 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOGATE: Automated Clock Gating via Toggling-Aware LLM-based RTL Rewriting
Jun 16, 2026Fine-grain clock gating (FGCG) is among the most effective techniques for reducing dynamic power, yet current FGCG optimization flows remain largely manual. Recent LLM-based RTL optimization approaches remain limited by two key drawbacks: (1) the inability to process long waveform traces spanning millions of cycles, and (2) the difficulty of scaling optimization to large hierarchical codebases while preserving correctness. In this work, we present AUTOGATE, the first agentic framework for industry-grade RTL power optimization, enabling workload-aware clock-gating optimization across large hierarchical codebases. AUTOGATE introduces a Machine Learning (ML)-LLM co-design that bridges waveform-level analysis and RTL rewriting. Specifically, we design an ML-based clustering algorithm that distills raw toggling traces into compact, structured representations that guide LLM-based RTL rewriting. This enables accurate identification and application of clock-gating opportunities without requiring LLMs to directly process raw waveform data. To enhance scalability, AUTOGATE employs a hierarchical multi-agent architecture that decomposes large designs into independently optimizable modules, enabling coordinated optimization across deep design hierarchies. We evaluate AUTOGATE on a diverse set of designs ranging from small RTL designs to large industrial-grade codebases. Experimental results show that AUTOGATE consistently reduces dynamic power relative to baselines. Across the small-design suite, AUTOGATE reduces dynamic power by 49.31% on average. On industry-scale designs, it achieves 19.34% and 7.96% dynamic power reductions on NVDLA and BlackParrot, respectively, and up to 6.86% on highly optimized proprietary production designs.
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
ACE-RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs
Feb 10, 2026Recent advances in large language models (LLMs) have sparked growing interest in applying them to hardware design automation, particularly for accurate RTL code generation. Prior efforts follow two largely independent paths: (i) training domain-adapted RTL models to internalize hardware semantics, (ii) developing agentic systems that leverage frontier generic LLMs guided by simulation feedback. However, these two paths exhibit complementary strengths and weaknesses. In this work, we present ACE-RTL that unifies both directions through Agentic Context Evolution (ACE). ACE-RTL integrates an RTL-specialized LLM, trained on a large-scale dataset of 1.7 million RTL samples, with a frontier reasoning LLM through three synergistic components: the generator, reflector, and coordinator. These components iteratively refine RTL code toward functional correctness. We further introduce a parallel scaling strategy that significantly reduces the number of iterations required to reach correct solutions. On the Comprehensive Verilog Design Problems (CVDP) benchmark, ACE-RTL achieves up to a 44.87% pass rate improvement over 14 competitive baselines while requiring only four iterations on average.
GRPO with State Mutations: Improving LLM-Based Hardware Test Plan Generation
Jan 12, 2026RTL design often relies heavily on ad-hoc testbench creation early in the design cycle. While large language models (LLMs) show promise for RTL code generation, their ability to reason about hardware specifications and generate targeted test plans remains largely unexplored. We present the first systematic study of LLM reasoning capabilities for RTL verification stimuli generation, establishing a two-stage framework that decomposes test plan generation from testbench execution. Our benchmark reveals that state-of-the-art models, including DeepSeek-R1 and Claude-4.0-Sonnet, achieve only 15.7-21.7% success rates on generating stimuli that pass golden RTL designs. To improve LLM generated stimuli, we develop a comprehensive training methodology combining supervised fine-tuning with a novel reinforcement learning approach, GRPO with State Mutation (GRPO-SMu), which enhances exploration by varying input mutations. Our approach leverages a tree-based branching mutation strategy to construct training data comprising equivalent and mutated trees, moving beyond linear mutation approaches to provide rich learning signals. Training on this curated dataset, our 7B parameter model achieves a 33.3% golden test pass rate and a 13.9% mutation detection rate, representing a 17.6% absolute improvement over baseline and outperforming much larger general-purpose models. These results demonstrate that specialized training methodologies can significantly enhance LLM reasoning capabilities for hardware verification tasks, establishing a foundation for automated sub-unit testing in semiconductor design workflows.
