 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
Measuring Goal-Directedness
Dec 06, 2024



We define maximum entropy goal-directedness (MEG), a formal measure of goal-directedness in causal models and Markov decision processes, and give algorithms for computing it. Measuring goal-directedness is important, as it is a critical element of many concerns about harm from AI. It is also of philosophical interest, as goal-directedness is a key aspect of agency. MEG is based on an adaptation of the maximum causal entropy framework used in inverse reinforcement learning. It can measure goal-directedness with respect to a known utility function, a hypothesis class of utility functions, or a set of random variables. We prove that MEG satisfies several desiderata and demonstrate our algorithms with small-scale experiments.
Can a Bayesian Oracle Prevent Harm from an Agent?
Aug 09, 2024

Is there a way to design powerful AI systems based on machine learning methods that would satisfy probabilistic safety guarantees? With the long-term goal of obtaining a probabilistic guarantee that would apply in every context, we consider estimating a context-dependent bound on the probability of violating a given safety specification. Such a risk evaluation would need to be performed at run-time to provide a guardrail against dangerous actions of an AI. Noting that different plausible hypotheses about the world could produce very different outcomes, and because we do not know which one is right, we derive bounds on the safety violation probability predicted under the true but unknown hypothesis. Such bounds could be used to reject potentially dangerous actions. Our main results involve searching for cautious but plausible hypotheses, obtained by a maximization that involves Bayesian posteriors over hypotheses. We consider two forms of this result, in the iid case and in the non-iid case, and conclude with open problems towards turning such theoretical results into practical AI guardrails.
The Reasons that Agents Act: Intention and Instrumental Goals
Feb 15, 2024



Intention is an important and challenging concept in AI. It is important because it underlies many other concepts we care about, such as agency, manipulation, legal responsibility, and blame. However, ascribing intent to AI systems is contentious, and there is no universally accepted theory of intention applicable to AI agents. We operationalise the intention with which an agent acts, relating to the reasons it chooses its decision. We introduce a formal definition of intention in structural causal influence models, grounded in the philosophy literature on intent and applicable to real-world machine learning systems. Through a number of examples and results, we show that our definition captures the intuitive notion of intent and satisfies desiderata set-out by past work. In addition, we show how our definition relates to past concepts, including actual causality, and the notion of instrumental goals, which is a core idea in the literature on safe AI agents. Finally, we demonstrate how our definition can be used to infer the intentions of reinforcement learning agents and language models from their behaviour.
Characterising Decision Theories with Mechanised Causal Graphs
Jul 20, 2023How should my own decisions affect my beliefs about the outcomes I expect to achieve? If taking a certain action makes me view myself as a certain type of person, it might affect how I think others view me, and how I view others who are similar to me. This can influence my expected utility calculations and change which action I perceive to be best. Whether and how it should is subject to debate, with contenders for how to think about it including evidential decision theory, causal decision theory, and functional decision theory. In this paper, we show that mechanised causal models can be used to characterise and differentiate the most important decision theories, and generate a taxonomy of different decision theories.
On Imperfect Recall in Multi-Agent Influence Diagrams
Jul 11, 2023

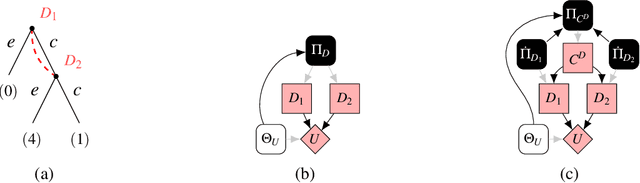

Multi-agent influence diagrams (MAIDs) are a popular game-theoretic model based on Bayesian networks. In some settings, MAIDs offer significant advantages over extensive-form game representations. Previous work on MAIDs has assumed that agents employ behavioural policies, which set independent conditional probability distributions over actions for each of their decisions. In settings with imperfect recall, however, a Nash equilibrium in behavioural policies may not exist. We overcome this by showing how to solve MAIDs with forgetful and absent-minded agents using mixed policies and two types of correlated equilibrium. We also analyse the computational complexity of key decision problems in MAIDs, and explore tractable cases. Finally, we describe applications of MAIDs to Markov games and team situations, where imperfect recall is often unavoidable.
* In Proceedings TARK 2023, arXiv:2307.04005
Discovering Agents
Aug 24, 2022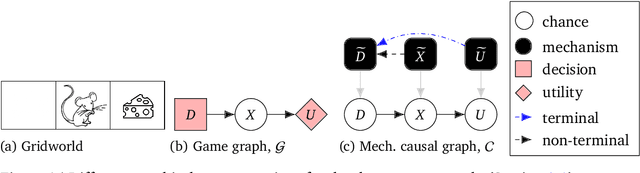
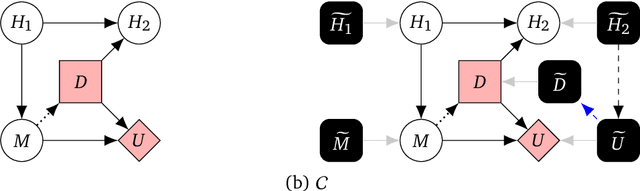
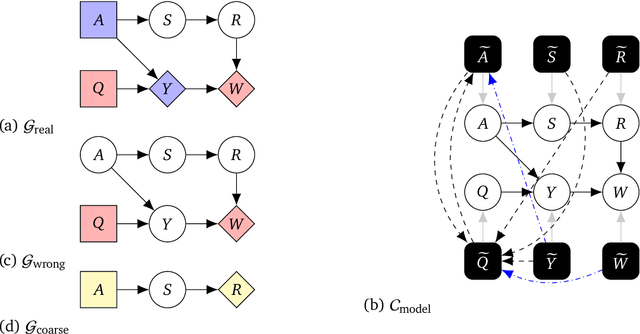

Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams. We demonstrate our approach by resolving some previous confusions caused by incorrect causal modelling of agents.