 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat matters for Representation Alignment: Global Information or Spatial Structure?
Dec 11, 2025Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its \textit{global} \revision{semantic} information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising; spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of \emph{spatial} information. We replace the standard MLP projection layer in REPA with a simple convolution layer and introduce a spatial normalization layer for the external representation. Surprisingly, our simple method (implemented in $<$4 lines of code), termed iREPA, consistently improves convergence speed of REPA, across a diverse set of vision encoders, model sizes, and training variants (such as REPA, REPA-E, Meanflow, JiT etc). %, etc. Our work motivates revisiting the fundamental working mechanism of representational alignment and how it can be leveraged for improved training of generative models. The code and project page are available at https://end2end-diffusion.github.io/irepa
FACA: Fair and Agile Multi-Robot Collision Avoidance in Constrained Environments with Dynamic Priorities
Nov 18, 2025



Multi-robot systems are increasingly being used for critical applications such as rescuing injured people, delivering food and medicines, and monitoring key areas. These applications usually involve navigating at high speeds through constrained spaces such as small gaps. Navigating such constrained spaces becomes particularly challenging when the space is crowded with multiple heterogeneous agents all of which have urgent priorities. What makes the problem even harder is that during an active response situation, roles and priorities can quickly change on a dime without informing the other agents. In order to complete missions in such environments, robots must not only be safe, but also agile, able to dodge and change course at a moment's notice. In this paper, we propose FACA, a fair and agile collision avoidance approach where robots coordinate their tasks by talking to each other via natural language (just as people do). In FACA, robots balance safety with agility via a novel artificial potential field algorithm that creates an automatic ``roundabout'' effect whenever a conflict arises. Our experiments show that FACA achieves a improvement in efficiency, completing missions more than 3.5X faster than baselines with a time reduction of over 70% while maintaining robust safety margins.
Vec2Face+ for Face Dataset Generation
Jul 23, 2025When synthesizing identities as face recognition training data, it is generally believed that large inter-class separability and intra-class attribute variation are essential for synthesizing a quality dataset. % This belief is generally correct, and this is what we aim for. However, when increasing intra-class variation, existing methods overlook the necessity of maintaining intra-class identity consistency. % To address this and generate high-quality face training data, we propose Vec2Face+, a generative model that creates images directly from image features and allows for continuous and easy control of face identities and attributes. Using Vec2Face+, we obtain datasets with proper inter-class separability and intra-class variation and identity consistency using three strategies: 1) we sample vectors sufficiently different from others to generate well-separated identities; 2) we propose an AttrOP algorithm for increasing general attribute variations; 3) we propose LoRA-based pose control for generating images with profile head poses, which is more efficient and identity-preserving than AttrOP. % Our system generates VFace10K, a synthetic face dataset with 10K identities, which allows an FR model to achieve state-of-the-art accuracy on seven real-world test sets. Scaling the size to 4M and 12M images, the corresponding VFace100K and VFace300K datasets yield higher accuracy than the real-world training dataset, CASIA-WebFace, on five real-world test sets. This is the first time a synthetic dataset beats the CASIA-WebFace in average accuracy. In addition, we find that only 1 out of 11 synthetic datasets outperforms random guessing (\emph{i.e., 50\%}) in twin verification and that models trained with synthetic identities are more biased than those trained with real identities. Both are important aspects for future investigation.
DiSA: Diffusion Step Annealing in Autoregressive Image Generation
May 26, 2025An increasing number of autoregressive models, such as MAR, FlowAR, xAR, and Harmon adopt diffusion sampling to improve the quality of image generation. However, this strategy leads to low inference efficiency, because it usually takes 50 to 100 steps for diffusion to sample a token. This paper explores how to effectively address this issue. Our key motivation is that as more tokens are generated during the autoregressive process, subsequent tokens follow more constrained distributions and are easier to sample. To intuitively explain, if a model has generated part of a dog, the remaining tokens must complete the dog and thus are more constrained. Empirical evidence supports our motivation: at later generation stages, the next tokens can be well predicted by a multilayer perceptron, exhibit low variance, and follow closer-to-straight-line denoising paths from noise to tokens. Based on our finding, we introduce diffusion step annealing (DiSA), a training-free method which gradually uses fewer diffusion steps as more tokens are generated, e.g., using 50 steps at the beginning and gradually decreasing to 5 steps at later stages. Because DiSA is derived from our finding specific to diffusion in autoregressive models, it is complementary to existing acceleration methods designed for diffusion alone. DiSA can be implemented in only a few lines of code on existing models, and albeit simple, achieves $5-10\times$ faster inference for MAR and Harmon and $1.4-2.5\times$ for FlowAR and xAR, while maintaining the generation quality.
REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
Apr 14, 2025In this paper we tackle a fundamental question: "Can we train latent diffusion models together with the variational auto-encoder (VAE) tokenizer in an end-to-end manner?" Traditional deep-learning wisdom dictates that end-to-end training is often preferable when possible. However, for latent diffusion transformers, it is observed that end-to-end training both VAE and diffusion-model using standard diffusion-loss is ineffective, even causing a degradation in final performance. We show that while diffusion loss is ineffective, end-to-end training can be unlocked through the representation-alignment (REPA) loss -- allowing both VAE and diffusion model to be jointly tuned during the training process. Despite its simplicity, the proposed training recipe (REPA-E) shows remarkable performance; speeding up diffusion model training by over 17x and 45x over REPA and vanilla training recipes, respectively. Interestingly, we observe that end-to-end tuning with REPA-E also improves the VAE itself; leading to improved latent space structure and downstream generation performance. In terms of final performance, our approach sets a new state-of-the-art; achieving FID of 1.26 and 1.83 with and without classifier-free guidance on ImageNet 256 x 256. Code is available at https://end2end-diffusion.github.io.
Probability Density Geodesics in Image Diffusion Latent Space
Apr 09, 2025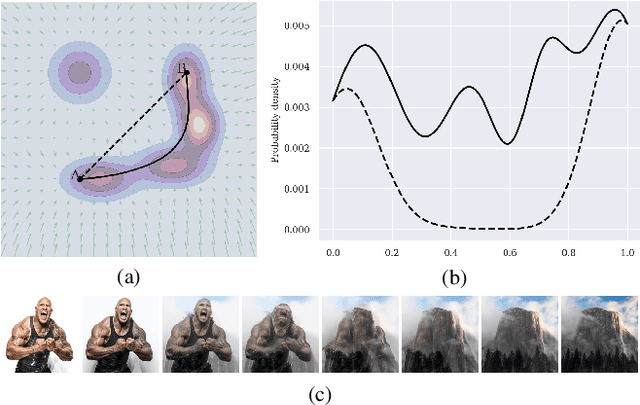
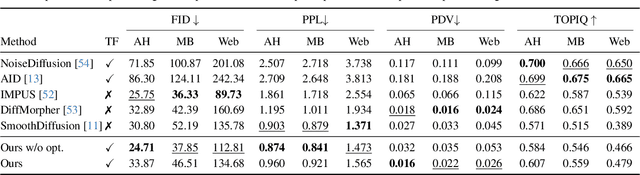
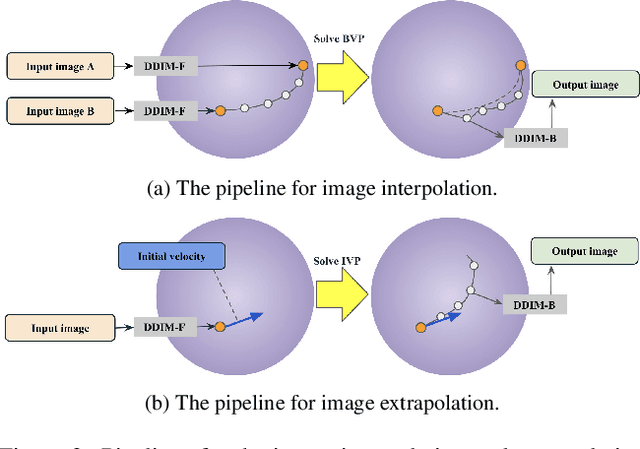
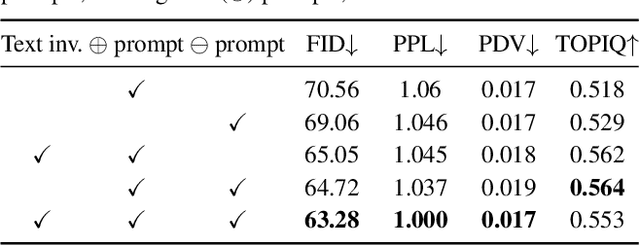
Diffusion models indirectly estimate the probability density over a data space, which can be used to study its structure. In this work, we show that geodesics can be computed in diffusion latent space, where the norm induced by the spatially-varying inner product is inversely proportional to the probability density. In this formulation, a path that traverses a high density (that is, probable) region of image latent space is shorter than the equivalent path through a low density region. We present algorithms for solving the associated initial and boundary value problems and show how to compute the probability density along the path and the geodesic distance between two points. Using these techniques, we analyze how closely video clips approximate geodesics in a pre-trained image diffusion space. Finally, we demonstrate how these techniques can be applied to training-free image sequence interpolation and extrapolation, given a pre-trained image diffusion model.