ReVEAL: GNN-Guided Reverse Engineering for Formal Verification of Optimized Multipliers
Dec 24, 2025We present ReVEAL, a graph-learning-based method for reverse engineering of multiplier architectures to improve algebraic circuit verification techniques. Our framework leverages structural graph features and learning-driven inference to identify architecture patterns at scale, enabling robust handling of large optimized multipliers. We demonstrate applicability across diverse multiplier benchmarks and show improvements in scalability and accuracy compared to traditional rule-based approaches. The method integrates smoothly with existing verification flows and supports downstream algebraic proof strategies.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Jun 05, 2025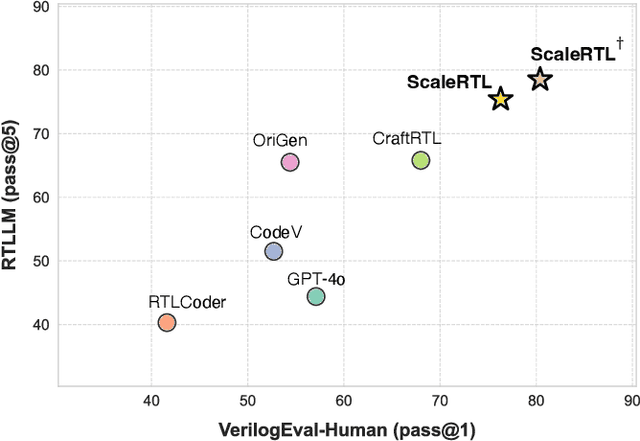
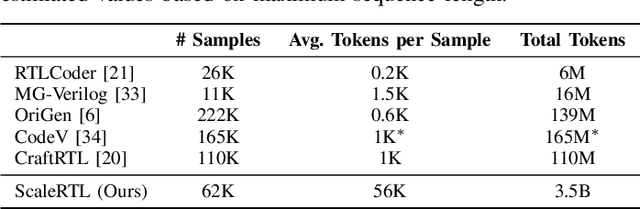
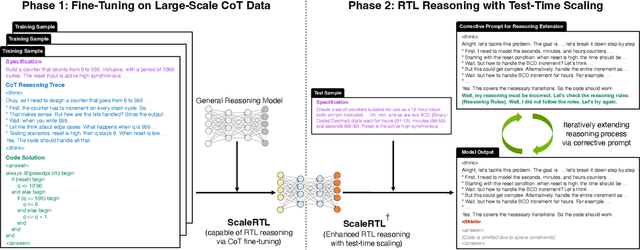
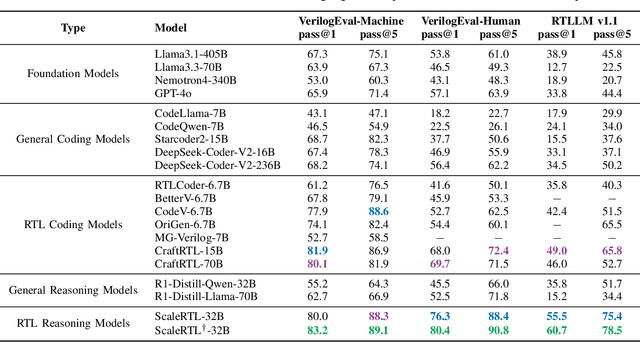
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
JARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025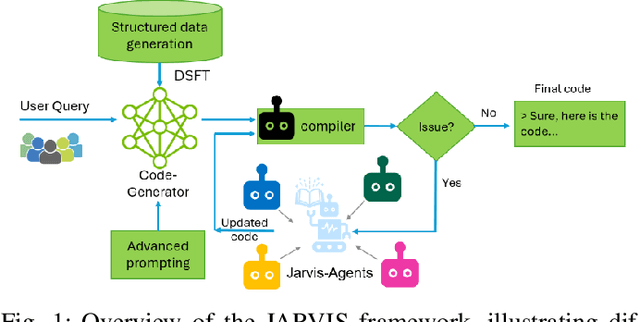
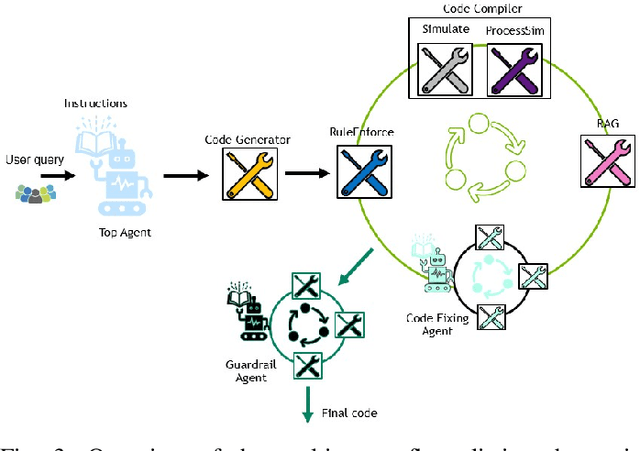
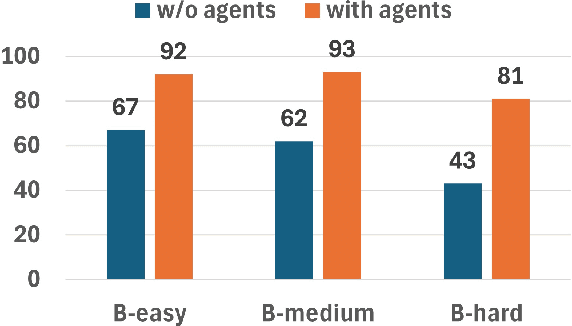
This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
Graph Learning at Scale: Characterizing and Optimizing Pre-Propagation GNNs
Apr 17, 2025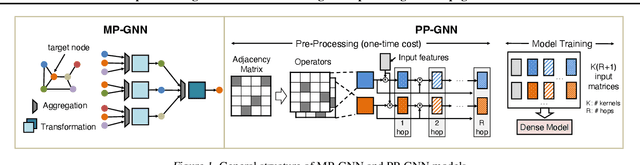

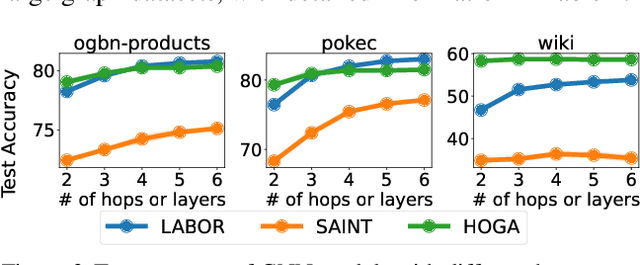

Graph neural networks (GNNs) are widely used for learning node embeddings in graphs, typically adopting a message-passing scheme. This approach, however, leads to the neighbor explosion problem, with exponentially growing computational and memory demands as layers increase. Graph sampling has become the predominant method for scaling GNNs to large graphs, mitigating but not fully solving the issue. Pre-propagation GNNs (PP-GNNs) represent a new class of models that decouple feature propagation from training through pre-processing, addressing neighbor explosion in theory. Yet, their practical advantages and system-level optimizations remain underexplored. This paper provides a comprehensive characterization of PP-GNNs, comparing them with graph-sampling-based methods in training efficiency, scalability, and accuracy. While PP-GNNs achieve comparable accuracy, we identify data loading as the key bottleneck for training efficiency and input expansion as a major scalability challenge. To address these issues, we propose optimized data loading schemes and tailored training methods that improve PP-GNN training throughput by an average of 15$\times$ over the PP-GNN baselines, with speedup of up to 2 orders of magnitude compared to sampling-based GNNs on large graph benchmarks. Our implementation is publicly available at https://github.com/cornell-zhang/preprop-gnn.
