 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustSkin: A Fairness Pipeline for Trustworthy Facial Affect Analysis Across Skin Tone
May 27, 2025Understanding how facial affect analysis (FAA) systems perform across different demographic groups requires reliable measurement of sensitive attributes such as ancestry, often approximated by skin tone, which itself is highly influenced by lighting conditions. This study compares two objective skin tone classification methods: the widely used Individual Typology Angle (ITA) and a perceptually grounded alternative based on Lightness ($L^*$) and Hue ($H^*$). Using AffectNet and a MobileNet-based model, we assess fairness across skin tone groups defined by each method. Results reveal a severe underrepresentation of dark skin tones ($\sim 2 \%$), alongside fairness disparities in F1-score (up to 0.08) and TPR (up to 0.11) across groups. While ITA shows limitations due to its sensitivity to lighting, the $H^*$-$L^*$ method yields more consistent subgrouping and enables clearer diagnostics through metrics such as Equal Opportunity. Grad-CAM analysis further highlights differences in model attention patterns by skin tone, suggesting variation in feature encoding. To support future mitigation efforts, we also propose a modular fairness-aware pipeline that integrates perceptual skin tone estimation, model interpretability, and fairness evaluation. These findings emphasize the relevance of skin tone measurement choices in fairness assessment and suggest that ITA-based evaluations may overlook disparities affecting darker-skinned individuals.
* 10 pages
Use of triplet loss for facial restoration in low-resolution images
Sep 05, 2024



In recent years, facial recognition (FR) models have become the most widely used biometric tool, achieving impressive results on numerous datasets. However, inherent hardware challenges or shooting distances often result in low-resolution images, which significantly impact the performance of FR models. To address this issue, several solutions have been proposed, including super-resolution (SR) models that generate highly realistic faces. Despite these efforts, significant improvements in FR algorithms have not been achieved. We propose a novel SR model FTLGAN, which focuses on generating high-resolution images that preserve individual identities rather than merely improving image quality, thereby maximizing the performance of FR models. The results are compelling, demonstrating a mean value of d' 21% above the best current state-of-the-art models, specifically having a value of d' = 1.099 and AUC = 0.78 for 14x14 pixels, d' = 2.112 and AUC = 0.92 for 28x28 pixels, and d' = 3.049 and AUC = 0.98 for 56x56 pixels. The contributions of this study are significant in several key areas. Firstly, a notable improvement in facial recognition performance has been achieved in low-resolution images, specifically at resolutions of 14x14, 28x28, and 56x56 pixels. Secondly, the enhancements demonstrated by FTLGAN show a consistent response across all resolutions, delivering outstanding performance uniformly, unlike other comparative models. Thirdly, an innovative approach has been implemented using triplet loss logic, enabling the training of the super-resolution model solely with real images, contrasting with current models, and expanding potential real-world applications. Lastly, this study introduces a novel model that specifically addresses the challenge of improving classification performance in facial recognition systems by integrating facial recognition quality as a loss during model training.
CRAFT: Contextual Re-Activation of Filters for face recognition Training
Dec 05, 2023



The first layer of a deep CNN backbone applies filters to an image to extract the basic features available to later layers. During training, some filters may go inactive, mean ing all weights in the filter approach zero. An inactive fil ter in the final model represents a missed opportunity to extract a useful feature. This phenomenon is especially prevalent in specialized CNNs such as for face recogni tion (as opposed to, e.g., ImageNet). For example, in one the most widely face recognition model (ArcFace), about half of the convolution filters in the first layer are inactive. We propose a novel approach designed and tested specif ically for face recognition networks, known as "CRAFT: Contextual Re-Activation of Filters for Face Recognition Training". CRAFT identifies inactive filters during training and reinitializes them based on the context of strong filters at that stage in training. We show that CRAFT reduces fraction of inactive filters from 44% to 32% on average and discovers filter patterns not found by standard training. Compared to standard training without reactivation, CRAFT demonstrates enhanced model accuracy on standard face-recognition benchmark datasets including AgeDB-30, CPLFW, LFW, CALFW, and CFP-FP, as well as on more challenging datasets like IJBB and IJBC.
