 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Rewards: An Axiomatic Framework for Lexicographic MDPs
May 17, 2025Recent work has formalized the reward hypothesis through the lens of expected utility theory, by interpreting reward as utility. Hausner's foundational work showed that dropping the continuity axiom leads to a generalization of expected utility theory where utilities are lexicographically ordered vectors of arbitrary dimension. In this paper, we extend this result by identifying a simple and practical condition under which preferences cannot be represented by scalar rewards, necessitating a 2-dimensional reward function. We provide a full characterization of such reward functions, as well as the general d-dimensional case, in Markov Decision Processes (MDPs) under a memorylessness assumption on preferences. Furthermore, we show that optimal policies in this setting retain many desirable properties of their scalar-reward counterparts, while in the Constrained MDP (CMDP) setting -- another common multiobjective setting -- they do not.
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
Can Safety Fine-Tuning Be More Principled? Lessons Learned from Cybersecurity
Jan 19, 2025As LLMs develop increasingly advanced capabilities, there is an increased need to minimize the harm that could be caused to society by certain model outputs; hence, most LLMs have safety guardrails added, for example via fine-tuning. In this paper, we argue the position that current safety fine-tuning is very similar to a traditional cat-and-mouse game (or arms race) between attackers and defenders in cybersecurity. Model jailbreaks and attacks are patched with bandaids to target the specific attack mechanism, but many similar attack vectors might remain. When defenders are not proactively coming up with principled mechanisms, it becomes very easy for attackers to sidestep any new defenses. We show how current defenses are insufficient to prevent new adversarial jailbreak attacks, reward hacking, and loss of control problems. In order to learn from past mistakes in cybersecurity, we draw analogies with historical examples and develop lessons learned that can be applied to LLM safety. These arguments support the need for new and more principled approaches to designing safe models, which are architected for security from the beginning. We describe several such approaches from the AI literature.
Addressing Sample Inefficiency in Multi-View Representation Learning
Dec 17, 2023



Non-contrastive self-supervised learning (NC-SSL) methods like BarlowTwins and VICReg have shown great promise for label-free representation learning in computer vision. Despite the apparent simplicity of these techniques, researchers must rely on several empirical heuristics to achieve competitive performance, most notably using high-dimensional projector heads and two augmentations of the same image. In this work, we provide theoretical insights on the implicit bias of the BarlowTwins and VICReg loss that can explain these heuristics and guide the development of more principled recommendations. Our first insight is that the orthogonality of the features is more critical than projector dimensionality for learning good representations. Based on this, we empirically demonstrate that low-dimensional projector heads are sufficient with appropriate regularization, contrary to the existing heuristic. Our second theoretical insight suggests that using multiple data augmentations better represents the desiderata of the SSL objective. Based on this, we demonstrate that leveraging more augmentations per sample improves representation quality and trainability. In particular, it improves optimization convergence, leading to better features emerging earlier in the training. Remarkably, we demonstrate that we can reduce the pretraining dataset size by up to 4x while maintaining accuracy and improving convergence simply by using more data augmentations. Combining these insights, we present practical pretraining recommendations that improve wall-clock time by 2x and improve performance on CIFAR-10/STL-10 datasets using a ResNet-50 backbone. Thus, this work provides a theoretical insight into NC-SSL and produces practical recommendations for enhancing its sample and compute efficiency.
EuclidNets: An Alternative Operation for Efficient Inference of Deep Learning Models
Dec 22, 2022With the advent of deep learning application on edge devices, researchers actively try to optimize their deployments on low-power and restricted memory devices. There are established compression method such as quantization, pruning, and architecture search that leverage commodity hardware. Apart from conventional compression algorithms, one may redesign the operations of deep learning models that lead to more efficient implementation. To this end, we propose EuclidNet, a compression method, designed to be implemented on hardware which replaces multiplication, $xw$, with Euclidean distance $(x-w)^2$. We show that EuclidNet is aligned with matrix multiplication and it can be used as a measure of similarity in case of convolutional layers. Furthermore, we show that under various transformations and noise scenarios, EuclidNet exhibits the same performance compared to the deep learning models designed with multiplication operations.