ChipAlign: Instruction Alignment in Large Language Models for Chip Design via Geodesic Interpolation
Dec 15, 2024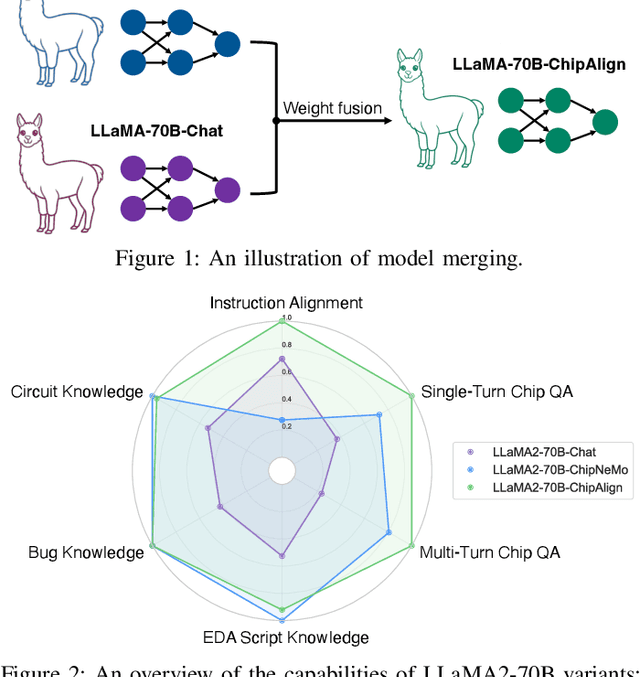
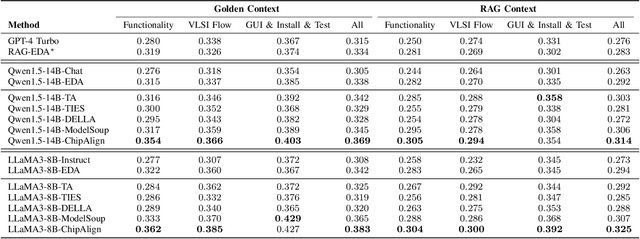

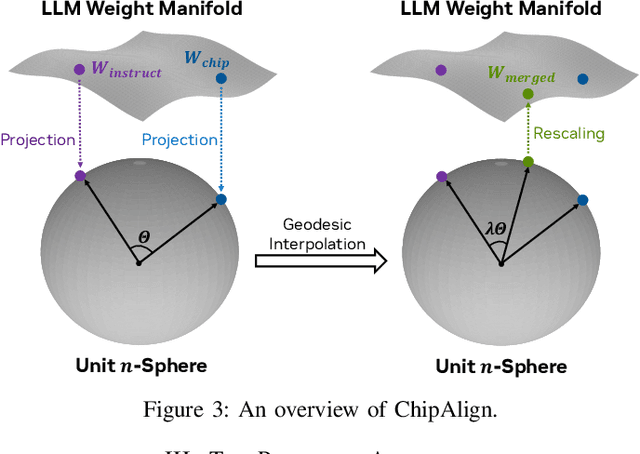
Recent advancements in large language models (LLMs) have expanded their application across various domains, including chip design, where domain-adapted chip models like ChipNeMo have emerged. However, these models often struggle with instruction alignment, a crucial capability for LLMs that involves following explicit human directives. This limitation impedes the practical application of chip LLMs, including serving as assistant chatbots for hardware design engineers. In this work, we introduce ChipAlign, a novel approach that utilizes a training-free model merging strategy, combining the strengths of a general instruction-aligned LLM with a chip-specific LLM. By considering the underlying manifold in the weight space, ChipAlign employs geodesic interpolation to effectively fuse the weights of input LLMs, producing a merged model that inherits strong instruction alignment and chip expertise from the respective instruction and chip LLMs. Our results demonstrate that ChipAlign significantly enhances instruction-following capabilities of existing chip LLMs, achieving up to a 26.6% improvement on the IFEval benchmark, while maintaining comparable expertise in the chip domain. This improvement in instruction alignment also translates to notable gains in instruction-involved QA tasks, delivering performance enhancements of 3.9% on the OpenROAD QA benchmark and 8.25% on production-level chip QA benchmarks, surpassing state-of-the-art baselines.