 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDE-HNN: An effective neural model for Circuit Netlist representation
Apr 05, 2024



The run-time for optimization tools used in chip design has grown with the complexity of designs to the point where it can take several days to go through one design cycle which has become a bottleneck. Designers want fast tools that can quickly give feedback on a design. Using the input and output data of the tools from past designs, one can attempt to build a machine learning model that predicts the outcome of a design in significantly shorter time than running the tool. The accuracy of such models is affected by the representation of the design data, which is usually a netlist that describes the elements of the digital circuit and how they are connected. Graph representations for the netlist together with graph neural networks have been investigated for such models. However, the characteristics of netlists pose several challenges for existing graph learning frameworks, due to the large number of nodes and the importance of long-range interactions between nodes. To address these challenges, we represent the netlist as a directed hypergraph and propose a Directional Equivariant Hypergraph Neural Network (DE-HNN) for the effective learning of (directed) hypergraphs. Theoretically, we show that our DE-HNN can universally approximate any node or hyperedge based function that satisfies certain permutation equivariant and invariant properties natural for directed hypergraphs. We compare the proposed DE-HNN with several State-of-the-art (SOTA) machine learning models for (hyper)graphs and netlists, and show that the DE-HNN significantly outperforms them in predicting the outcome of optimized place-and-route tools directly from the input netlists. Our source code and the netlists data used are publicly available at https://github.com/YusuLab/chips.git
Less is More: Hop-Wise Graph Attention for Scalable and Generalizable Learning on Circuits
Mar 06, 2024While graph neural networks (GNNs) have gained popularity for learning circuit representations in various electronic design automation (EDA) tasks, they face challenges in scalability when applied to large graphs and exhibit limited generalizability to new designs. These limitations make them less practical for addressing large-scale, complex circuit problems. In this work we propose HOGA, a novel attention-based model for learning circuit representations in a scalable and generalizable manner. HOGA first computes hop-wise features per node prior to model training. Subsequently, the hop-wise features are solely used to produce node representations through a gated self-attention module, which adaptively learns important features among different hops without involving the graph topology. As a result, HOGA is adaptive to various structures across different circuits and can be efficiently trained in a distributed manner. To demonstrate the efficacy of HOGA, we consider two representative EDA tasks: quality of results (QoR) prediction and functional reasoning. Our experimental results indicate that (1) HOGA reduces estimation error over conventional GNNs by 46.76% for predicting QoR after logic synthesis; (2) HOGA improves 10.0% reasoning accuracy over GNNs for identifying functional blocks on unseen gate-level netlists after complex technology mapping; (3) The training time for HOGA almost linearly decreases with an increase in computing resources.
Human Control: Definitions and Algorithms
May 31, 2023



How can humans stay in control of advanced artificial intelligence systems? One proposal is corrigibility, which requires the agent to follow the instructions of a human overseer, without inappropriately influencing them. In this paper, we formally define a variant of corrigibility called shutdown instructability, and show that it implies appropriate shutdown behavior, retention of human autonomy, and avoidance of user harm. We also analyse the related concepts of non-obstruction and shutdown alignment, three previously proposed algorithms for human control, and one new algorithm.
Reasoning about Causality in Games
Jan 05, 2023



Causal reasoning and game-theoretic reasoning are fundamental topics in artificial intelligence, among many other disciplines: this paper is concerned with their intersection. Despite their importance, a formal framework that supports both these forms of reasoning has, until now, been lacking. We offer a solution in the form of (structural) causal games, which can be seen as extending Pearl's causal hierarchy to the game-theoretic domain, or as extending Koller and Milch's multi-agent influence diagrams to the causal domain. We then consider three key questions: i) How can the (causal) dependencies in games - either between variables, or between strategies - be modelled in a uniform, principled manner? ii) How may causal queries be computed in causal games, and what assumptions does this require? iii) How do causal games compare to existing formalisms? To address question i), we introduce mechanised games, which encode dependencies between agents' decision rules and the distributions governing the game. In response to question ii), we present definitions of predictions, interventions, and counterfactuals, and discuss the assumptions required for each. Regarding question iii), we describe correspondences between causal games and other formalisms, and explain how causal games can be used to answer queries that other causal or game-theoretic models do not support. Finally, we highlight possible applications of causal games, aided by an extensive open-source Python library.