Our Deep CNN Face Matchers Have Developed Achromatopsia
Sep 11, 2023



Modern deep CNN face matchers are trained on datasets containing color images. We show that such matchers achieve essentially the same accuracy on the grayscale or the color version of a set of test images. We then consider possible causes for deep CNN face matchers ``not seeing color''. Popular web-scraped face datasets actually have 30 to 60\% of their identities with one or more grayscale images. We analyze whether this grayscale element in the training set impacts the accuracy achieved, and conclude that it does not. Further, we show that even with a 100\% grayscale training set, comparable accuracy is achieved on color or grayscale test images. Then we show that the skin region of an individual's images in a web-scraped training set exhibit significant variation in their mapping to color space. This suggests that color, at least for web-scraped, in-the-wild face datasets, carries limited identity-related information for training state-of-the-art matchers. Finally, we verify that comparable accuracy is achieved from training using single-channel grayscale images, implying that a larger dataset can be used within the same memory limit, with a less computationally intensive early layer.
Distinguishing a planetary transit from false positives: a Transformer-based classification for planetary transit signals
Apr 27, 2023Current space-based missions, such as the Transiting Exoplanet Survey Satellite (TESS), provide a large database of light curves that must be analysed efficiently and systematically. In recent years, deep learning (DL) methods, particularly convolutional neural networks (CNN), have been used to classify transit signals of candidate exoplanets automatically. However, CNNs have some drawbacks; for example, they require many layers to capture dependencies on sequential data, such as light curves, making the network so large that it eventually becomes impractical. The self-attention mechanism is a DL technique that attempts to mimic the action of selectively focusing on some relevant things while ignoring others. Models, such as the Transformer