 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting state of the art performance and NLP metrics in image-based medical report generation
Nov 21, 2020
Several deep learning architectures have been proposed over the last years to deal with the problem of generating a written report given an imaging exam as input. Most works evaluate the generated reports using standard Natural Language Processing (NLP) metrics (e.g. BLEU, ROUGE), reporting significant progress. In this article, we contrast this progress by comparing state of the art (SOTA) models against weak baselines. We show that simple and even naive approaches yield near SOTA performance on most traditional NLP metrics. We conclude that evaluation methods in this task should be further studied towards correctly measuring clinical accuracy, ideally involving physicians to contribute to this end.
A Survey on Deep Learning and Explainability for Automatic Image-based Medical Report Generation
Oct 20, 2020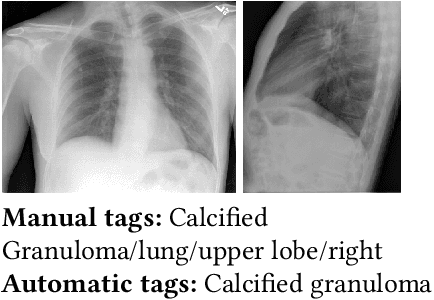
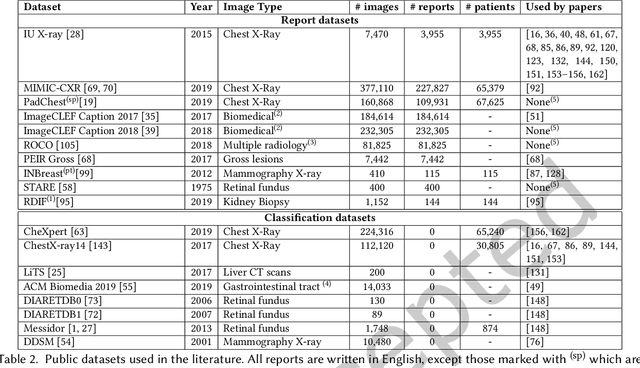
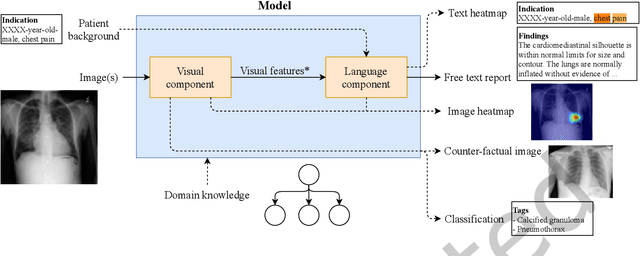
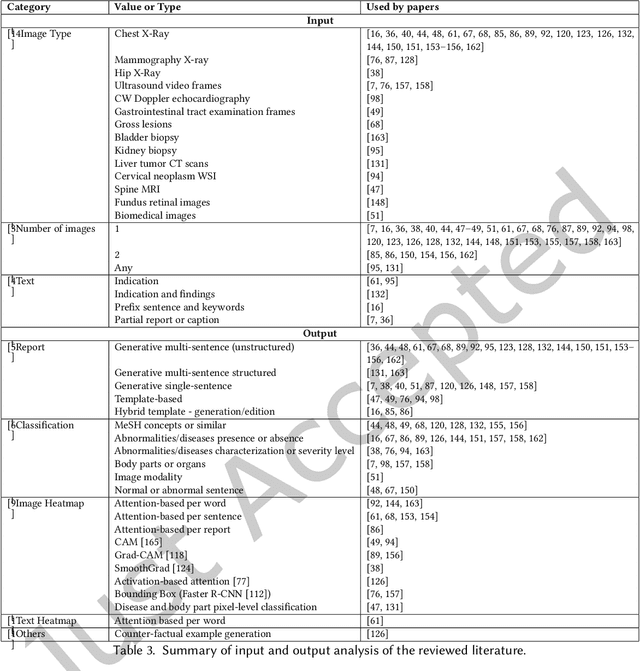
Every year physicians face an increasing demand of image-based diagnosis from patients, a problem that can be addressed with recent artificial intelligence methods. In this context, we survey works in the area of automatic report generation from medical images, with emphasis on methods using deep neural networks, with respect to: (1) Datasets, (2) Architecture Design, (3) Explainability and (4) Evaluation Metrics. Our survey identifies interesting developments, but also remaining challenges. Among them, the current evaluation of generated reports is especially weak, since it mostly relies on traditional Natural Language Processing (NLP) metrics, which do not accurately capture medical correctness.