 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarGen: Automotive Radar Point Cloud Generation from Cameras
Dec 19, 2025



We present RadarGen, a diffusion model for synthesizing realistic automotive radar point clouds from multi-view camera imagery. RadarGen adapts efficient image-latent diffusion to the radar domain by representing radar measurements in bird's-eye-view form that encodes spatial structure together with radar cross section (RCS) and Doppler attributes. A lightweight recovery step reconstructs point clouds from the generated maps. To better align generation with the visual scene, RadarGen incorporates BEV-aligned depth, semantic, and motion cues extracted from pretrained foundation models, which guide the stochastic generation process toward physically plausible radar patterns. Conditioning on images makes the approach broadly compatible, in principle, with existing visual datasets and simulation frameworks, offering a scalable direction for multimodal generative simulation. Evaluations on large-scale driving data show that RadarGen captures characteristic radar measurement distributions and reduces the gap to perception models trained on real data, marking a step toward unified generative simulation across sensing modalities.
Gaussian See, Gaussian Do: Semantic 3D Motion Transfer from Multiview Video
Nov 18, 2025We present Gaussian See, Gaussian Do, a novel approach for semantic 3D motion transfer from multiview video. Our method enables rig-free, cross-category motion transfer between objects with semantically meaningful correspondence. Building on implicit motion transfer techniques, we extract motion embeddings from source videos via condition inversion, apply them to rendered frames of static target shapes, and use the resulting videos to supervise dynamic 3D Gaussian Splatting reconstruction. Our approach introduces an anchor-based view-aware motion embedding mechanism, ensuring cross-view consistency and accelerating convergence, along with a robust 4D reconstruction pipeline that consolidates noisy supervision videos. We establish the first benchmark for semantic 3D motion transfer and demonstrate superior motion fidelity and structural consistency compared to adapted baselines. Code and data for this paper available at https://gsgd-motiontransfer.github.io/
InstructMix2Mix: Consistent Sparse-View Editing Through Multi-View Model Personalization
Nov 18, 2025We address the task of multi-view image editing from sparse input views, where the inputs can be seen as a mix of images capturing the scene from different viewpoints. The goal is to modify the scene according to a textual instruction while preserving consistency across all views. Existing methods, based on per-scene neural fields or temporal attention mechanisms, struggle in this setting, often producing artifacts and incoherent edits. We propose InstructMix2Mix (I-Mix2Mix), a framework that distills the editing capabilities of a 2D diffusion model into a pretrained multi-view diffusion model, leveraging its data-driven 3D prior for cross-view consistency. A key contribution is replacing the conventional neural field consolidator in Score Distillation Sampling (SDS) with a multi-view diffusion student, which requires novel adaptations: incremental student updates across timesteps, a specialized teacher noise scheduler to prevent degeneration, and an attention modification that enhances cross-view coherence without additional cost. Experiments demonstrate that I-Mix2Mix significantly improves multi-view consistency while maintaining high per-frame edit quality.
Appreciate the View: A Task-Aware Evaluation Framework for Novel View Synthesis
Nov 16, 2025



The goal of Novel View Synthesis (NVS) is to generate realistic images of a given content from unseen viewpoints. But how can we trust that a generated image truly reflects the intended transformation? Evaluating its reliability remains a major challenge. While recent generative models, particularly diffusion-based approaches, have significantly improved NVS quality, existing evaluation metrics struggle to assess whether a generated image is both realistic and faithful to the source view and intended viewpoint transformation. Standard metrics, such as pixel-wise similarity and distribution-based measures, often mis-rank incorrect results as they fail to capture the nuanced relationship between the source image, viewpoint change, and generated output. We propose a task-aware evaluation framework that leverages features from a strong NVS foundation model, Zero123, combined with a lightweight tuning step to enhance discrimination. Using these features, we introduce two complementary evaluation metrics: a reference-based score, $D_{\text{PRISM}}$, and a reference-free score, $\text{MMD}_{\text{PRISM}}$. Both reliably identify incorrect generations and rank models in agreement with human preference studies, addressing a fundamental gap in NVS evaluation. Our framework provides a principled and practical approach to assessing synthesis quality, paving the way for more reliable progress in novel view synthesis. To further support this goal, we apply our reference-free metric to six NVS methods across three benchmarks: Toys4K, Google Scanned Objects (GSO), and OmniObject3D, where $\text{MMD}_{\text{PRISM}}$ produces a clear and stable ranking, with lower scores consistently indicating stronger models.