Path-Specific Objectives for Safer Agent Incentives
Apr 21, 2022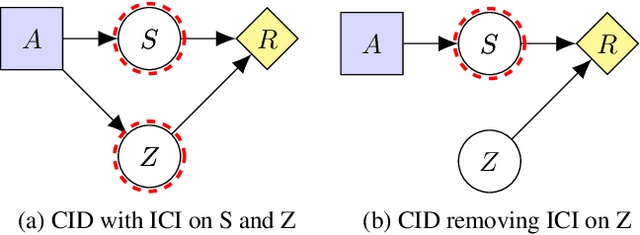


We present a general framework for training safe agents whose naive incentives are unsafe. As an example, manipulative or deceptive behaviour can improve rewards but should be avoided. Most approaches fail here: agents maximize expected return by any means necessary. We formally describe settings with 'delicate' parts of the state which should not be used as a means to an end. We then train agents to maximize the causal effect of actions on the expected return which is not mediated by the delicate parts of state, using Causal Influence Diagram analysis. The resulting agents have no incentive to control the delicate state. We further show how our framework unifies and generalizes existing proposals.
Too Big to Fail? Active Few-Shot Learning Guided Logic Synthesis
Apr 05, 2022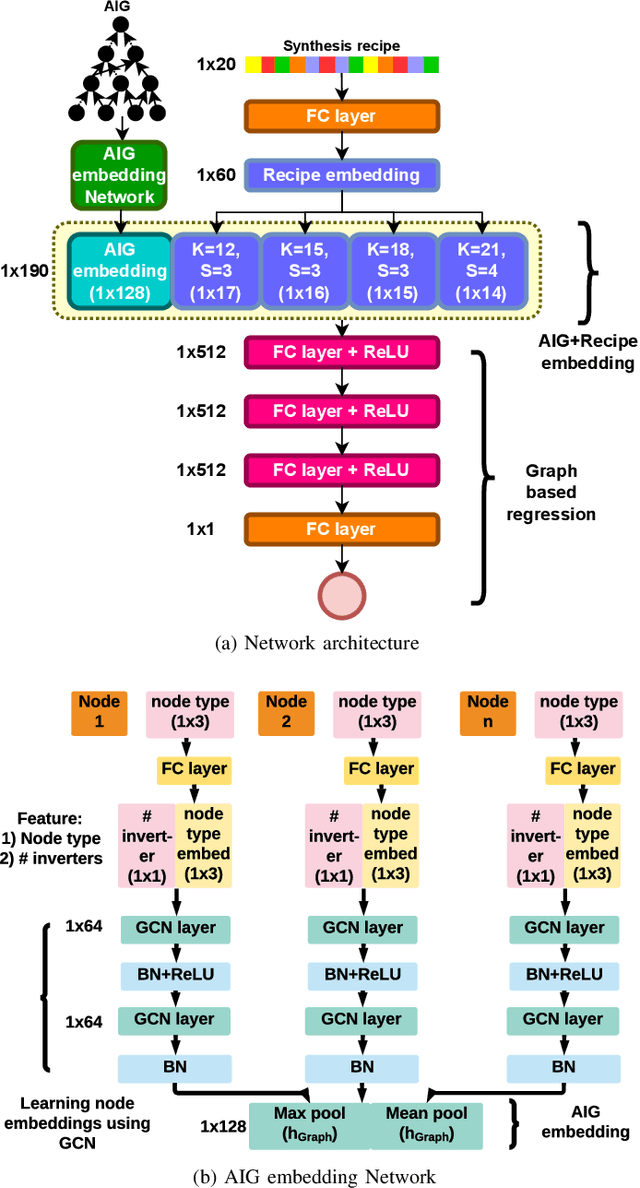
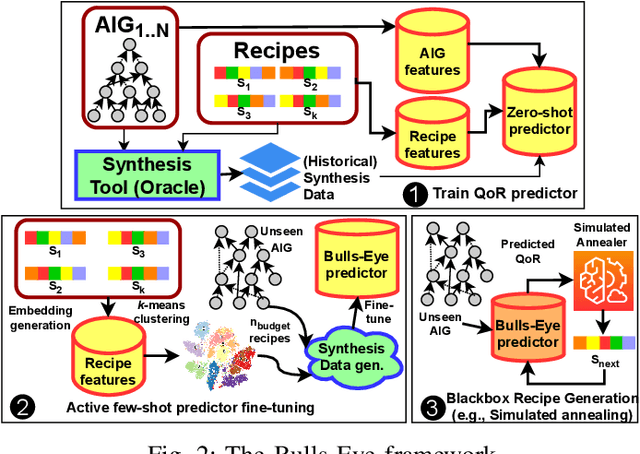
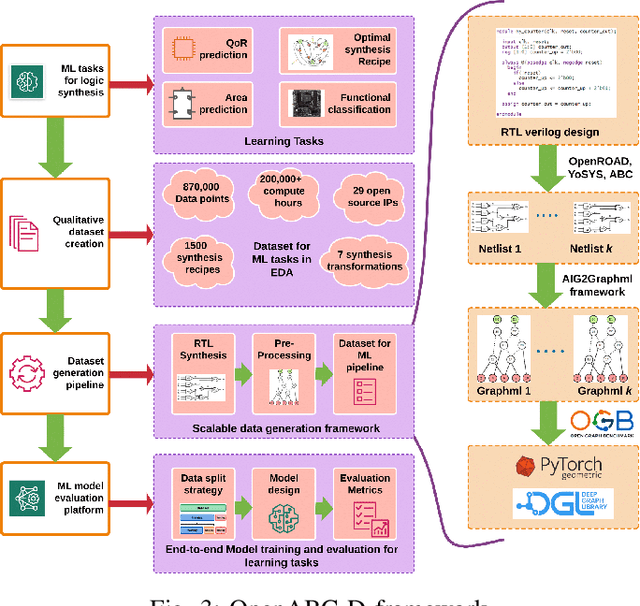
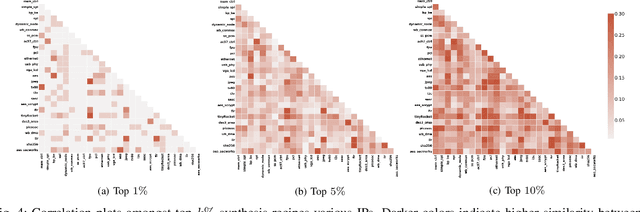
Generating sub-optimal synthesis transformation sequences ("synthesis recipe") is an important problem in logic synthesis. Manually crafted synthesis recipes have poor quality. State-of-the art machine learning (ML) works to generate synthesis recipes do not scale to large netlists as the models need to be trained from scratch, for which training data is collected using time consuming synthesis runs. We propose a new approach, Bulls-Eye, that fine-tunes a pre-trained model on past synthesis data to accurately predict the quality of a synthesis recipe for an unseen netlist. This approach on achieves 2x-10x run-time improvement and better quality-of-result (QoR) than state-of-the-art machine learning approaches.