A Reproducible and Realistic Evaluation of Partial Domain Adaptation Methods
Oct 03, 2022



Unsupervised Domain Adaptation (UDA) aims at classifying unlabeled target images leveraging source labeled ones. In this work, we consider the Partial Domain Adaptation (PDA) variant, where we have extra source classes not present in the target domain. Most successful algorithms use model selection strategies that rely on target labels to find the best hyper-parameters and/or models along training. However, these strategies violate the main assumption in PDA: only unlabeled target domain samples are available. Moreover, there are also inconsistencies in the experimental settings - architecture, hyper-parameter tuning, number of runs - yielding unfair comparisons. The main goal of this work is to provide a realistic evaluation of PDA methods with the different model selection strategies under a consistent evaluation protocol. We evaluate 7 representative PDA algorithms on 2 different real-world datasets using 7 different model selection strategies. Our two main findings are: (i) without target labels for model selection, the accuracy of the methods decreases up to 30 percentage points; (ii) only one method and model selection pair performs well on both datasets. Experiments were performed with our PyTorch framework, BenchmarkPDA, which we open source.
On the Generalization of Representations in Reinforcement Learning
Mar 01, 2022
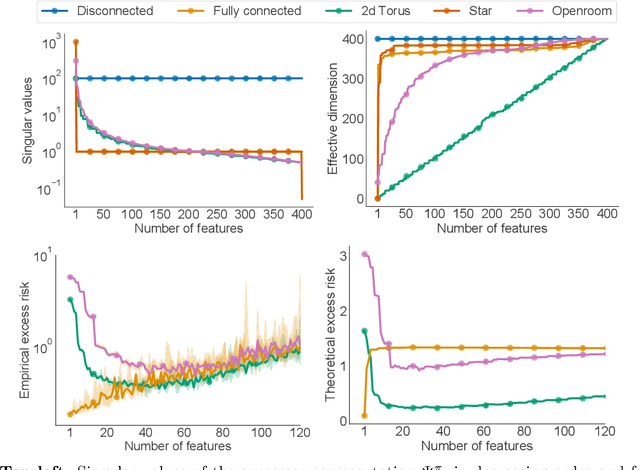
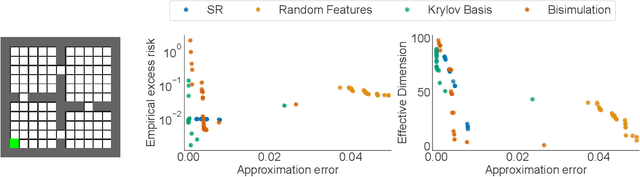
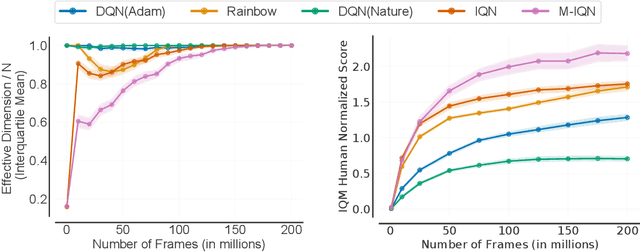
In reinforcement learning, state representations are used to tractably deal with large problem spaces. State representations serve both to approximate the value function with few parameters, but also to generalize to newly encountered states. Their features may be learned implicitly (as part of a neural network) or explicitly (for example, the successor representation of \citet{dayan1993improving}). While the approximation properties of representations are reasonably well-understood, a precise characterization of how and when these representations generalize is lacking. In this work, we address this gap and provide an informative bound on the generalization error arising from a specific state representation. This bound is based on the notion of effective dimension which measures the degree to which knowing the value at one state informs the value at other states. Our bound applies to any state representation and quantifies the natural tension between representations that generalize well and those that approximate well. We complement our theoretical results with an empirical survey of classic representation learning methods from the literature and results on the Arcade Learning Environment, and find that the generalization behaviour of learned representations is well-explained by their effective dimension.
