 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISReg: Variance-Invariance-Sketching Regularization for JEPA training
Jun 01, 2026Self-supervised learning methods prevent embedding collapse via modeling heuristics or explicit regularization of the embedding space. Among the latter, VICReg decomposes regularization into variance and covariance objectives, offering flexibility and interpretability. However, covariance captures only second-order statistics -- encouraging decorrelation but failing to enforce the full distributional shape needed for stable training. Sketching-based methods such as SIGReg address this by aligning embeddings to an isotropic Gaussian, but lack flexibility and suffer from vanishing gradients under collapse. We propose Variance-Invariance-Sketching Regularization (VISReg), which replaces covariance with a Sliced-Wasserstein-based sketching objective that enforces full distributional shape, while retaining a variance term for scale control. By decoupling scale and shape, VISReg combines VICReg's flexibility with the distributional rigor of sketching methods, providing robust gradients even under collapse. We show that VISReg scales linearly, outperforms existing regularization on low-quality datasets, and is resilient to long-tailed and low-rank regimes. Pre-trained on ImageNet-1K, VISReg achieves state-of-the-art performance on out-of-distribution datasets. Pre-trained on ImageNet-22K, it matches DINOv2's OOD performance despite the latter using 10x more data (LVD-142M). Project and code: https://haiyuwu.github.io/visreg.
OphIn-500K: Curating Web-Scale Visual Instructions for Scaling Ophthalmic Multimodal Large Language Models
May 27, 2026The advancement of general medical Multimodal Large Language Models (MLLMs) has shown great potential for building conversational assistants to support clinical diagnosis. However, their adaptation to highly specialized domains such as ophthalmology remains underexplored, primarily due to the scarcity of large-scale, domain-specific instruction-tuning data. Existing ophthalmic datasets for conversational agents are often limited in scale and largely rely on images from established public benchmarks, limiting the scalability of ophthalmic MLLMs and their ability to capture real-world clinical complexity. To address this gap, we propose $\textbf{OphIn-Engine}$, an ophthalmology-specific instruction data curation pipeline that constructs high-quality instruction data from open-access ophthalmology web-scale videos. The pipeline integrates multimodal transcription for extracting image-transcript pairs, visual cue separation and scoring for identifying clinically relevant visual descriptions, and instruction synthesis with quality control for generating accurate and diverse clinical dialogues. Using this engine, we introduce $\textbf{OphIn-500K}$, a large-scale multimodal ophthalmology instruction-tuning dataset containing over 500,000 instruction instances and more than 151,000 unique images from over 29,000 video clips, formatted as visual question answering (VQA), multi-turn conversational interactions, and chain-of-thought (CoT) reasoning. Built upon this dataset, we further develop $\textbf{OphIn-VL}$, an ophthalmology-specific MLLM with advanced visual understanding and conversational capabilities. Comprehensive experiments and case studies demonstrate that OphIn-VL achieves superior performance compared with state-of-the-art general medical and domain-specific MLLMs.
Vec2Face+ for Face Dataset Generation
Jul 23, 2025When synthesizing identities as face recognition training data, it is generally believed that large inter-class separability and intra-class attribute variation are essential for synthesizing a quality dataset. % This belief is generally correct, and this is what we aim for. However, when increasing intra-class variation, existing methods overlook the necessity of maintaining intra-class identity consistency. % To address this and generate high-quality face training data, we propose Vec2Face+, a generative model that creates images directly from image features and allows for continuous and easy control of face identities and attributes. Using Vec2Face+, we obtain datasets with proper inter-class separability and intra-class variation and identity consistency using three strategies: 1) we sample vectors sufficiently different from others to generate well-separated identities; 2) we propose an AttrOP algorithm for increasing general attribute variations; 3) we propose LoRA-based pose control for generating images with profile head poses, which is more efficient and identity-preserving than AttrOP. % Our system generates VFace10K, a synthetic face dataset with 10K identities, which allows an FR model to achieve state-of-the-art accuracy on seven real-world test sets. Scaling the size to 4M and 12M images, the corresponding VFace100K and VFace300K datasets yield higher accuracy than the real-world training dataset, CASIA-WebFace, on five real-world test sets. This is the first time a synthetic dataset beats the CASIA-WebFace in average accuracy. In addition, we find that only 1 out of 11 synthetic datasets outperforms random guessing (\emph{i.e., 50\%}) in twin verification and that models trained with synthetic identities are more biased than those trained with real identities. Both are important aspects for future investigation.