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
Nov 09, 2025



Diffusion-based video generation can create realistic videos, yet existing image- and text-based conditioning fails to offer precise motion control. Prior methods for motion-conditioned synthesis typically require model-specific fine-tuning, which is computationally expensive and restrictive. We introduce Time-to-Move (TTM), a training-free, plug-and-play framework for motion- and appearance-controlled video generation with image-to-video (I2V) diffusion models. Our key insight is to use crude reference animations obtained through user-friendly manipulations such as cut-and-drag or depth-based reprojection. Motivated by SDEdit's use of coarse layout cues for image editing, we treat the crude animations as coarse motion cues and adapt the mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. This lightweight modification of the sampling process incurs no additional training or runtime cost and is compatible with any backbone. Extensive experiments on object and camera motion benchmarks show that TTM matches or exceeds existing training-based baselines in realism and motion control. Beyond this, TTM introduces a unique capability: precise appearance control through pixel-level conditioning, exceeding the limits of text-only prompting. Visit our project page for video examples and code: https://time-to-move.github.io/.
FRIDU: Functional Map Refinement with Guided Image Diffusion
Jun 17, 2025We propose a novel approach for refining a given correspondence map between two shapes. A correspondence map represented as a functional map, namely a change of basis matrix, can be additionally treated as a 2D image. With this perspective, we train an image diffusion model directly in the space of functional maps, enabling it to generate accurate maps conditioned on an inaccurate initial map. The training is done purely in the functional space, and thus is highly efficient. At inference time, we use the pointwise map corresponding to the current functional map as guidance during the diffusion process. The guidance can additionally encourage different functional map objectives, such as orthogonality and commutativity with the Laplace-Beltrami operator. We show that our approach is competitive with state-of-the-art methods of map refinement and that guided diffusion models provide a promising pathway to functional map processing.
GAS-NeRF: Geometry-Aware Stylization of Dynamic Radiance Fields
Mar 11, 2025Current 3D stylization techniques primarily focus on static scenes, while our world is inherently dynamic, filled with moving objects and changing environments. Existing style transfer methods primarily target appearance -- such as color and texture transformation -- but often neglect the geometric characteristics of the style image, which are crucial for achieving a complete and coherent stylization effect. To overcome these shortcomings, we propose GAS-NeRF, a novel approach for joint appearance and geometry stylization in dynamic Radiance Fields. Our method leverages depth maps to extract and transfer geometric details into the radiance field, followed by appearance transfer. Experimental results on synthetic and real-world datasets demonstrate that our approach significantly enhances the stylization quality while maintaining temporal coherence in dynamic scenes.
ZDySS -- Zero-Shot Dynamic Scene Stylization using Gaussian Splatting
Jan 07, 2025



Stylizing a dynamic scene based on an exemplar image is critical for various real-world applications, including gaming, filmmaking, and augmented and virtual reality. However, achieving consistent stylization across both spatial and temporal dimensions remains a significant challenge. Most existing methods are designed for static scenes and often require an optimization process for each style image, limiting their adaptability. We introduce ZDySS, a zero-shot stylization framework for dynamic scenes, allowing our model to generalize to previously unseen style images at inference. Our approach employs Gaussian splatting for scene representation, linking each Gaussian to a learned feature vector that renders a feature map for any given view and timestamp. By applying style transfer on the learned feature vectors instead of the rendered feature map, we enhance spatio-temporal consistency across frames. Our method demonstrates superior performance and coherence over state-of-the-art baselines in tests on real-world dynamic scenes, making it a robust solution for practical applications.