Multi-Resolution Continuous Normalizing Flows
Jun 22, 2021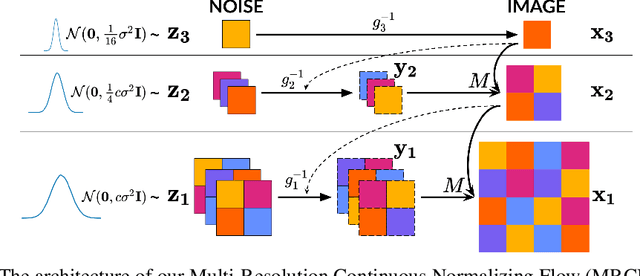
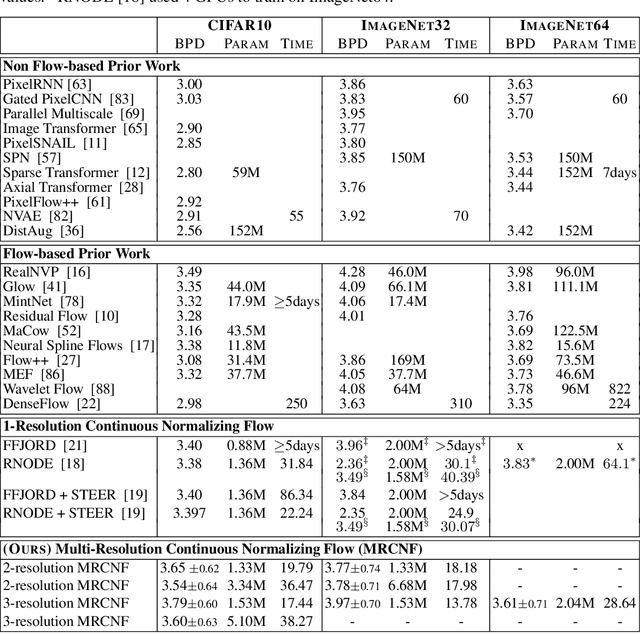
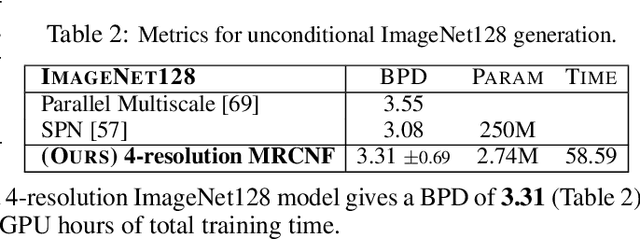

Recent work has shown that Neural Ordinary Differential Equations (ODEs) can serve as generative models of images using the perspective of Continuous Normalizing Flows (CNFs). Such models offer exact likelihood calculation, and invertible generation/density estimation. In this work we introduce a Multi-Resolution variant of such models (MRCNF), by characterizing the conditional distribution over the additional information required to generate a fine image that is consistent with the coarse image. We introduce a transformation between resolutions that allows for no change in the log likelihood. We show that this approach yields comparable likelihood values for various image datasets, with improved performance at higher resolutions, with fewer parameters, using only 1 GPU. Further, we examine the out-of-distribution properties of (Multi-Resolution) Continuous Normalizing Flows, and find that they are similar to those of other likelihood-based generative models.