architecture, were recently proposed for sequential data with successful results. Based on these successful models, we present a new architecture for the automatic classification of transit signals. Our proposed architecture is designed to capture the most significant features of a transit signal and stellar parameters through the self-attention mechanism. In addition to model prediction, we take advantage of attention map inspection, obtaining a more interpretable DL approach. Thus, we can identify the relevance of each element to differentiate a transit signal from false positives, simplifying the manual examination of candidates. We show that our architecture achieves competitive results concerning the CNNs applied for recognizing exoplanetary transit signals in data from the TESS telescope. Based on these results, we demonstrate that applying this state-of-the-art DL model to light curves can be a powerful technique for transit signal detection while offering a level of interpretability.
Informative regularization for a multi-layer perceptron RR Lyrae classifier under data shift
Mar 12, 2023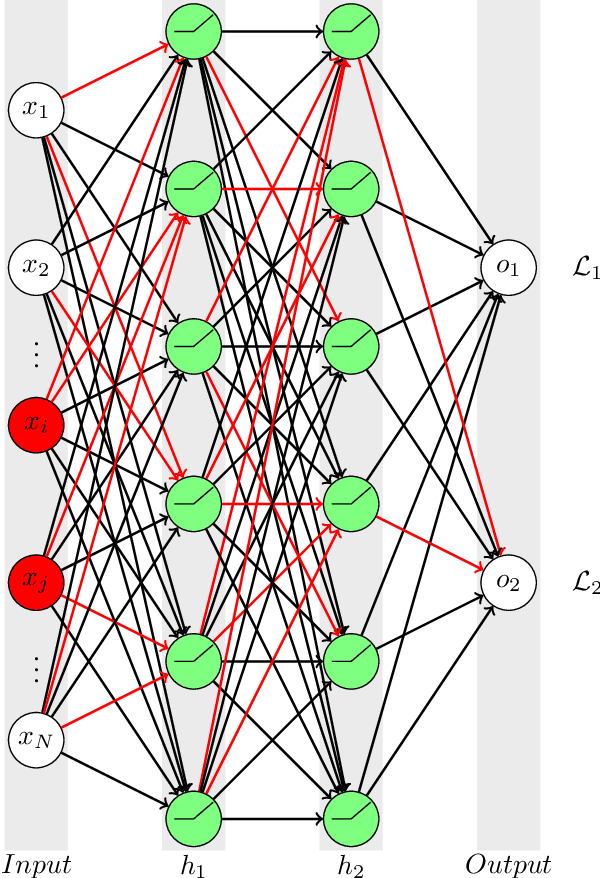
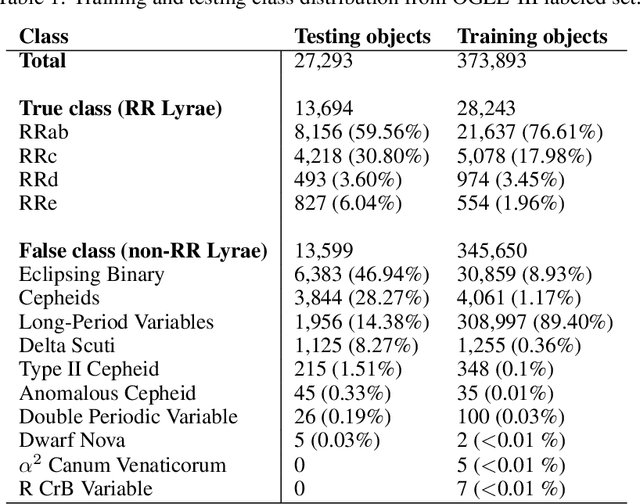
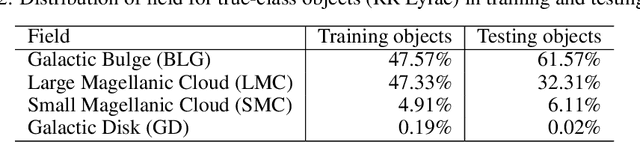
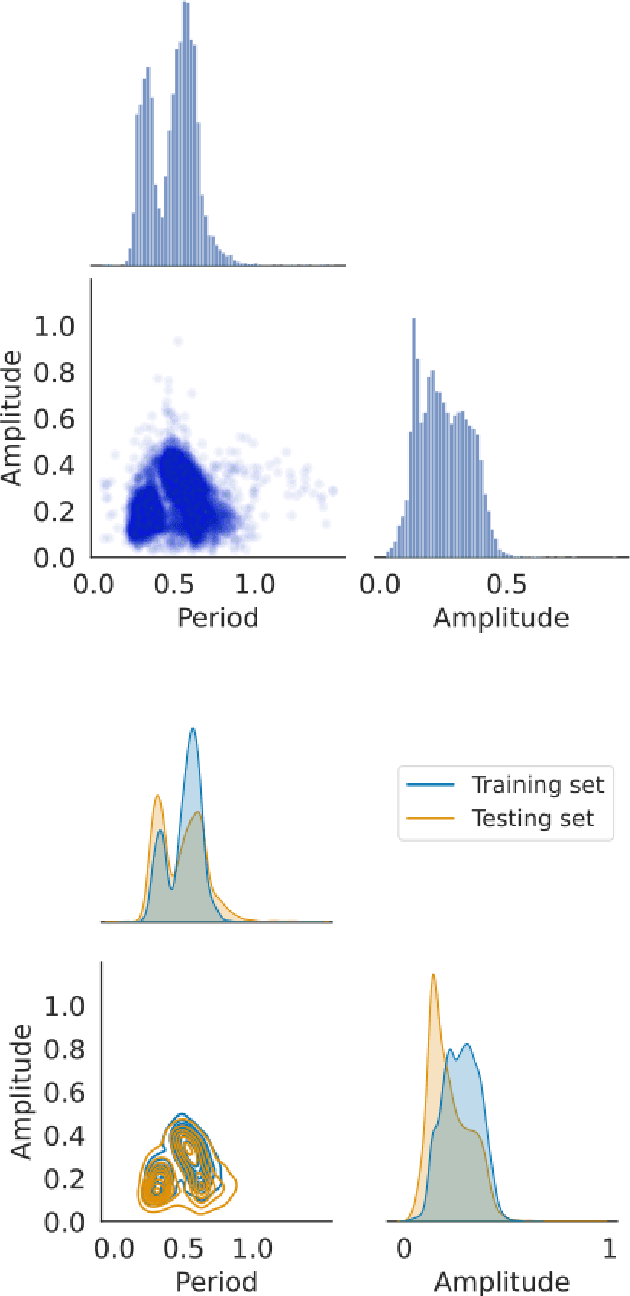
In recent decades, machine learning has provided valuable models and algorithms for processing and extracting knowledge from time-series surveys. Different classifiers have been proposed and performed to an excellent standard. Nevertheless, few papers have tackled the data shift problem in labeled training sets, which occurs when there is a mismatch between the data distribution in the training set and the testing set. This drawback can damage the prediction performance in unseen data. Consequently, we propose a scalable and easily adaptable approach based on an informative regularization and an ad-hoc training procedure to mitigate the shift problem during the training of a multi-layer perceptron for RR Lyrae classification. We collect ranges for characteristic features to construct a symbolic representation of prior knowledge, which was used to model the informative regularizer