 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation
Jan 21, 2026Medical vision-language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present CURE, an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE fine-tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance, emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.37 IoU, boosts report quality by +0.188 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
IP-CRR: Information Pursuit for Interpretable Classification of Chest Radiology Reports
Apr 30, 2025The development of AI-based methods for analyzing radiology reports could lead to significant advances in medical diagnosis--from improving diagnostic accuracy to enhancing efficiency and reducing workload. However, the lack of interpretability in these methods has hindered their adoption in clinical settings. In this paper, we propose an interpretable-by-design framework for classifying radiology reports. The key idea is to extract a set of most informative queries from a large set of reports and use these queries and their corresponding answers to predict a diagnosis. Thus, the explanation for a prediction is, by construction, the set of selected queries and answers. We use the Information Pursuit framework to select informative queries, the Flan-T5 model to determine if facts are present in the report, and a classifier to predict the disease. Experiments on the MIMIC-CXR dataset demonstrate the effectiveness of the proposed method, highlighting its potential to enhance trust and usability in medical AI.
Extracting and Encoding: Leveraging Large Language Models and Medical Knowledge to Enhance Radiological Text Representation
Jul 02, 2024
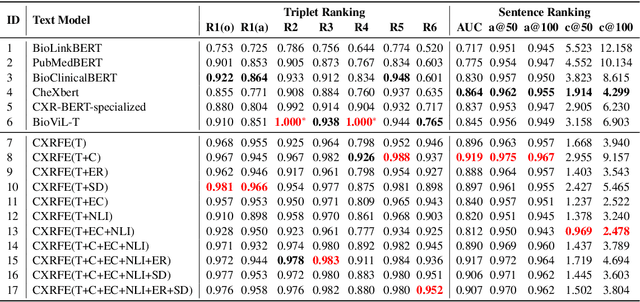
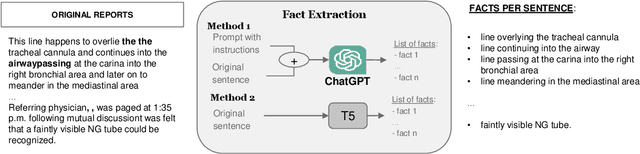
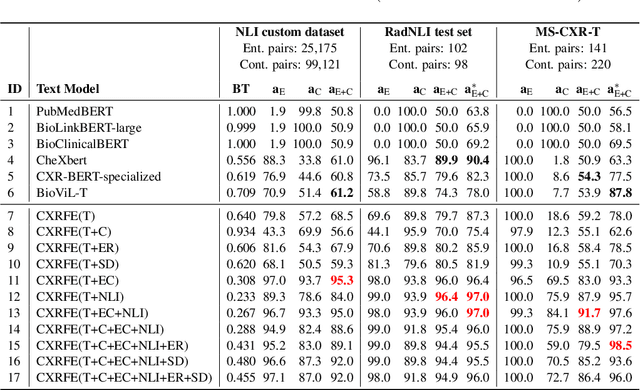
Advancing representation learning in specialized fields like medicine remains challenging due to the scarcity of expert annotations for text and images. To tackle this issue, we present a novel two-stage framework designed to extract high-quality factual statements from free-text radiology reports in order to improve the representations of text encoders and, consequently, their performance on various downstream tasks. In the first stage, we propose a \textit{Fact Extractor} that leverages large language models (LLMs) to identify factual statements from well-curated domain-specific datasets. In the second stage, we introduce a \textit{Fact Encoder} (CXRFE) based on a BERT model fine-tuned with objective functions designed to improve its representations using the extracted factual data. Our framework also includes a new embedding-based metric (CXRFEScore) for evaluating chest X-ray text generation systems, leveraging both stages of our approach. Extensive evaluations show that our fact extractor and encoder outperform current state-of-the-art methods in tasks such as sentence ranking, natural language inference, and label extraction from radiology reports. Additionally, our metric proves to be more robust and effective than existing metrics commonly used in the radiology report generation literature. The code of this project is available at \url{https://github.com/PabloMessina/CXR-Fact-Encoder}.
Inspecting state of the art performance and NLP metrics in image-based medical report generation
Nov 21, 2020
Several deep learning architectures have been proposed over the last years to deal with the problem of generating a written report given an imaging exam as input. Most works evaluate the generated reports using standard Natural Language Processing (NLP) metrics (e.g. BLEU, ROUGE), reporting significant progress. In this article, we contrast this progress by comparing state of the art (SOTA) models against weak baselines. We show that simple and even naive approaches yield near SOTA performance on most traditional NLP metrics. We conclude that evaluation methods in this task should be further studied towards correctly measuring clinical accuracy, ideally involving physicians to contribute to this end.