A Complete Criterion for Value of Information in Soluble Influence Diagrams
Feb 23, 2022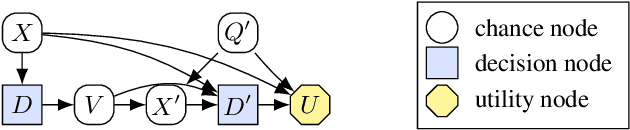
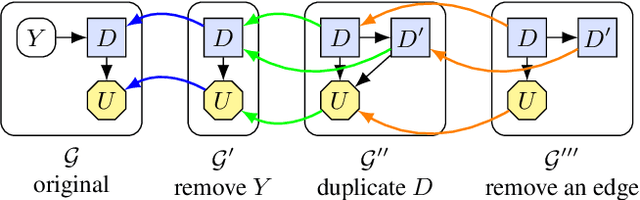
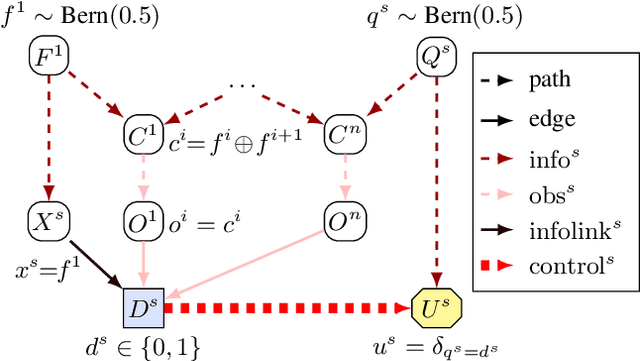
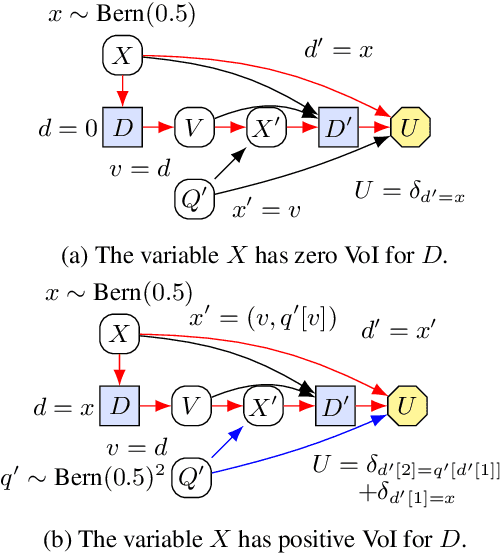
Influence diagrams have recently been used to analyse the safety and fairness properties of AI systems. A key building block for this analysis is a graphical criterion for value of information (VoI). This paper establishes the first complete graphical criterion for VoI in influence diagrams with multiple decisions. Along the way, we establish two important techniques for proving properties of multi-decision influence diagrams: ID homomorphisms are structure-preserving transformations of influence diagrams, while a Tree of Systems is collection of paths that captures how information and control can flow in an influence diagram.
Why Fair Labels Can Yield Unfair Predictions: Graphical Conditions for Introduced Unfairness
Feb 23, 2022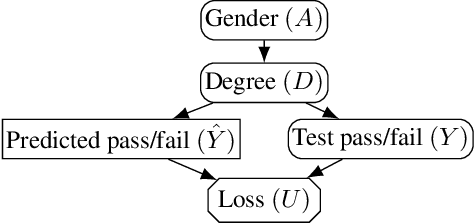
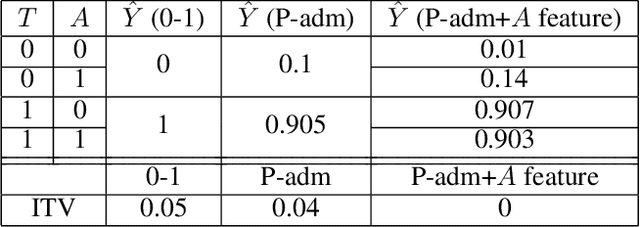
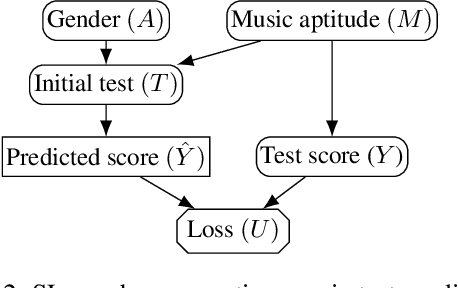
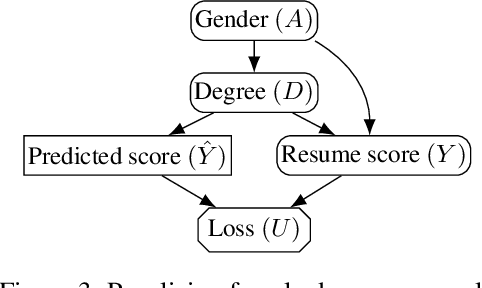
In addition to reproducing discriminatory relationships in the training data, machine learning systems can also introduce or amplify discriminatory effects. We refer to this as introduced unfairness, and investigate the conditions under which it may arise. To this end, we propose introduced total variation as a measure of introduced unfairness, and establish graphical conditions under which it may be incentivised to occur. These criteria imply that adding the sensitive attribute as a feature removes the incentive for introduced variation under well-behaved loss functions. Additionally, taking a causal perspective, introduced path-specific effects shed light on the issue of when specific paths should be considered fair.