component. Simultaneously, we design a two-step back-propagation algorithm to integrate this knowledge into the neural network, whereby one step is applied in each epoch to minimize classification error, while another is applied to ensure regularization. Our algorithm defines a subset of parameters (a mask) for each loss function. This approach handles the forgetting effect, which stems from a trade-off between these loss functions (learning from data versus learning expert knowledge) during training. Experiments were conducted using recently proposed shifted benchmark sets for RR Lyrae stars, outperforming baseline models by up to 3\% through a more reliable classifier. Our method provides a new path to incorporate knowledge from characteristic features into artificial neural networks to manage the underlying data shift problem.
Identity Document to Selfie Face Matching Across Adolescence
Dec 20, 2019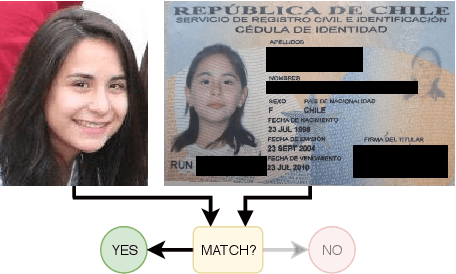
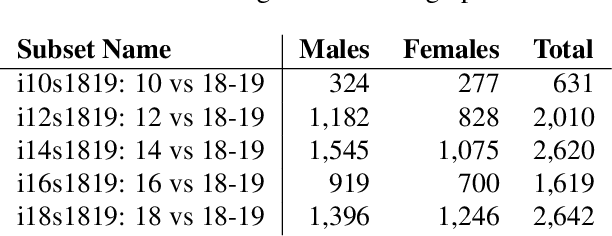
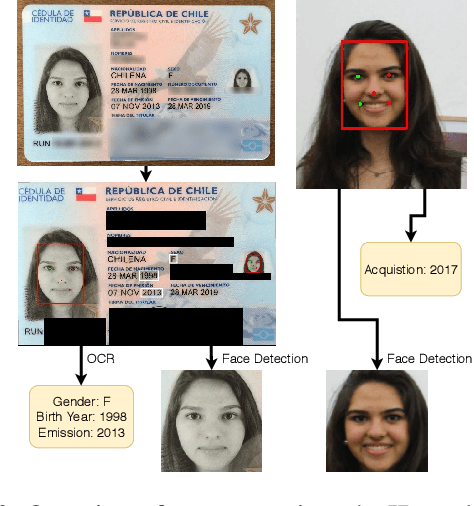
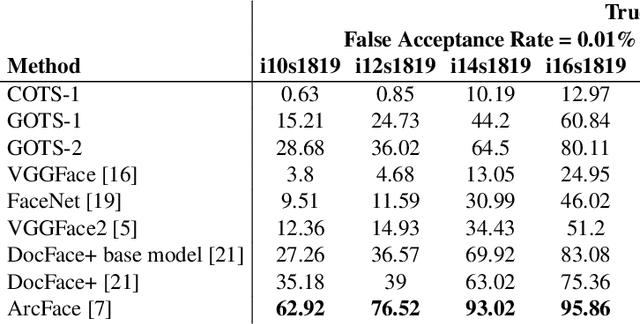
Matching live images (``selfies'') to images from ID documents is a problem that can arise in various applications. A challenging instance of the problem arises when the face image on the ID document is from early adolescence and the live image is from later adolescence. We explore this problem using a private dataset called Chilean Young Adult (CHIYA) dataset, where we match live face images taken at age 18-19 to face images on ID documents created at ages 9 to 18. State-of-the-art deep learning face matchers (e.g., ArcFace) have relatively poor accuracy for document-to-selfie face matching. To achieve higher accuracy, we fine-tune the best available open-source model with triplet loss for a few-shot learning. Experiments show that our approach achieves higher accuracy than the DocFace+ model recently developed for this problem. Our fine-tuned model was able to improve the true acceptance rate for the most difficult (largest age span) subset from 62.92% to 96.67% at a false acceptance rate of 0.01%. Our fine-tuned model is available for use by other researchers.