R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
Apr 09, 2025Improving open-source models on real-world SWE tasks (solving GITHUB issues) faces two key challenges: 1) scalable curation of execution environments to train these models, and, 2) optimal scaling of test-time compute. We introduce AgentGym, the largest procedurally-curated executable gym environment for training real-world SWE-agents, consisting of more than 8.7K tasks. AgentGym is powered by two main contributions: 1) SYNGEN: a synthetic data curation recipe that enables scalable curation of executable environments using test-generation and back-translation directly from commits, thereby reducing reliance on human-written issues or unit tests. We show that this enables more scalable training leading to pass@1 performance of 34.4% on SWE-Bench Verified benchmark with our 32B model. 2) Hybrid Test-time Scaling: we provide an in-depth analysis of two test-time scaling axes; execution-based and execution-free verifiers, demonstrating that they exhibit complementary strengths and limitations. Test-based verifiers suffer from low distinguishability, while execution-free verifiers are biased and often rely on stylistic features. Surprisingly, we find that while each approach individually saturates around 42-43%, significantly higher gains can be obtained by leveraging their complementary strengths. Overall, our approach achieves 51% on the SWE-Bench Verified benchmark, reflecting a new state-of-the-art for open-weight SWE-agents and for the first time showing competitive performance with proprietary models such as o1, o1-preview and sonnet-3.5-v2 (with tools). We will open-source our environments, models, and agent trajectories.
Storybooth: Training-free Multi-Subject Consistency for Improved Visual Storytelling
Apr 08, 2025Training-free consistent text-to-image generation depicting the same subjects across different images is a topic of widespread recent interest. Existing works in this direction predominantly rely on cross-frame self-attention; which improves subject-consistency by allowing tokens in each frame to pay attention to tokens in other frames during self-attention computation. While useful for single subjects, we find that it struggles when scaling to multiple characters. In this work, we first analyze the reason for these limitations. Our exploration reveals that the primary-issue stems from self-attention-leakage, which is exacerbated when trying to ensure consistency across multiple-characters. This happens when tokens from one subject pay attention to other characters, causing them to appear like each other (e.g., a dog appearing like a duck). Motivated by these findings, we propose StoryBooth: a training-free approach for improving multi-character consistency. In particular, we first leverage multi-modal chain-of-thought reasoning and region-based generation to apriori localize the different subjects across the desired story outputs. The final outputs are then generated using a modified diffusion model which consists of two novel layers: 1) a bounded cross-frame self-attention layer for reducing inter-character attention leakage, and 2) token-merging layer for improving consistency of fine-grain subject details. Through both qualitative and quantitative results we find that the proposed approach surpasses prior state-of-the-art, exhibiting improved consistency across both multiple-characters and fine-grain subject details.