Agent Incentives: A Causal Perspective
Feb 02, 2021

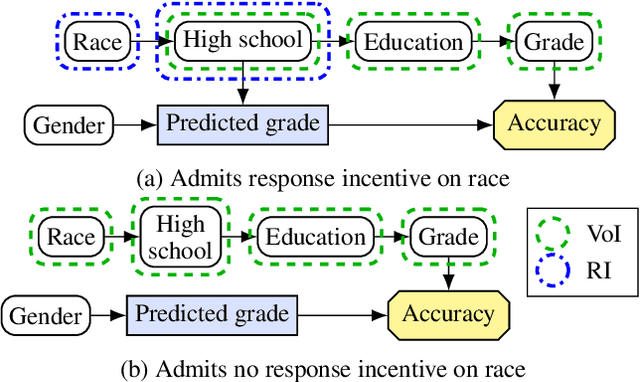
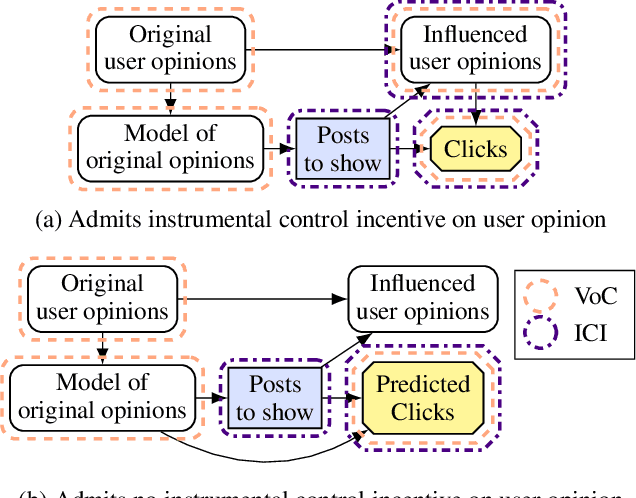
We present a framework for analysing agent incentives using causal influence diagrams. We establish that a well-known criterion for value of information is complete. We propose a new graphical criterion for value of control, establishing its soundness and completeness. We also introduce two new concepts for incentive analysis: response incentives indicate which changes in the environment affect an optimal decision, while instrumental control incentives establish whether an agent can influence its utility via a variable X. For both new concepts, we provide sound and complete graphical criteria. We show by example how these results can help with evaluating the safety and fairness of an AI system.
The Incentives that Shape Behaviour
Jan 20, 2020

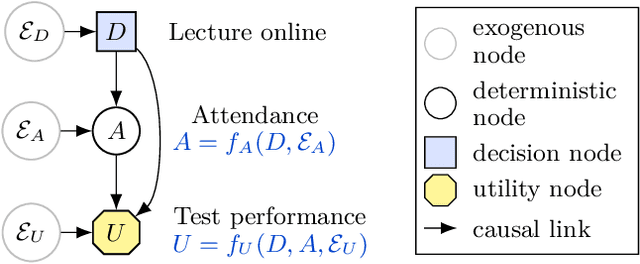
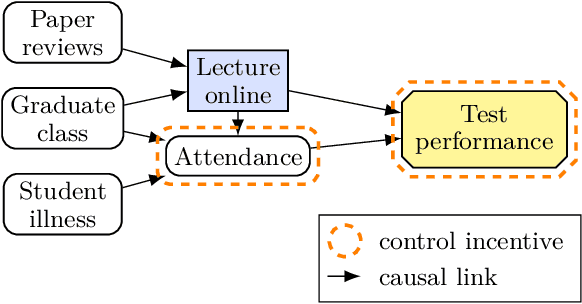
Which variables does an agent have an incentive to control with its decision, and which variables does it have an incentive to respond to? We formalise these incentives, and demonstrate unique graphical criteria for detecting them in any single decision causal influence diagram. To this end, we introduce structural causal influence models, a hybrid of the influence diagram and structural causal model frameworks. Finally, we illustrate how these incentives predict agent incentives in both fairness and AI safety applications.