 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Apr 27, 2026Unlike chatbots, physical AI must act while the world keeps evolving. Therefore, the inter-chunk pause of synchronous executors are fatal for dynamic tasks regardless of how fast the inference is. Asynchronous execution -- thinking while acting -- is therefore a structural requirement, and real-time chunking (RTC) makes it viable by recasting chunk transitions as inpainting: freezing committed actions and consistently generating the remainder. However, RTC with flow-matching policy is structurally suboptimal: its inpainting comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning, heuristic guidance, and extra computation that inflates the latency. In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost. We propose DiscreteRTC, which replaces external corrections with native unmasking, and show on dynamic simulated benchmarks and real-world dynamic manipulation tasks that it achieves higher success rates than continuous RTC and other baselines. In summary, DiscreteRTC is simpler to implement with 0 lines of code for async inpainting, faster at inference with only 0.7x computation compared with generating actions from scratch, and better at execution with 50% higher success rate in real-world dynamic pick task compared with flow-matching-based RTC. More visualizations are on https://outsider86.github.io/DiscreteRTCSite/.
SAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving
Apr 21, 2026KV-cache memory is a major bottleneck in real-world LLM serving, where systems must simultaneously support latency-sensitive small-batch requests and high-throughput concurrent workloads. Although many KV-cache compression methods improve offline accuracy or compression ratio, they often violate practical serving constraints such as paged memory layouts, regular memory access, and fused attention execution, limiting their effectiveness in deployment. In this work, we identify the minimal set of 4-bit KV-cache quantization methods that remain viable under these constraints. Our central finding is that a simple design--token-wise INT4 quantization with block-diagonal Hadamard rotation--consistently achieves the best accuracy-efficiency trade-off. Across multiple models and benchmarks, this approach recovers nearly all of the accuracy lost by naive INT4, while more complex methods such as vector quantization and Hessian-aware quantization provide only marginal additional gains once serving compatibility is taken into account. To make this practical, we implement a fused rotation-quantization kernel that integrates directly into paged KV-cache layouts and introduces zero measurable end-to-end overhead, matching plain INT4 throughput across concurrency levels. Our results show that effective KV-cache compression is fundamentally a systems co-design problem: under real serving constraints, lightweight block-diagonal Hadamard rotation is a viable method that delivers near-lossless accuracy without sacrificing serving efficiency.
Rethinking Image-to-3D Generation with Sparse Queries: Efficiency, Capacity, and Input-View Bias
Apr 15, 2026We present SparseGen, a novel framework for efficient image-to-3D generation, which exhibits low input-view bias while being significantly faster. Unlike traditional approaches that rely on dense volumetric grids, triplanes, or pixel-aligned primitives, we model scenes with a compact sparse set of learned 3D anchor queries and a learned expansion operator that decodes each transformed query into a small local set of 3D Gaussian primitives. Trained under a rectified-flow reconstruction objective without 3D supervision, our model learns to allocate representation capacity where geometry and appearance matter, achieving significant reductions in memory and inference time while preserving multi-view fidelity. We introduce quantitative measures of input-view bias and utilization to show that sparse queries reduce overfitting to conditioning views while being representationally efficient. Our results argue that sparse set-latent expansion is a principled, practical alternative for efficient 3D generative modeling.
LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models
Apr 13, 2026Block-wise diffusion language models (DLMs) generate multiple tokens in any order, offering a promising alternative to the autoregressive decoding pipeline. However, they still remain bottlenecked by memory-bound attention in long-context scenarios. Naive sparse attention fails on DLMs due to a KV Inflation problem, where different queries select different prefix positions, making the union of accessed KV pages large. To address this, we observe that between consecutive denoising steps, only a small fraction of active tokens exhibit significant hidden-state changes, while the majority of stable tokens remain nearly constant. Based on this insight, we propose LOSA (Locality-aware Sparse Attention), which reuses cached prefix-attention results for stable tokens and applies sparse attention only to active tokens. This substantially shrinks the number of KV indices that must be loaded, yielding both higher speedup and higher accuracy. Across multiple block-wise DLMs and benchmarks, LOSA preserves near-dense accuracy while significantly improving efficiency, achieving up to +9 points in average accuracy at aggressive sparsity levels while maintaining 1.54x lower attention density. It also achieves up to 4.14x attention speedup on RTX A6000 GPUs, demonstrating the effectiveness of the proposed method.