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
May 14, 2025Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.~GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.~GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.
Prompt-OT: An Optimal Transport Regularization Paradigm for Knowledge Preservation in Vision-Language Model Adaptation
Mar 11, 2025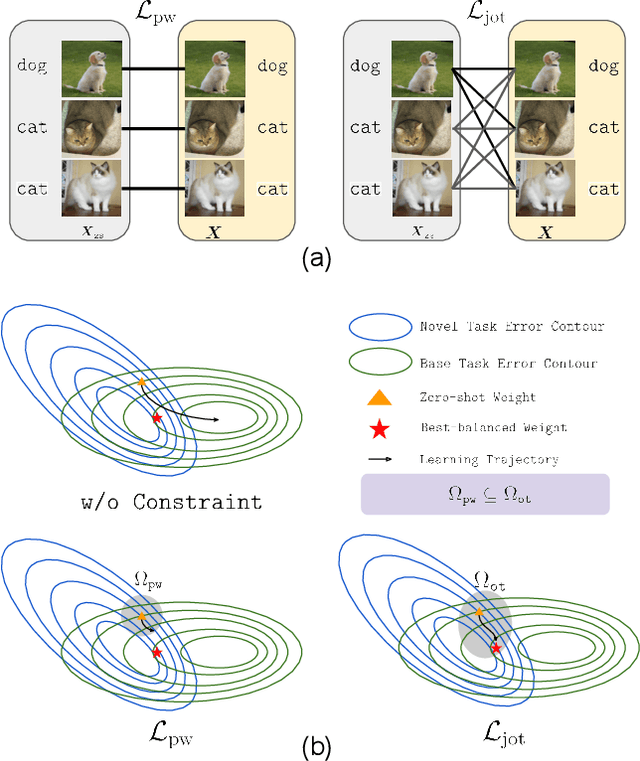



Vision-language models (VLMs) such as CLIP demonstrate strong performance but struggle when adapted to downstream tasks. Prompt learning has emerged as an efficient and effective strategy to adapt VLMs while preserving their pre-trained knowledge. However, existing methods still lead to overfitting and degrade zero-shot generalization. To address this challenge, we propose an optimal transport (OT)-guided prompt learning framework that mitigates forgetting by preserving the structural consistency of feature distributions between pre-trained and fine-tuned models. Unlike conventional point-wise constraints, OT naturally captures cross-instance relationships and expands the feasible parameter space for prompt tuning, allowing a better trade-off between adaptation and generalization. Our approach enforces joint constraints on both vision and text representations, ensuring a holistic feature alignment. Extensive experiments on benchmark datasets demonstrate that our simple yet effective method can outperform existing prompt learning strategies in base-to-novel generalization, cross-dataset evaluation, and domain generalization without additional augmentation or ensemble techniques. The code is available at https://github.com/ChongQingNoSubway/Prompt-OT
On the "Illusion" of Gender Bias in Face Recognition: Explaining the Fairness Issue Through Non-demographic Attributes
Jan 21, 2025Face recognition systems (FRS) exhibit significant accuracy differences based on the user's gender. Since such a gender gap reduces the trustworthiness of FRS, more recent efforts have tried to find the causes. However, these studies make use of manually selected, correlated, and small-sized sets of facial features to support their claims. In this work, we analyse gender bias in face recognition by successfully extending the search domain to decorrelated combinations of 40 non-demographic facial characteristics. First, we propose a toolchain to effectively decorrelate and aggregate facial attributes to enable a less-biased gender analysis on large-scale data. Second, we introduce two new fairness metrics to measure fairness with and without context. Based on these grounds, we thirdly present a novel unsupervised algorithm able to reliably identify attribute combinations that lead to vanishing bias when used as filter predicates for balanced testing datasets. The experiments show that the gender gap vanishes when images of male and female subjects share specific attributes, clearly indicating that the issue is not a question of biology but of the social definition of appearance. These findings could reshape our understanding of fairness in face biometrics and provide insights into FRS, helping to address gender bias issues.
