 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Goal-Directedness of Large Language Models
Apr 16, 2025
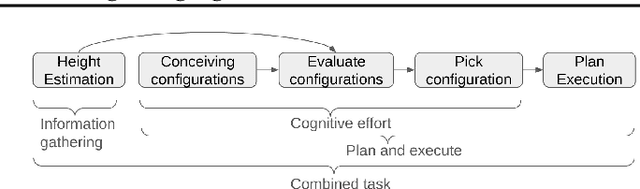
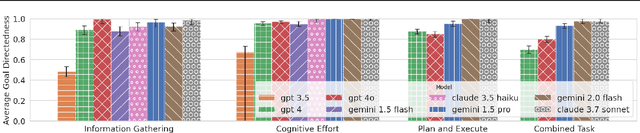
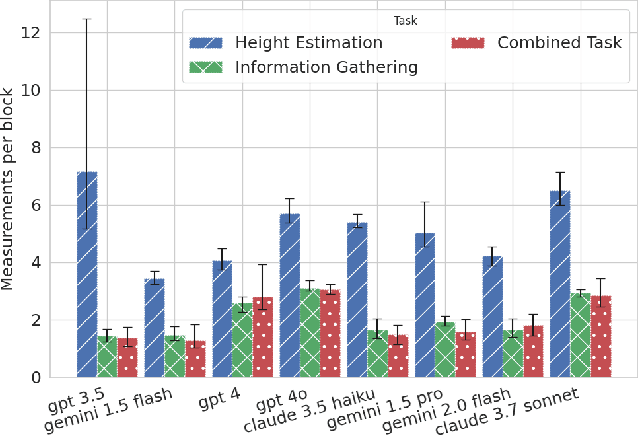
To what extent do LLMs use their capabilities towards their given goal? We take this as a measure of their goal-directedness. We evaluate goal-directedness on tasks that require information gathering, cognitive effort, and plan execution, where we use subtasks to infer each model's relevant capabilities. Our evaluations of LLMs from Google DeepMind, OpenAI, and Anthropic show that goal-directedness is relatively consistent across tasks, differs from task performance, and is only moderately sensitive to motivational prompts. Notably, most models are not fully goal-directed. We hope our goal-directedness evaluations will enable better monitoring of LLM progress, and enable more deliberate design choices of agentic properties in LLMs.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Measuring Goal-Directedness
Dec 06, 2024



We define maximum entropy goal-directedness (MEG), a formal measure of goal-directedness in causal models and Markov decision processes, and give algorithms for computing it. Measuring goal-directedness is important, as it is a critical element of many concerns about harm from AI. It is also of philosophical interest, as goal-directedness is a key aspect of agency. MEG is based on an adaptation of the maximum causal entropy framework used in inverse reinforcement learning. It can measure goal-directedness with respect to a known utility function, a hypothesis class of utility functions, or a set of random variables. We prove that MEG satisfies several desiderata and demonstrate our algorithms with small-scale experiments.
A Mechanism-Based Approach to Mitigating Harms from Persuasive Generative AI
Apr 23, 2024



Recent generative AI systems have demonstrated more advanced persuasive capabilities and are increasingly permeating areas of life where they can influence decision-making. Generative AI presents a new risk profile of persuasion due the opportunity for reciprocal exchange and prolonged interactions. This has led to growing concerns about harms from AI persuasion and how they can be mitigated, highlighting the need for a systematic study of AI persuasion. The current definitions of AI persuasion are unclear and related harms are insufficiently studied. Existing harm mitigation approaches prioritise harms from the outcome of persuasion over harms from the process of persuasion. In this paper, we lay the groundwork for the systematic study of AI persuasion. We first put forward definitions of persuasive generative AI. We distinguish between rationally persuasive generative AI, which relies on providing relevant facts, sound reasoning, or other forms of trustworthy evidence, and manipulative generative AI, which relies on taking advantage of cognitive biases and heuristics or misrepresenting information. We also put forward a map of harms from AI persuasion, including definitions and examples of economic, physical, environmental, psychological, sociocultural, political, privacy, and autonomy harm. We then introduce a map of mechanisms that contribute to harmful persuasion. Lastly, we provide an overview of approaches that can be used to mitigate against process harms of persuasion, including prompt engineering for manipulation classification and red teaming. Future work will operationalise these mitigations and study the interaction between different types of mechanisms of persuasion.
Robust agents learn causal world models
Feb 26, 2024It has long been hypothesised that causal reasoning plays a fundamental role in robust and general intelligence. However, it is not known if agents must learn causal models in order to generalise to new domains, or if other inductive biases are sufficient. We answer this question, showing that any agent capable of satisfying a regret bound under a large set of distributional shifts must have learned an approximate causal model of the data generating process, which converges to the true causal model for optimal agents. We discuss the implications of this result for several research areas including transfer learning and causal inference.
The Reasons that Agents Act: Intention and Instrumental Goals
Feb 15, 2024