Introspective Diffusion Language Models
Apr 13, 2026Diffusion language models promise parallel generation, yet still lag behind autoregressive (AR) models in quality. We stem this gap to a failure of introspective consistency: AR models agree with their own generations, while DLMs often do not. We define the introspective acceptance rate, which measures whether a model accepts its previously generated tokens. This reveals why AR training has a structural advantage: causal masking and logit shifting implicitly enforce introspective consistency. Motivated by this observation, we introduce Introspective Diffusion Language Model (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training. I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass. From a systems standpoint, we build I-DLM inference engine on AR-inherited optimizations and further customize it with a stationary-batch scheduler. To the best of our knowledge, I-DLM is the first DLM to match the quality of its same-scale AR counterpart while outperforming prior DLMs in both model quality and practical serving efficiency across 15 benchmarks. It reaches 69.6 on AIME-24 and 45.7 on LiveCodeBench-v6, exceeding LLaDA-2.1-mini (16B) by more than 26 and 15 points, respectively. Beyond quality, I-DLM is designed for the growing demand of large-concurrency serving, delivering about 3x higher throughput than prior state-of-the-art DLMs.
Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution
Apr 09, 2026We show that verifier-free evolution is bottlenecked by both diversity and efficiency: without external correction, repeated evolution accelerates collapse toward narrow modes, while the uniform use of a high-cost model wastes compute and quickly becomes economically impractical. We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference. Our approach is guided by a simple principle: allocate model capability where it has the highest marginal utility. Stronger models are reserved for high-impact stages, while cheaper models handle the other stages at much lower costs. This principle addresses diversity and cost-efficiency jointly while remaining lightweight. Squeeze Evolve naturally supports open-source, closed-source, and mixed-model deployments. Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision, Squeeze Evolve consistently improves the cost-capability frontier over single-model evolution and achieves new state-of-the-art results on several tasks. Empirically, Squeeze Evolve reduces API cost by up to $\sim$3$\times$ and increases fixed-budget serving throughput by up to $\sim$10$\times$. Moreover, on discovery tasks, Squeeze Evolve is the first verifier-free evolutionary method to match, and in some cases exceed, the performance of verifier-based evolutionary methods.
When RL Meets Adaptive Speculative Training: A Unified Training-Serving System
Feb 06, 2026Speculative decoding can significantly accelerate LLM serving, yet most deployments today disentangle speculator training from serving, treating speculator training as a standalone offline modeling problem. We show that this decoupled formulation introduces substantial deployment and adaptation lag: (1) high time-to-serve, since a speculator must be trained offline for a considerable period before deployment; (2) delayed utility feedback, since the true end-to-end decoding speedup is only known after training and cannot be inferred reliably from acceptance rate alone due to model-architecture and system-level overheads; and (3) domain-drift degradation, as the target model is repurposed to new domains and the speculator becomes stale and less effective. To address these issues, we present Aurora, a unified training-serving system that closes the loop by continuously learning a speculator directly from live inference traces. Aurora reframes online speculator learning as an asynchronous reinforcement-learning problem: accepted tokens provide positive feedback, while rejected speculator proposals provide implicit negative feedback that we exploit to improve sample efficiency. Our design integrates an SGLang-based inference server with an asynchronous training server, enabling hot-swapped speculator updates without service interruption. Crucially, Aurora supports day-0 deployment: a speculator can be served immediately and rapidly adapted to live traffic, improving system performance while providing immediate utility feedback. Across experiments, Aurora achieves a 1.5x day-0 speedup on recently released frontier models (e.g., MiniMax M2.1 229B and Qwen3-Coder-Next 80B). Aurora also adapts effectively to distribution shifts in user traffic, delivering an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Feb 03, 2026Despite rapid progress in autoregressive video diffusion, an emerging system algorithm bottleneck limits both deployability and generation capability: KV cache memory. In autoregressive video generation models, the KV cache grows with generation history and quickly dominates GPU memory, often exceeding 30 GB, preventing deployment on widely available hardware. More critically, constrained KV cache budgets restrict the effective working memory, directly degrading long horizon consistency in identity, layout, and motion. To address this challenge, we present Quant VideoGen (QVG), a training free KV cache quantization framework for autoregressive video diffusion models. QVG leverages video spatiotemporal redundancy through Semantic Aware Smoothing, producing low magnitude, quantization friendly residuals. It further introduces Progressive Residual Quantization, a coarse to fine multi stage scheme that reduces quantization error while enabling a smooth quality memory trade off. Across LongCat Video, HY WorldPlay, and Self Forcing benchmarks, QVG establishes a new Pareto frontier between quality and memory efficiency, reducing KV cache memory by up to 7.0 times with less than 4% end to end latency overhead while consistently outperforming existing baselines in generation quality.
