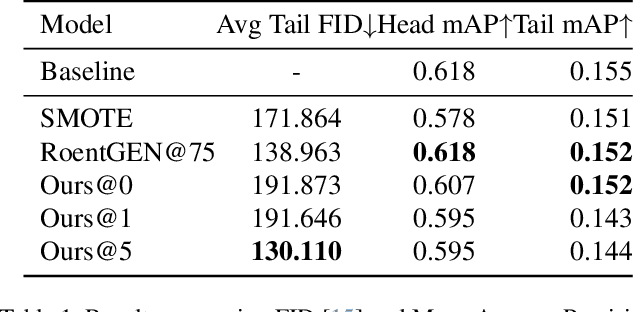
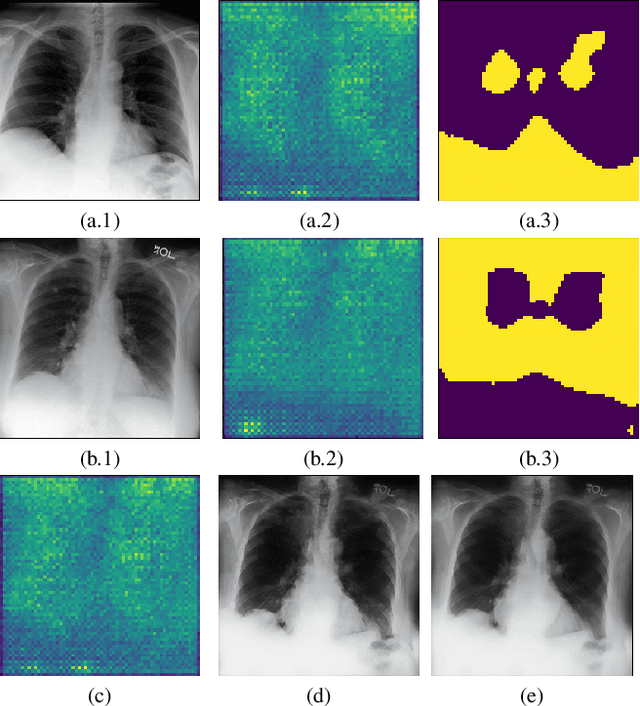
Image and multimodal machine learning tasks are very challenging to solve in the case of poorly distributed data. In particular, data availability and privacy restrictions exacerbate these hurdles in the medical domain. The state of the art in image generation quality is held by Latent Diffusion models, making them prime candidates for tackling this problem. However, a few key issues still need to be solved, such as the difficulty in generating data from under-represented classes and a slow inference process. To mitigate these issues, we propose a new method for image augmentation in long-tailed data based on leveraging the rich latent space of pre-trained Stable Diffusion Models. We create a modified separable latent space to mix head and tail class examples. We build this space via Iterated Learning of underlying sparsified embeddings, which we apply to task-specific saliency maps via a K-NN approach. Code is available at https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning
Towards a Comprehensive Human-Centred Evaluation Framework for Explainable AI
Jul 31, 2023While research on explainable AI (XAI) is booming and explanation techniques have proven promising in many application domains, standardised human-centred evaluation procedures are still missing. In addition, current evaluation procedures do not assess XAI methods holistically in the sense that they do not treat explanations' effects on humans as a complex user experience. To tackle this challenge, we propose to adapt the User-Centric Evaluation Framework used in recommender systems: we integrate explanation aspects, summarise explanation properties, indicate relations between them, and categorise metrics that measure these properties. With this comprehensive evaluation framework, we hope to contribute to the human-centred standardisation of XAI evaluation.