 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reproducible and Realistic Evaluation of Partial Domain Adaptation Methods
Oct 03, 2022



Unsupervised Domain Adaptation (UDA) aims at classifying unlabeled target images leveraging source labeled ones. In this work, we consider the Partial Domain Adaptation (PDA) variant, where we have extra source classes not present in the target domain. Most successful algorithms use model selection strategies that rely on target labels to find the best hyper-parameters and/or models along training. However, these strategies violate the main assumption in PDA: only unlabeled target domain samples are available. Moreover, there are also inconsistencies in the experimental settings - architecture, hyper-parameter tuning, number of runs - yielding unfair comparisons. The main goal of this work is to provide a realistic evaluation of PDA methods with the different model selection strategies under a consistent evaluation protocol. We evaluate 7 representative PDA algorithms on 2 different real-world datasets using 7 different model selection strategies. Our two main findings are: (i) without target labels for model selection, the accuracy of the methods decreases up to 30 percentage points; (ii) only one method and model selection pair performs well on both datasets. Experiments were performed with our PyTorch framework, BenchmarkPDA, which we open source.
Improved Predictive Uncertainty using Corruption-based Calibration
Jun 07, 2021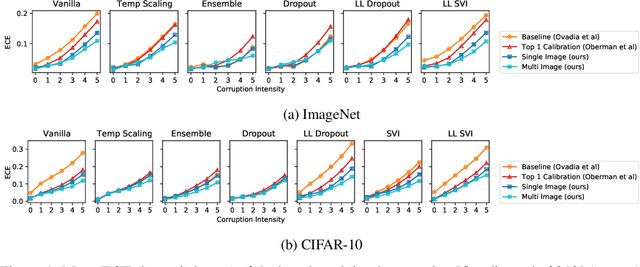
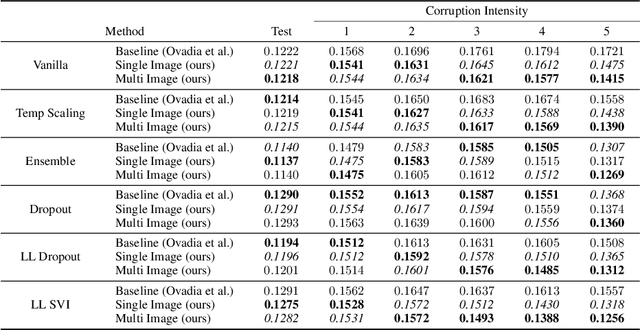
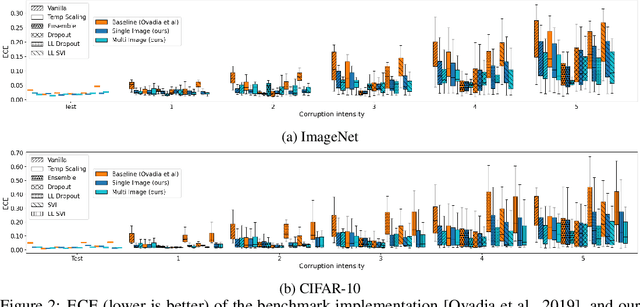
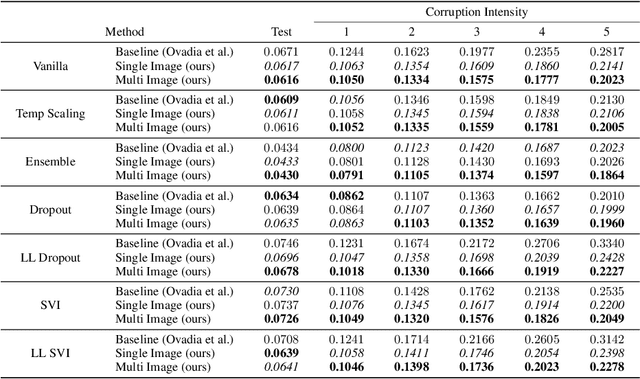
We propose a simple post hoc calibration method to estimate the confidence/uncertainty that a model prediction is correct on data with covariate shift, as represented by the large-scale corrupted data benchmark [Ovadia et al, 2019]. We achieve this by synthesizing surrogate calibration sets by corrupting the calibration set with varying intensities of a known corruption. Our method demonstrates significant improvements on the benchmark on a wide range of covariate shifts.
Bias Mitigation of Face Recognition Models Through Calibration
Jun 07, 2021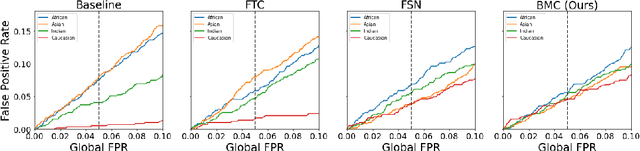

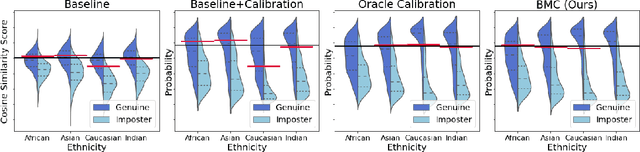
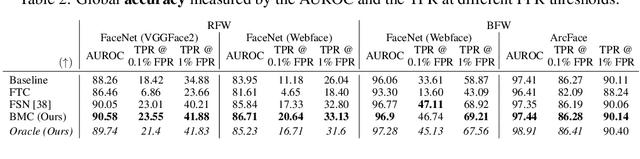
Face recognition models suffer from bias: for example, the probability of a false positive (incorrect face match) strongly depends on sensitive attributes like ethnicity. As a result, these models may disproportionately and negatively impact minority groups when used in law enforcement. In this work, we introduce the Bias Mitigation Calibration (BMC) method, which (i) increases model accuracy (improving the state-of-the-art), (ii) produces fairly-calibrated probabilities, (iii) significantly reduces the gap in the false positive rates, and (iv) does not require knowledge of the sensitive attribute.