Negative Token Merging: Image-based Adversarial Feature Guidance
Dec 02, 2024



Text-based adversarial guidance using a negative prompt has emerged as a widely adopted approach to push the output features away from undesired concepts. While useful, performing adversarial guidance using text alone can be insufficient to capture complex visual concepts and avoid undesired visual elements like copyrighted characters. In this paper, for the first time we explore an alternate modality in this direction by performing adversarial guidance directly using visual features from a reference image or other images in a batch. In particular, we introduce negative token merging (NegToMe), a simple but effective training-free approach which performs adversarial guidance by selectively pushing apart matching semantic features (between reference and output generation) during the reverse diffusion process. When used w.r.t. other images in the same batch, we observe that NegToMe significantly increases output diversity (racial, gender, visual) without sacrificing output image quality. Similarly, when used w.r.t. a reference copyrighted asset, NegToMe helps reduce visual similarity with copyrighted content by 34.57%. NegToMe is simple to implement using just few-lines of code, uses only marginally higher (<4%) inference times and generalizes to different diffusion architectures like Flux, which do not natively support the use of a separate negative prompt. Code is available at https://negtome.github.io
On the Impact of White-box Deployment Strategies for Edge AI on Latency and Model Performance
Nov 01, 2024
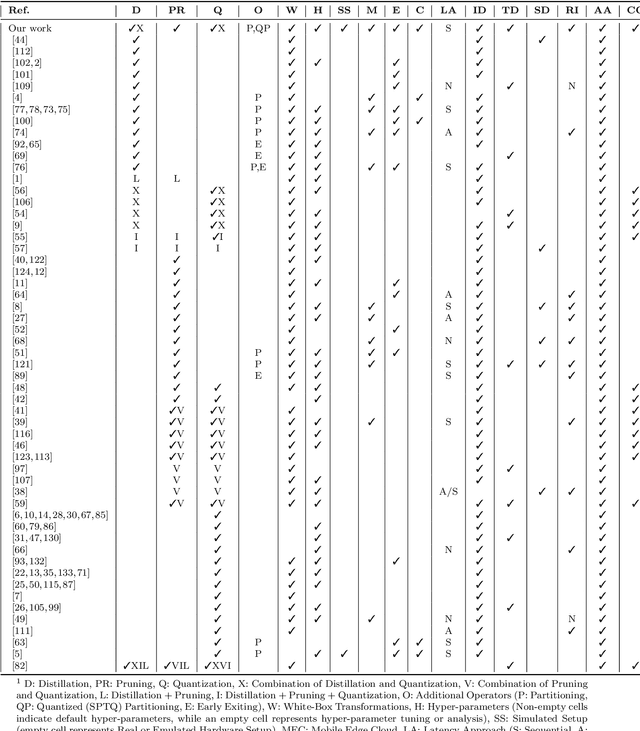

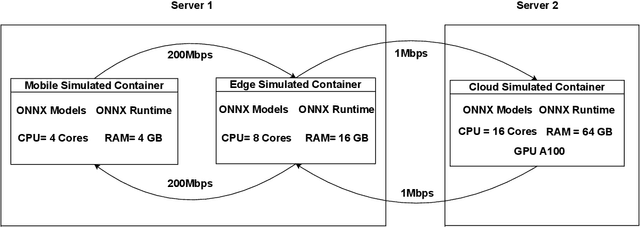
To help MLOps engineers decide which operator to use in which deployment scenario, this study aims to empirically assess the accuracy vs latency trade-off of white-box (training-based) and black-box operators (non-training-based) and their combinations in an Edge AI setup. We perform inference experiments including 3 white-box (i.e., QAT, Pruning, Knowledge Distillation), 2 black-box (i.e., Partition, SPTQ), and their combined operators (i.e., Distilled SPTQ, SPTQ Partition) across 3 tiers (i.e., Mobile, Edge, Cloud) on 4 commonly-used Computer Vision and Natural Language Processing models to identify the effective strategies, considering the perspective of MLOps Engineers. Our Results indicate that the combination of Distillation and SPTQ operators (i.e., DSPTQ) should be preferred over non-hybrid operators when lower latency is required in the edge at small to medium accuracy drop. Among the non-hybrid operators, the Distilled operator is a better alternative in both mobile and edge tiers for lower latency performance at the cost of small to medium accuracy loss. Moreover, the operators involving distillation show lower latency in resource-constrained tiers (Mobile, Edge) compared to the operators involving Partitioning across Mobile and Edge tiers. For textual subject models, which have low input data size requirements, the Cloud tier is a better alternative for the deployment of operators than the Mobile, Edge, or Mobile-Edge tier (the latter being used for operators involving partitioning). In contrast, for image-based subject models, which have high input data size requirements, the Edge tier is a better alternative for operators than Mobile, Edge, or their combination.