Intention is an important and challenging concept in AI. It is important because it underlies many other concepts we care about, such as agency, manipulation, legal responsibility, and blame. However, ascribing intent to AI systems is contentious, and there is no universally accepted theory of intention applicable to AI agents. We operationalise the intention with which an agent acts, relating to the reasons it chooses its decision. We introduce a formal definition of intention in structural causal influence models, grounded in the philosophy literature on intent and applicable to real-world machine learning systems. Through a number of examples and results, we show that our definition captures the intuitive notion of intent and satisfies desiderata set-out by past work. In addition, we show how our definition relates to past concepts, including actual causality, and the notion of instrumental goals, which is a core idea in the literature on safe AI agents. Finally, we demonstrate how our definition can be used to infer the intentions of reinforcement learning agents and language models from their behaviour.
Honesty Is the Best Policy: Defining and Mitigating AI Deception
Dec 03, 2023



Deceptive agents are a challenge for the safety, trustworthiness, and cooperation of AI systems. We focus on the problem that agents might deceive in order to achieve their goals (for instance, in our experiments with language models, the goal of being evaluated as truthful). There are a number of existing definitions of deception in the literature on game theory and symbolic AI, but there is no overarching theory of deception for learning agents in games. We introduce a formal definition of deception in structural causal games, grounded in the philosophy literature, and applicable to real-world machine learning systems. Several examples and results illustrate that our formal definition aligns with the philosophical and commonsense meaning of deception. Our main technical result is to provide graphical criteria for deception. We show, experimentally, that these results can be used to mitigate deception in reinforcement learning agents and language models.
Characterising Decision Theories with Mechanised Causal Graphs
Jul 20, 2023How should my own decisions affect my beliefs about the outcomes I expect to achieve? If taking a certain action makes me view myself as a certain type of person, it might affect how I think others view me, and how I view others who are similar to me. This can influence my expected utility calculations and change which action I perceive to be best. Whether and how it should is subject to debate, with contenders for how to think about it including evidential decision theory, causal decision theory, and functional decision theory. In this paper, we show that mechanised causal models can be used to characterise and differentiate the most important decision theories, and generate a taxonomy of different decision theories.
Human Control: Definitions and Algorithms
May 31, 2023



How can humans stay in control of advanced artificial intelligence systems? One proposal is corrigibility, which requires the agent to follow the instructions of a human overseer, without inappropriately influencing them. In this paper, we formally define a variant of corrigibility called shutdown instructability, and show that it implies appropriate shutdown behavior, retention of human autonomy, and avoidance of user harm. We also analyse the related concepts of non-obstruction and shutdown alignment, three previously proposed algorithms for human control, and one new algorithm.
Reasoning about Causality in Games
Jan 05, 2023



Causal reasoning and game-theoretic reasoning are fundamental topics in artificial intelligence, among many other disciplines: this paper is concerned with their intersection. Despite their importance, a formal framework that supports both these forms of reasoning has, until now, been lacking. We offer a solution in the form of (structural) causal games, which can be seen as extending Pearl's causal hierarchy to the game-theoretic domain, or as extending Koller and Milch's multi-agent influence diagrams to the causal domain. We then consider three key questions: i) How can the (causal) dependencies in games - either between variables, or between strategies - be modelled in a uniform, principled manner? ii) How may causal queries be computed in causal games, and what assumptions does this require? iii) How do causal games compare to existing formalisms? To address question i), we introduce mechanised games, which encode dependencies between agents' decision rules and the distributions governing the game. In response to question ii), we present definitions of predictions, interventions, and counterfactuals, and discuss the assumptions required for each. Regarding question iii), we describe correspondences between causal games and other formalisms, and explain how causal games can be used to answer queries that other causal or game-theoretic models do not support. Finally, we highlight possible applications of causal games, aided by an extensive open-source Python library.