Graph Representation for Face Analysis in Image Collections
Nov 27, 2019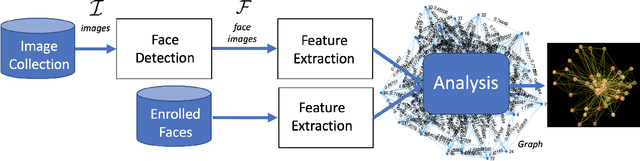
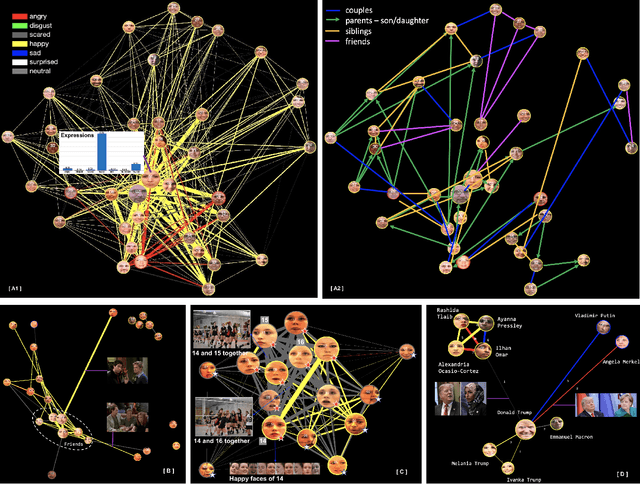
Given an image collection of a social event with a huge number of pictures, it is very useful to have tools that can be used to analyze how the individuals --that are present in the collection-- interact with each other. In this paper, we propose an optimal graph representation that is based on the `connectivity' of them. The connectivity of a pair of subjects gives a score that represents how `connected' they are. It is estimated based on co-occurrence, closeness, facial expressions, and the orientation of the head when they are looking to each other. In our proposed graph, the nodes represent the subjects of the collection, and the edges correspond to their connectivities. The location of the nodes is estimated according to their connectivity (the closer the nodes, the more connected are the subjects). Finally, we developed a graphical user interface in which we can click onto the nodes (or the edges) to display the corresponding images of the collection in which the subject of the nodes (or the connected subjects) are present. We present relevant results by analyzing a wedding celebration, a sitcom video, a volleyball game and images extracted from Twitter given a hashtag. We believe that this tool can be very helpful to detect the existing social relations in an image collection.