A Survey on Deep Learning and Explainability for Automatic Image-based Medical Report Generation
Oct 20, 2020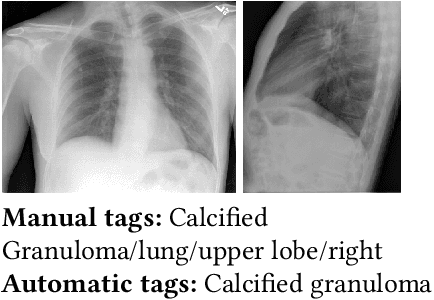
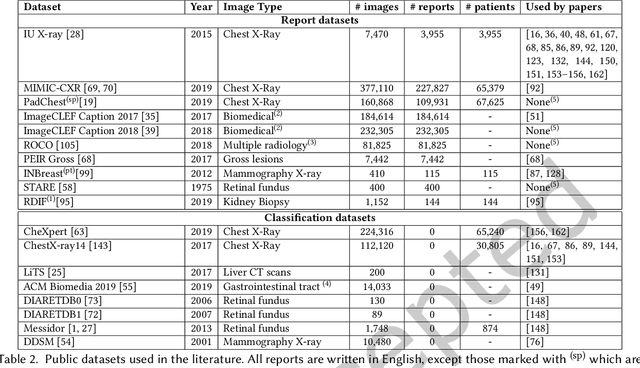
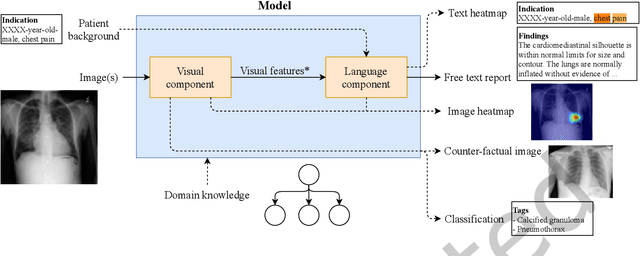
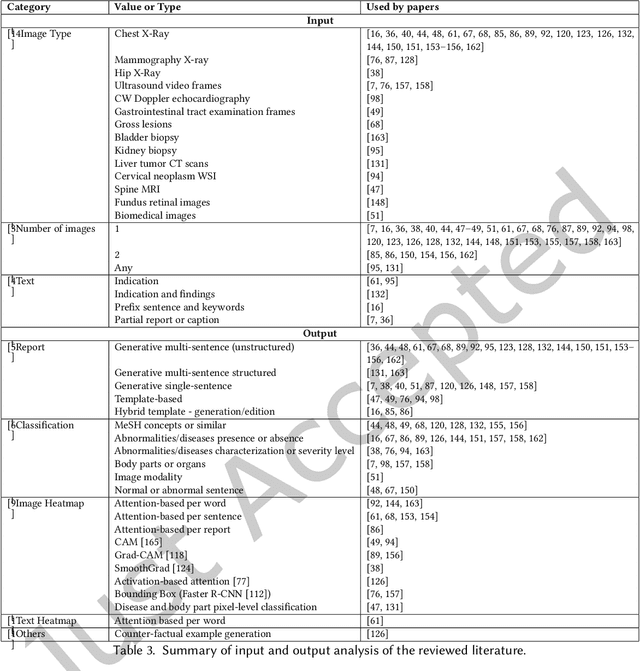
Every year physicians face an increasing demand of image-based diagnosis from patients, a problem that can be addressed with recent artificial intelligence methods. In this context, we survey works in the area of automatic report generation from medical images, with emphasis on methods using deep neural networks, with respect to: (1) Datasets, (2) Architecture Design, (3) Explainability and (4) Evaluation Metrics. Our survey identifies interesting developments, but also remaining challenges. Among them, the current evaluation of generated reports is especially weak, since it mostly relies on traditional Natural Language Processing (NLP) metrics, which do not accurately capture medical correctness.