Improved Predictive Uncertainty using Corruption-based Calibration
Jun 07, 2021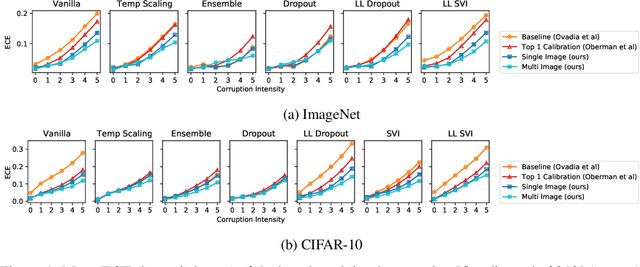
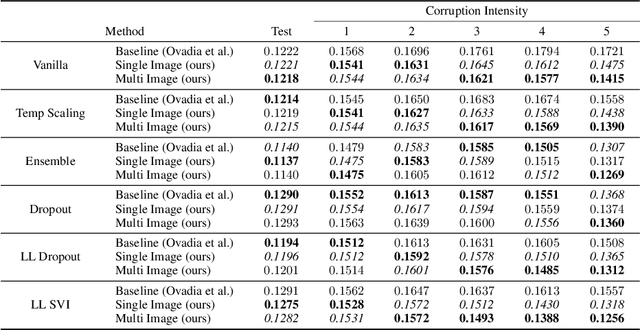
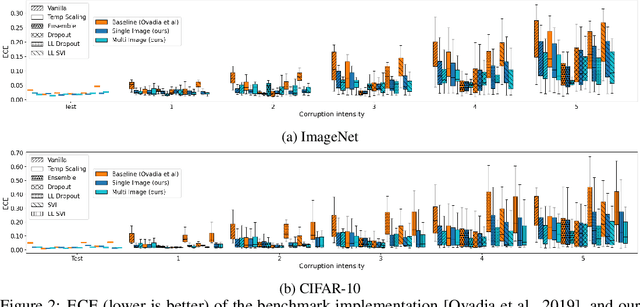
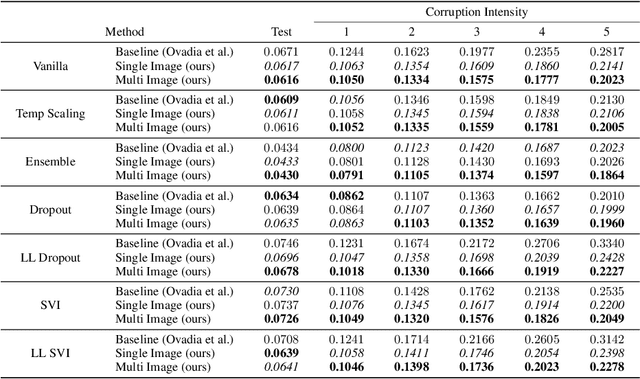
We propose a simple post hoc calibration method to estimate the confidence/uncertainty that a model prediction is correct on data with covariate shift, as represented by the large-scale corrupted data benchmark [Ovadia et al, 2019]. We achieve this by synthesizing surrogate calibration sets by corrupting the calibration set with varying intensities of a known corruption. Our method demonstrates significant improvements on the benchmark on a wide range of covariate shifts.
Bias Mitigation of Face Recognition Models Through Calibration
Jun 07, 2021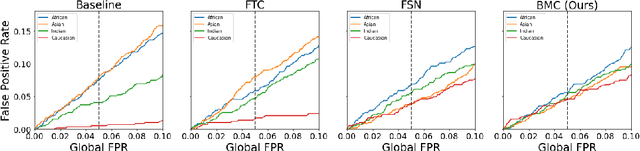

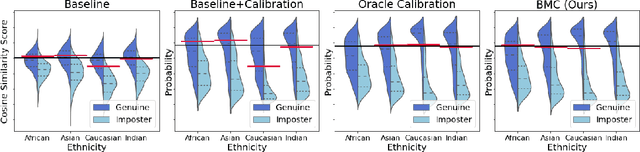
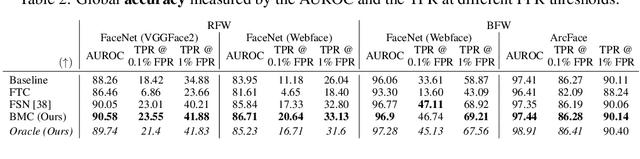
Face recognition models suffer from bias: for example, the probability of a false positive (incorrect face match) strongly depends on sensitive attributes like ethnicity. As a result, these models may disproportionately and negatively impact minority groups when used in law enforcement. In this work, we introduce the Bias Mitigation Calibration (BMC) method, which (i) increases model accuracy (improving the state-of-the-art), (ii) produces fairly-calibrated probabilities, (iii) significantly reduces the gap in the false positive rates, and (iv) does not require knowledge of the sensitive attribute.