Face Recognition in Low Quality Images: A Survey
Aug 07, 2018
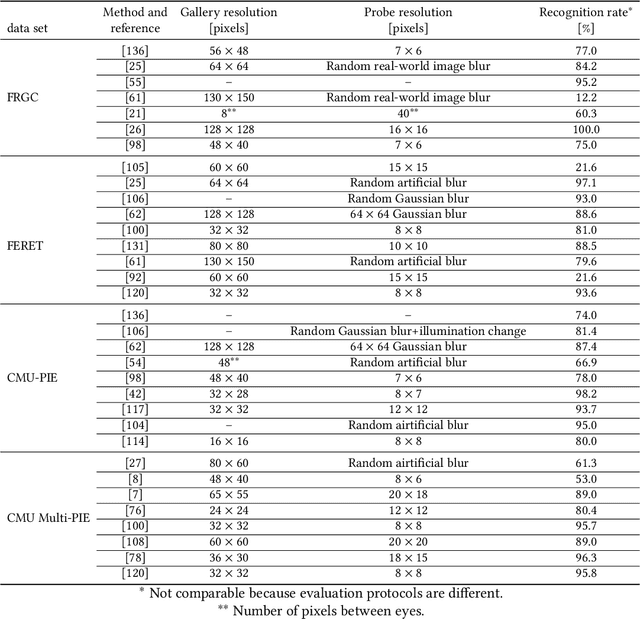
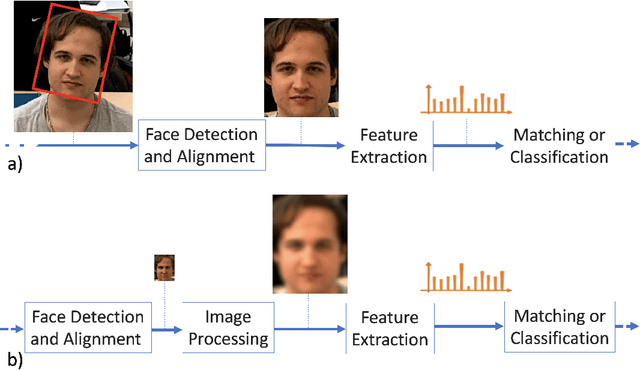
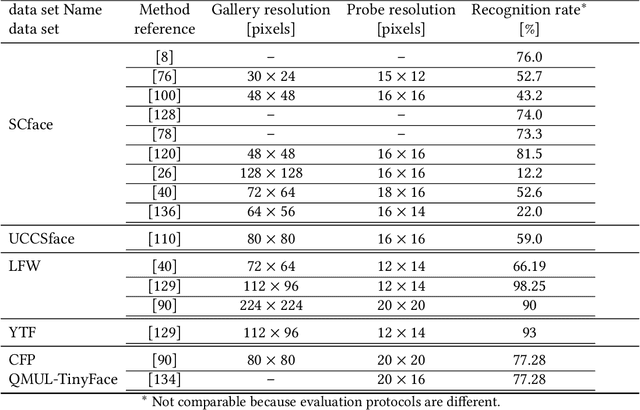
Low-resolution face recognition (LRFR) has received increasing attention over the past few years. Its applications lie widely in the real-world environment when high-resolution or high-quality images are hard to capture. One of the biggest demands for LRFR technologies is video surveillance. As the the number of surveillance cameras in the city increases, the videos that captured will need to be processed automatically. However, those videos or images are usually captured with large standoffs, arbitrary illumination condition, and diverse angles of view. Faces in these images are generally small in size. Several studies addressed this problem employed techniques like super resolution, deblurring, or learning a relationship between different resolution domains. In this paper, we provide a comprehensive review of approaches to low-resolution face recognition in the past five years. First, a general problem definition is given. Later, systematically analysis of the works on this topic is presented by catogory. In addition to describing the methods, we also focus on datasets and experiment settings. We further address the related works on unconstrained low-resolution face recognition and compare them with the result that use synthetic low-resolution data. Finally, we summarized the general limitations and speculate a priorities for the future effort.
