 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStorybooth: Training-free Multi-Subject Consistency for Improved Visual Storytelling
Apr 08, 2025



Training-free consistent text-to-image generation depicting the same subjects across different images is a topic of widespread recent interest. Existing works in this direction predominantly rely on cross-frame self-attention; which improves subject-consistency by allowing tokens in each frame to pay attention to tokens in other frames during self-attention computation. While useful for single subjects, we find that it struggles when scaling to multiple characters. In this work, we first analyze the reason for these limitations. Our exploration reveals that the primary-issue stems from self-attention-leakage, which is exacerbated when trying to ensure consistency across multiple-characters. This happens when tokens from one subject pay attention to other characters, causing them to appear like each other (e.g., a dog appearing like a duck). Motivated by these findings, we propose StoryBooth: a training-free approach for improving multi-character consistency. In particular, we first leverage multi-modal chain-of-thought reasoning and region-based generation to apriori localize the different subjects across the desired story outputs. The final outputs are then generated using a modified diffusion model which consists of two novel layers: 1) a bounded cross-frame self-attention layer for reducing inter-character attention leakage, and 2) token-merging layer for improving consistency of fine-grain subject details. Through both qualitative and quantitative results we find that the proposed approach surpasses prior state-of-the-art, exhibiting improved consistency across both multiple-characters and fine-grain subject details.
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
De Re Updates
Jun 22, 2021In this paper, we propose a lightweight yet powerful dynamic epistemic logic that captures not only the distinction between de dicto and de re knowledge but also the distinction between de dicto and de re updates. The logic is based on the dynamified version of an epistemic language extended with the assignment operator borrowed from dynamic logic, following the work of Wang and Seligman (Proc. AiML 2018). We obtain complete axiomatizations for the counterparts of public announcement logic and event-model-based DEL based on new reduction axioms taking care of the interactions between dynamics and assignments.
* In Proceedings TARK 2021, arXiv:2106.10886
One Shot 3D Photography
Sep 01, 2020
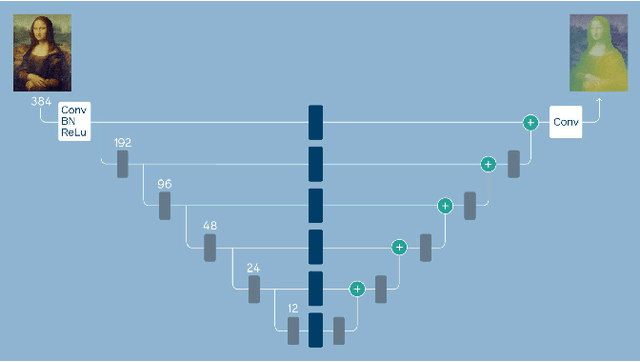

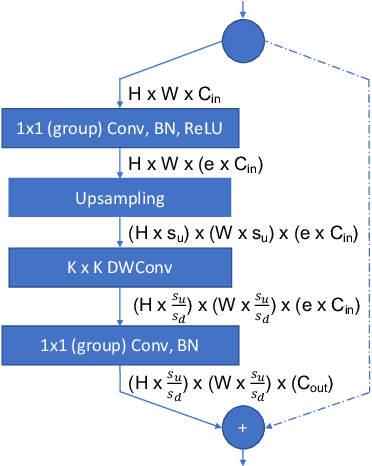
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
Real-time Image-based 6-DOF Localization in Large-Scale Environments
Mar 27, 2012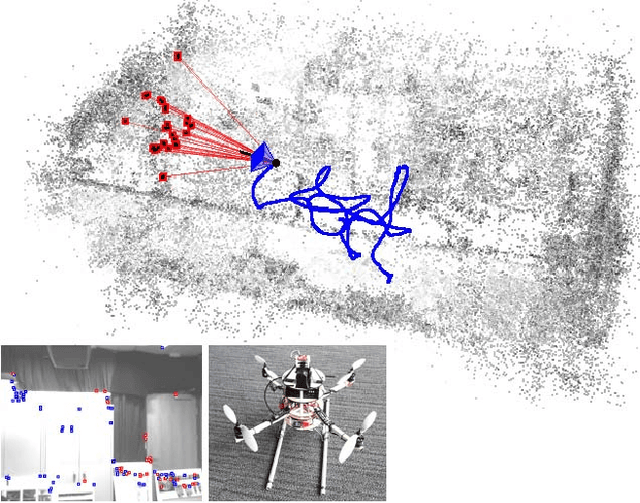
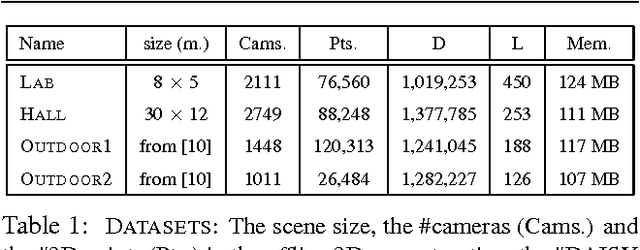
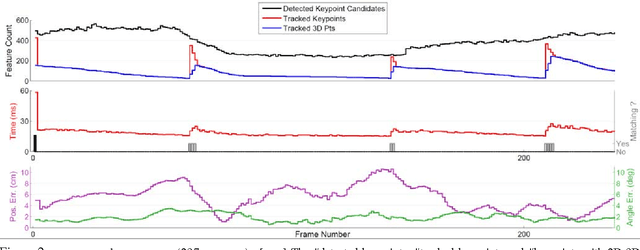
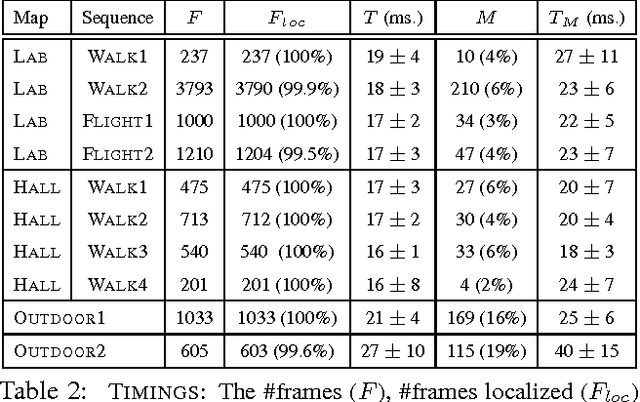
We present a real-time approach for image-based localization within large scenes that have been reconstructed offline using structure from motion (Sfm). From monocular video, our method continuously computes a precise 6-DOF camera pose, by efficiently tracking natural features and matching them to 3D points in the Sfm point cloud. Our main contribution lies in efficiently interleaving a fast keypoint tracker that uses inexpensive binary feature descriptors with a new approach for direct 2D-to-3D matching. The 2D-to-3D matching avoids the need for online extraction of scale-invariant features. Instead, offline we construct an indexed database containing multiple DAISY descriptors per 3D point extracted at multiple scales. The key to the efficiency of our method lies in invoking DAISY descriptor extraction and matching sparingly during localization, and in distributing this computation over a window of successive frames. This enables the algorithm to run in real-time, without fluctuations in the latency over long durations. We evaluate the method in large indoor and outdoor scenes. Our algorithm runs at over 30 Hz on a laptop and at 12 Hz on a low-power, mobile computer suitable for onboard computation on a quadrotor micro aerial vehicle.