Lights, Camera, Matching: The Role of Image Illumination in Fair Face Recognition
Jan 15, 2025



Facial brightness is a key image quality factor impacting face recognition accuracy differentials across demographic groups. In this work, we aim to decrease the accuracy gap between the similarity score distributions for Caucasian and African American female mated image pairs, as measured by d' between distributions. To balance brightness across demographic groups, we conduct three experiments, interpreting brightness in the face skin region either as median pixel value or as the distribution of pixel values. Balancing based on median brightness alone yields up to a 46.8% decrease in d', while balancing based on brightness distribution yields up to a 57.6% decrease. In all three cases, the similarity scores of the individual distributions improve, with mean scores maximally improving 5.9% for Caucasian females and 3.7% for African American females.
Impact of Sunglasses on One-to-Many Facial Identification Accuracy
Dec 07, 2024



One-to-many facial identification is documented to achieve high accuracy in the case where both the probe and the gallery are `mugshot quality' images. However, an increasing number of documented instances of wrongful arrest following one-to-many facial identification have raised questions about its accuracy. Probe images used in one-to-many facial identification are often cropped from frames of surveillance video and deviate from `mugshot quality' in various ways. This paper systematically explores how the accuracy of one-to-many facial identification is degraded by the person in the probe image choosing to wear dark sunglasses. We show that sunglasses degrade accuracy for mugshot-quality images by an amount similar to strong blur or noticeably lower resolution. Further, we demonstrate that the combination of sunglasses with blur or lower resolution results in even more pronounced loss in accuracy. These results have important implications for developing objective criteria to qualify a probe image for the level of accuracy to be expected if it used for one-to-many identification. To ameliorate the accuracy degradation caused by dark sunglasses, we show that it is possible to recover about 38% of the lost accuracy by synthetically adding sunglasses to all the gallery images, without model re-training. We also show that increasing the representation of wearing-sunglasses images in the training set can largely reduce the error rate. The image set assembled for this research will be made available to support replication and further research into this problem.
Vec2Face: Scaling Face Dataset Generation with Loosely Constrained Vectors
Sep 04, 2024This paper studies how to synthesize face images of non-existent persons, to create a dataset that allows effective training of face recognition (FR) models. Two important goals are (1) the ability to generate a large number of distinct identities (inter-class separation) with (2) a wide variation in appearance of each identity (intra-class variation). However, existing works 1) are typically limited in how many well-separated identities can be generated and 2) either neglect or use a separate editing model for attribute augmentation. We propose Vec2Face, a holistic model that uses only a sampled vector as input and can flexibly generate and control face images and their attributes. Composed of a feature masked autoencoder and a decoder, Vec2Face is supervised by face image reconstruction and can be conveniently used in inference. Using vectors with low similarity among themselves as inputs, Vec2Face generates well-separated identities. Randomly perturbing an input identity vector within a small range allows Vec2Face to generate faces of the same identity with robust variation in face attributes. It is also possible to generate images with designated attributes by adjusting vector values with a gradient descent method. Vec2Face has efficiently synthesized as many as 300K identities with 15 million total images, whereas 60K is the largest number of identities created in the previous works. FR models trained with the generated HSFace datasets, from 10k to 300k identities, achieve state-of-the-art accuracy, from 92% to 93.52%, on five real-world test sets. For the first time, our model created using a synthetic training set achieves higher accuracy than the model created using a same-scale training set of real face images (on the CALFW test set).
Can the accuracy bias by facial hairstyle be reduced through balancing the training data?
May 30, 2024



Appearance of a face can be greatly altered by growing a beard and mustache. The facial hairstyles in a pair of images can cause marked changes to the impostor distribution and the genuine distribution. Also, different distributions of facial hairstyle across demographics could cause a false impression of relative accuracy across demographics. We first show that, even though larger training sets boost the recognition accuracy on all facial hairstyles, accuracy variations caused by facial hairstyles persist regardless of the size of the training set. Then, we analyze the impact of having different fractions of the training data represent facial hairstyles. We created balanced training sets using a set of identities available in Webface42M that both have clean-shaven and facial hair images. We find that, even when a face recognition model is trained with a balanced clean-shaven / facial hair training set, accuracy variation on the test data does not diminish. Next, data augmentation is employed to further investigate the effect of facial hair distribution in training data by manipulating facial hair pixels with the help of facial landmark points and a facial hair segmentation model. Our results show facial hair causes an accuracy gap between clean-shaven and facial hair images, and this impact can be significantly different between African-Americans and Caucasians.