Residual Context Diffusion Language Models
Jan 30, 2026Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to purely autoregressive language models because they can decode multiple tokens in parallel. However, state-of-the-art block-wise dLLMs rely on a "remasking" mechanism that decodes only the most confident tokens and discards the rest, effectively wasting computation. We demonstrate that recycling computation from the discarded tokens is beneficial, as these tokens retain contextual information useful for subsequent decoding iterations. In light of this, we propose Residual Context Diffusion (RCD), a module that converts these discarded token representations into contextual residuals and injects them back for the next denoising step. RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation. We validate our method on both long CoT reasoning (SDAR) and short CoT instruction following (LLaDA) models. We demonstrate that a standard dLLM can be efficiently converted to the RCD paradigm with merely ~1 billion tokens. RCD consistently improves frontier dLLMs by 5-10 points in accuracy with minimal extra computation overhead across a wide range of benchmarks. Notably, on the most challenging AIME tasks, RCD nearly doubles baseline accuracy and attains up to 4-5x fewer denoising steps at equivalent accuracy levels.
OXE-AugE: A Large-Scale Robot Augmentation of OXE for Scaling Cross-Embodiment Policy Learning
Dec 15, 2025

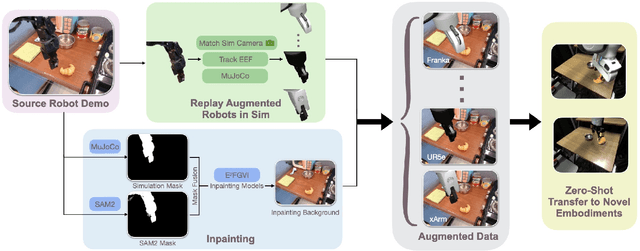
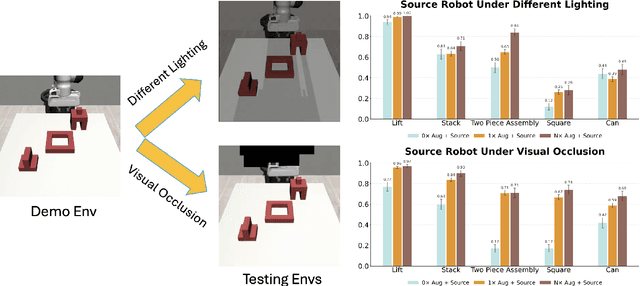
Large and diverse datasets are needed for training generalist robot policies that have potential to control a variety of robot embodiments -- robot arm and gripper combinations -- across diverse tasks and environments. As re-collecting demonstrations and retraining for each new hardware platform are prohibitively costly, we show that existing robot data can be augmented for transfer and generalization. The Open X-Embodiment (OXE) dataset, which aggregates demonstrations from over 60 robot datasets, has been widely used as the foundation for training generalist policies. However, it is highly imbalanced: the top four robot types account for over 85\% of its real data, which risks overfitting to robot-scene combinations. We present AugE-Toolkit, a scalable robot augmentation pipeline, and OXE-AugE, a high-quality open-source dataset that augments OXE with 9 different robot embodiments. OXE-AugE provides over 4.4 million trajectories, more than triple the size of the original OXE. We conduct a systematic study of how scaling robot augmentation impacts cross-embodiment learning. Results suggest that augmenting datasets with diverse arms and grippers improves policy performance not only on the augmented robots, but also on unseen robots and even the original robots under distribution shifts. In physical experiments, we demonstrate that state-of-the-art generalist policies such as OpenVLA and $π_0$ benefit from fine-tuning on OXE-AugE, improving success rates by 24-45% on previously unseen robot-gripper combinations across four real-world manipulation tasks. Project website: https://OXE-AugE.github.io/.