CuratorNet: Visually-aware Recommendation of Art Images
Sep 30, 2020
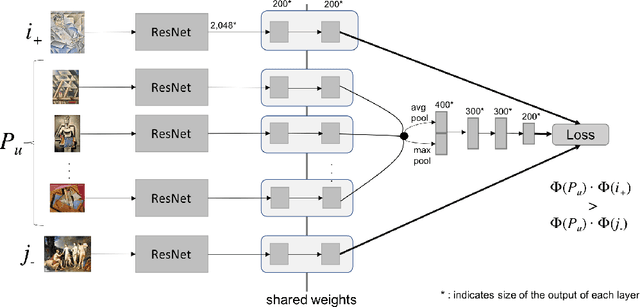

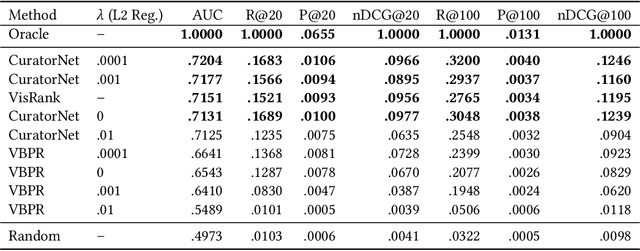
Although there are several visually-aware recommendation models in domains like fashion or even movies, the art domain lacks thesame level of research attention, despite the recent growth of the online artwork market. To reduce this gap, in this article we introduceCuratorNet, a neural network architecture for visually-aware recommendation of art images. CuratorNet is designed at the core withthe goal of maximizing generalization: the network has a fixed set of parameters that only need to be trained once, and thereafter themodel is able to generalize to new users or items never seen before, without further training. This is achieved by leveraging visualcontent: items are mapped to item vectors through visual embeddings, and users are mapped to user vectors by aggregating the visualcontent of items they have consumed. Besides the model architecture, we also introduce novel triplet sampling strategies to build atraining set for rank learning in the art domain, resulting in more effective learning than naive random sampling. With an evaluationover a real-world dataset of physical paintings, we show that CuratorNet achieves the best performance among several baselines,including the state-of-the-art model VBPR. CuratorNet is motivated and evaluated in the art domain, but its architecture and trainingscheme could be adapted to recommend images in other areas
Do Better ImageNet Models Transfer Better for Image Recommendation?
Sep 25, 2018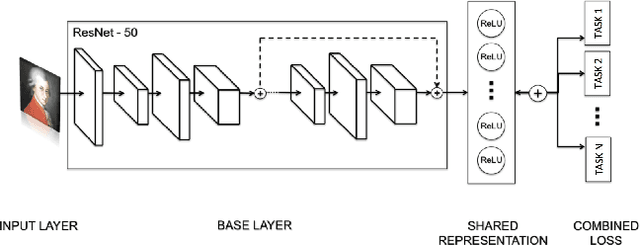
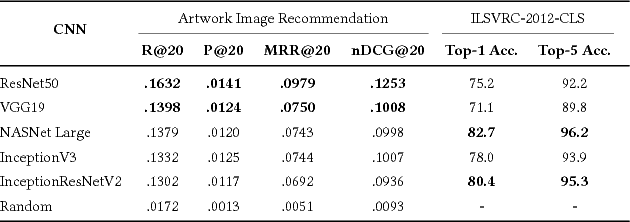
Visual embeddings from Convolutional Neural Networks (CNN) trained on the ImageNet dataset for the ILSVRC challenge have shown consistently good performance for transfer learning and are widely used in several tasks, including image recommendation. However, some important questions have not yet been answered in order to use these embeddings for a larger scope of recommendation domains: a) Do CNNs that perform better in ImageNet are also better for transfer learning in content-based image recommendation?, b) Does fine-tuning help to improve performance? and c) Which is the best way to perform the fine-tuning? In this paper we compare several CNN models pre-trained with ImageNet to evaluate their transfer learning performance to an artwork image recommendation task. Our results indicate that models with better performance in the ImageNet challenge do not always imply better transfer learning for recommendation tasks (e.g. NASNet vs. ResNet). Our results also show that fine-tuning can be helpful even with a small dataset, but not every fine-tuning works. Our results can inform other researchers and practitioners on how to train their CNNs for better transfer learning towards image recommendation systems.