Low Resolution Face Recognition in the Wild
May 29, 2018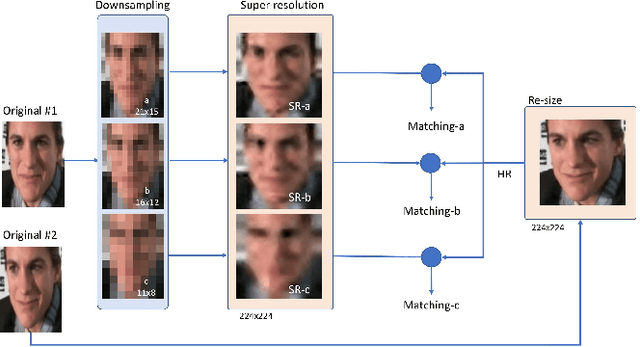
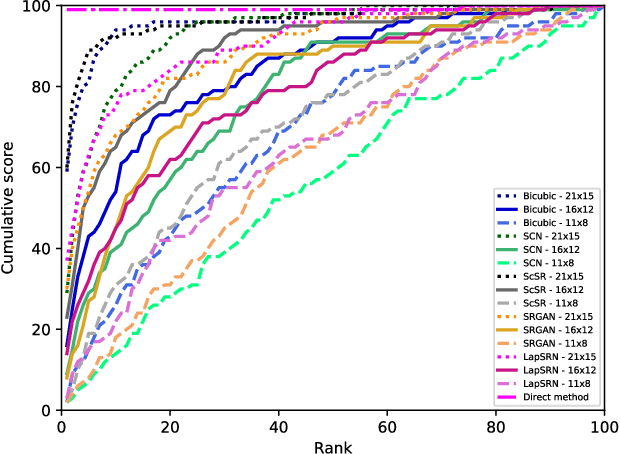
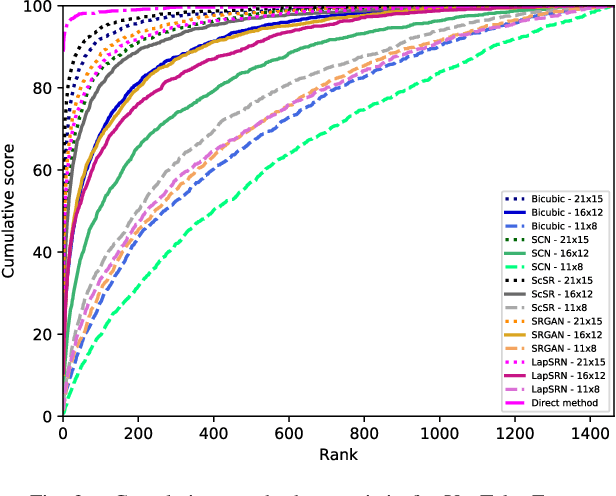
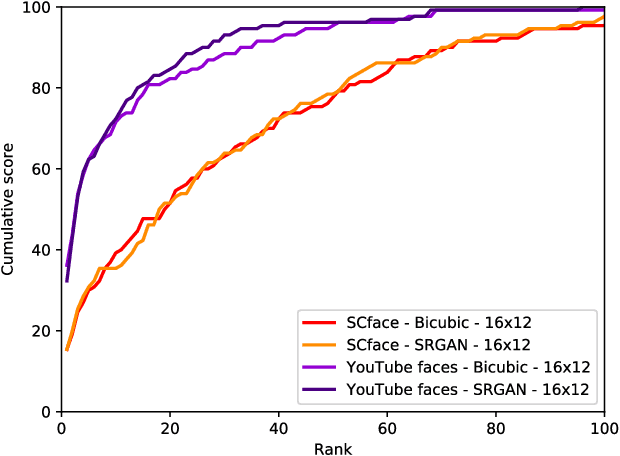
Although face recognition systems have achieved impressive performance in recent years, the low-resolution face recognition (LRFR) task remains challenging, especially when the LR faces are captured under non-ideal conditions, as is common in surveillance-based applications. Faces captured in such conditions are often contaminated by blur, nonuniform lighting, and nonfrontal face pose. In this paper, we analyze face recognition techniques using data captured under low-quality conditions in the wild. We provide a comprehensive analysis of experimental results for two of the most important applications in real surveillance applications, and demonstrate practical approaches to handle both cases that show promising performance. The following three contributions are made: {\em (i)} we conduct experiments to evaluate super-resolution methods for low-resolution face recognition; {\em (ii)} we study face re-identification on various public face datasets including real surveillance and low-resolution subsets of large-scale datasets, present a baseline result for several deep learning based approaches, and improve them by introducing a GAN pre-training approach and fully convolutional architecture; and {\em (iii)} we explore low-resolution face identification by employing a state-of-the-art supervised discriminative learning approach. Evaluations are conducted on challenging portions of the SCFace and UCCSface datasets.