 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$V_1$: Unifying Generation and Self-Verification for Parallel Reasoners
Mar 04, 2026Test-time scaling for complex reasoning tasks shows that leveraging inference-time compute, by methods such as independently sampling and aggregating multiple solutions, results in significantly better task outcomes. However, a critical bottleneck is verification: sampling is only effective if correct solutions can be reliably identified among candidates. While existing approaches typically evaluate candidates independently via scalar scoring, we demonstrate that models are substantially stronger at pairwise self-verification. Leveraging this insight, we introduce $V_1$, a framework that unifies generation and verification through efficient pairwise ranking. $V_1$ comprises two components: $V_1$-Infer, an uncertainty-guided algorithm using a tournament-based ranking that dynamically allocates self-verification compute to candidate pairs whose relative correctness is most uncertain; and $V_1$-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier, ensuring the verifier adapts to the generator's evolving distribution. On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks, $V_1$-Infer improves Pass@1 by up to $10%$ over pointwise verification and outperforms recent test-time scaling methods while being significantly more efficient. Furthermore, $V_1$-PairRL achieves $7$--$9%$ test-time scaling gains over standard RL and pointwise joint training, and improves base Pass@1 by up to 8.7% over standard RL in a code-generation setting.
Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Feb 03, 2026Despite rapid progress in autoregressive video diffusion, an emerging system algorithm bottleneck limits both deployability and generation capability: KV cache memory. In autoregressive video generation models, the KV cache grows with generation history and quickly dominates GPU memory, often exceeding 30 GB, preventing deployment on widely available hardware. More critically, constrained KV cache budgets restrict the effective working memory, directly degrading long horizon consistency in identity, layout, and motion. To address this challenge, we present Quant VideoGen (QVG), a training free KV cache quantization framework for autoregressive video diffusion models. QVG leverages video spatiotemporal redundancy through Semantic Aware Smoothing, producing low magnitude, quantization friendly residuals. It further introduces Progressive Residual Quantization, a coarse to fine multi stage scheme that reduces quantization error while enabling a smooth quality memory trade off. Across LongCat Video, HY WorldPlay, and Self Forcing benchmarks, QVG establishes a new Pareto frontier between quality and memory efficiency, reducing KV cache memory by up to 7.0 times with less than 4% end to end latency overhead while consistently outperforming existing baselines in generation quality.
Reasoning and Tool-use Compete in Agentic RL:From Quantifying Interference to Disentangled Tuning
Feb 01, 2026Agentic Reinforcement Learning (ARL) focuses on training large language models (LLMs) to interleave reasoning with external tool execution to solve complex tasks. Most existing ARL methods train a single shared model parameters to support both reasoning and tool use behaviors, implicitly assuming that joint training leads to improved overall agent performance. Despite its widespread adoption, this assumption has rarely been examined empirically. In this paper, we systematically investigate this assumption by introducing a Linear Effect Attribution System(LEAS), which provides quantitative evidence of interference between reasoning and tool-use behaviors. Through an in-depth analysis, we show that these two capabilities often induce misaligned gradient directions, leading to training interference that undermines the effectiveness of joint optimization and challenges the prevailing ARL paradigm. To address this issue, we propose Disentangled Action Reasoning Tuning(DART), a simple and efficient framework that explicitly decouples parameter updates for reasoning and tool-use via separate low-rank adaptation modules. Experimental results show that DART consistently outperforms baseline methods with averaged 6.35 percent improvements and achieves performance comparable to multi-agent systems that explicitly separate tool-use and reasoning using a single model.
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
Jan 29, 2026Reinforcement Learning (RL) post-training alignment for language models is effective, but also costly and unstable in practice, owing to its complicated training process. To address this, we propose a training-free inference method to sample directly from the optimal RL policy. The transition probability applied to Masked Language Modeling (MLM) consists of a reference policy model and an energy term. Based on this, our algorithm, Energy-Guided Test-Time Scaling (ETS), estimates the key energy term via online Monte Carlo, with a provable convergence rate. Moreover, to ensure practical efficiency, ETS leverages modern acceleration frameworks alongside tailored importance sampling estimators, substantially reducing inference latency while provably preserving sampling quality. Experiments on MLM (including autoregressive models and diffusion language models) across reasoning, coding, and science benchmarks show that our ETS consistently improves generation quality, validating its effectiveness and design.