Exploring Content-based Artwork Recommendation with Metadata and Visual Features
Oct 23, 2017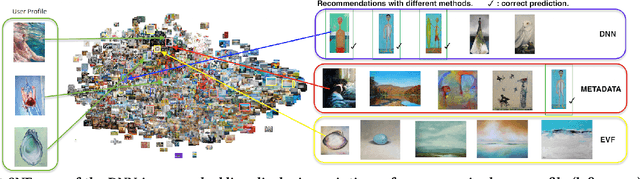
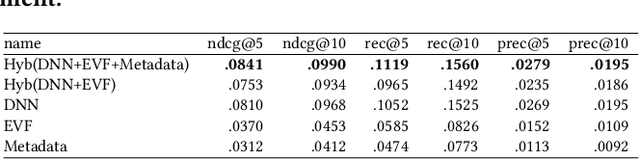
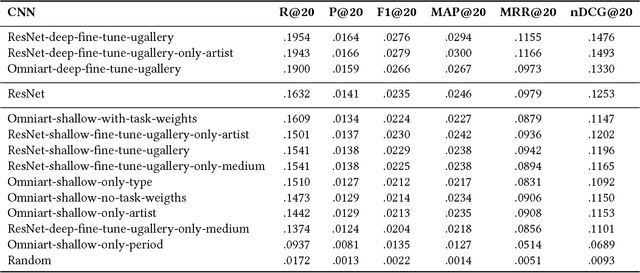
Compared to other areas, artwork recommendation has received little attention, despite the continuous growth of the artwork market. Previous research has relied on ratings and metadata to make artwork recommendations, as well as visual features extracted with deep neural networks (DNN). However, these features have no direct interpretation to explicit visual features (e.g. brightness, texture) which might hinder explainability and user-acceptance. In this work, we study the impact of artwork metadata as well as visual features (DNN-based and attractiveness-based) for physical artwork recommendation, using images and transaction data from the UGallery online artwork store. Our results indicate that: (i) visual features perform better than manually curated data, (ii) DNN-based visual features perform better than attractiveness-based ones, and (iii) a hybrid approach improves the performance further. Our research can inform the development of new artwork recommenders relying on diverse content data.
Comparing Neural and Attractiveness-based Visual Features for Artwork Recommendation
Jul 21, 2017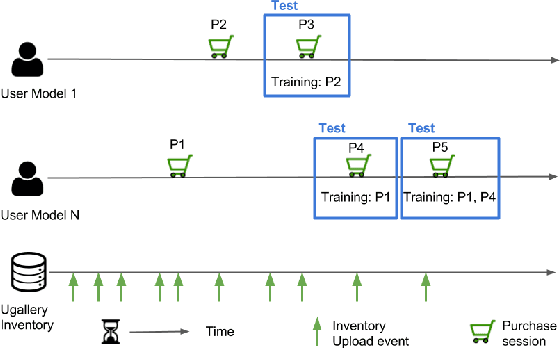
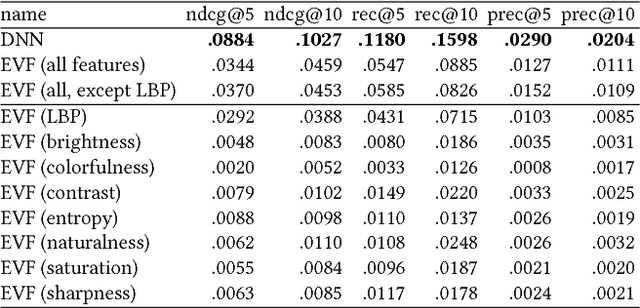

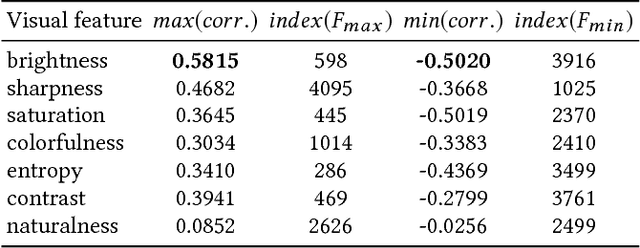
Advances in image processing and computer vision in the latest years have brought about the use of visual features in artwork recommendation. Recent works have shown that visual features obtained from pre-trained deep neural networks (DNNs) perform very well for recommending digital art. Other recent works have shown that explicit visual features (EVF) based on attractiveness can perform well in preference prediction tasks, but no previous work has compared DNN features versus specific attractiveness-based visual features (e.g. brightness, texture) in terms of recommendation performance. In this work, we study and compare the performance of DNN and EVF features for the purpose of physical artwork recommendation using transactional data from UGallery, an online store of physical paintings. In addition, we perform an exploratory analysis to understand if DNN embedded features have some relation with certain EVF. Our results show that DNN features outperform EVF, that certain EVF features are more suited for physical artwork recommendation and, finally, we show evidence that certain neurons in the DNN might be partially encoding visual features such as brightness, providing an opportunity for explaining recommendations based on visual neural models.