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
May 24, 2025Diffusion Transformers (DiTs) are essential for video generation but suffer from significant latency due to the quadratic complexity of attention. By computing only critical tokens, sparse attention reduces computational costs and offers a promising acceleration approach. However, we identify that existing methods fail to approach optimal generation quality under the same computation budget for two reasons: (1) Inaccurate critical token identification: current methods cluster tokens based on position rather than semantics, leading to imprecise aggregated representations. (2) Excessive computation waste: critical tokens are scattered among non-critical ones, leading to wasted computation on GPUs, which are optimized for processing contiguous tokens. In this paper, we propose SVG2, a training-free framework that maximizes identification accuracy and minimizes computation waste, achieving a Pareto frontier trade-off between generation quality and efficiency. The core of SVG2 is semantic-aware permutation, which clusters and reorders tokens based on semantic similarity using k-means. This approach ensures both a precise cluster representation, improving identification accuracy, and a densified layout of critical tokens, enabling efficient computation without padding. Additionally, SVG2 integrates top-p dynamic budget control and customized kernel implementations, achieving up to 2.30x and 1.89x speedup while maintaining a PSNR of up to 30 and 26 on HunyuanVideo and Wan 2.1, respectively.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025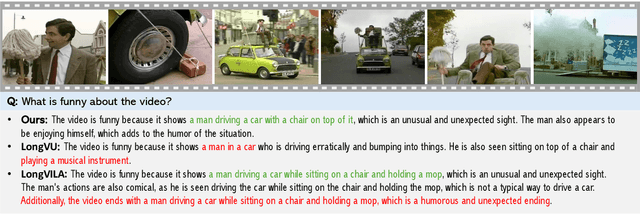
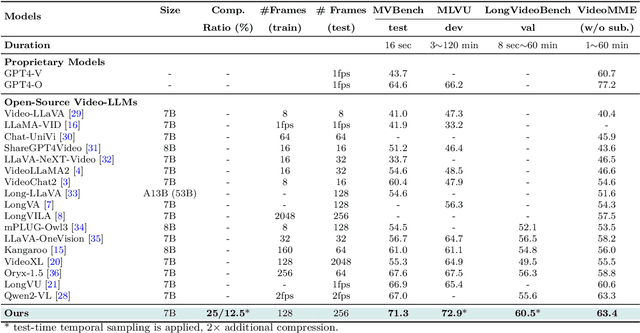
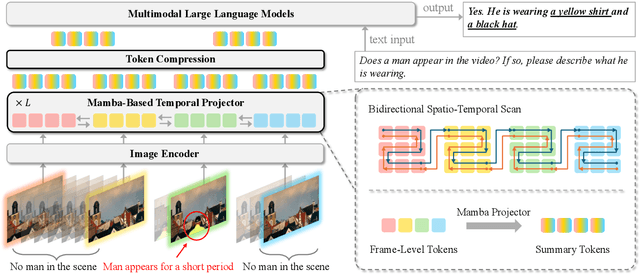
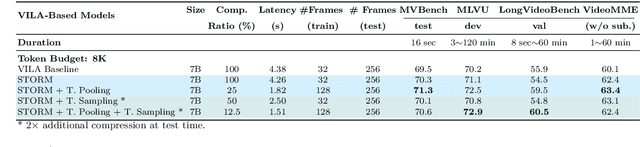
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
S*: Test Time Scaling for Code Generation
Feb 20, 2025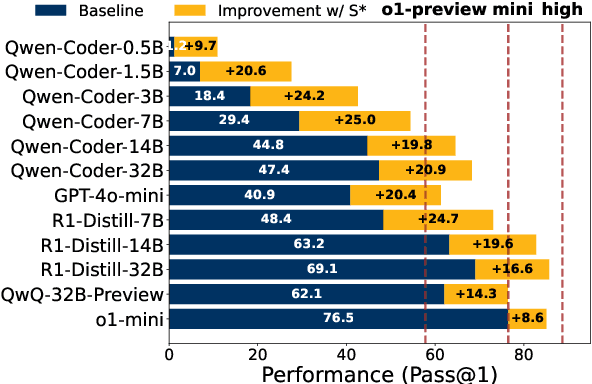
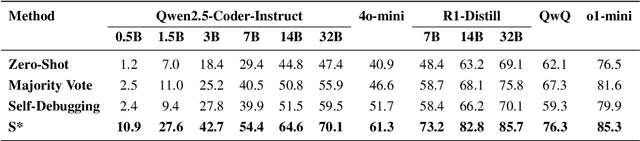
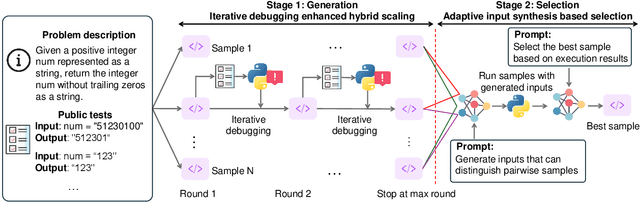
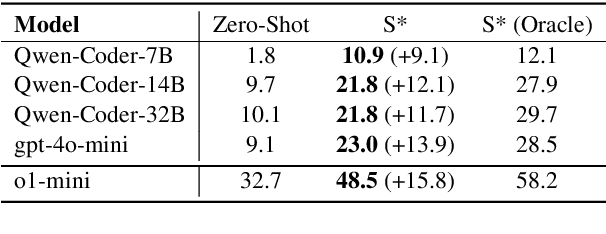
Increasing test-time compute for LLMs shows promise across domains but remains underexplored in code generation, despite extensive study in math. In this paper, we propose S*, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S* extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. We evaluate across 12 Large Language Models and Large Reasoning Model and show: (1) S* consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) S* enables non-reasoning models to surpass reasoning models - GPT-4o-mini with S* outperforms o1-preview by 3.7% on LiveCodeBench; (3) S* further boosts state-of-the-art reasoning models - DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%. Code will be available under https://github.com/NovaSky-AI/SkyThought.