ReHub: Linear Complexity Graph Transformers with Adaptive Hub-Spoke Reassignment
Dec 02, 2024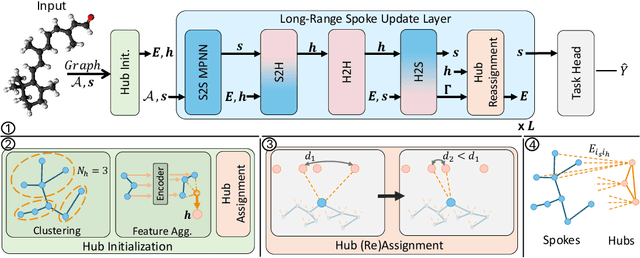
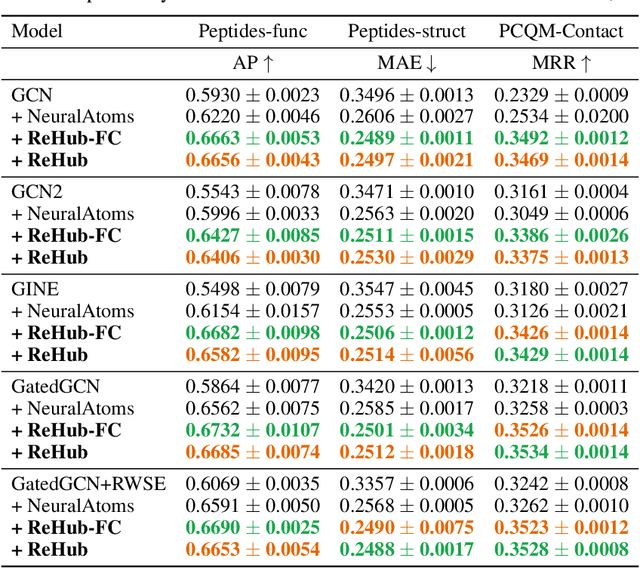
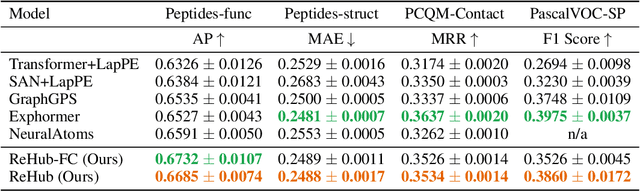
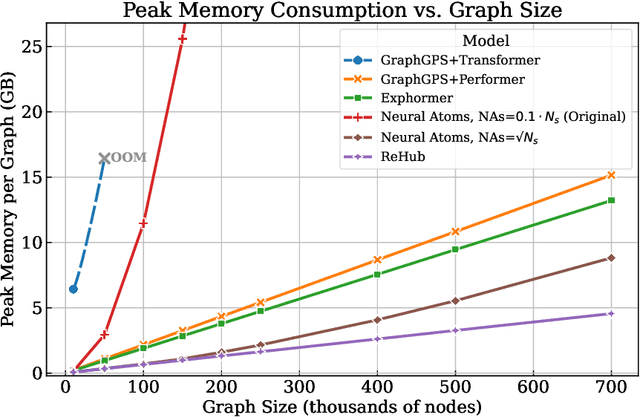
We present ReHub, a novel graph transformer architecture that achieves linear complexity through an efficient reassignment technique between nodes and virtual nodes. Graph transformers have become increasingly important in graph learning for their ability to utilize long-range node communication explicitly, addressing limitations such as oversmoothing and oversquashing found in message-passing graph networks. However, their dense attention mechanism scales quadratically with the number of nodes, limiting their applicability to large-scale graphs. ReHub draws inspiration from the airline industry's hub-and-spoke model, where flights are assigned to optimize operational efficiency. In our approach, graph nodes (spokes) are dynamically reassigned to a fixed number of virtual nodes (hubs) at each model layer. Recent work, Neural Atoms (Li et al., 2024), has demonstrated impressive and consistent improvements over GNN baselines by utilizing such virtual nodes; their findings suggest that the number of hubs strongly influences performance. However, increasing the number of hubs typically raises complexity, requiring a trade-off to maintain linear complexity. Our key insight is that each node only needs to interact with a small subset of hubs to achieve linear complexity, even when the total number of hubs is large. To leverage all hubs without incurring additional computational costs, we propose a simple yet effective adaptive reassignment technique based on hub-hub similarity scores, eliminating the need for expensive node-hub computations. Our experiments on LRGB indicate a consistent improvement in results over the base method, Neural Atoms, while maintaining a linear complexity. Remarkably, our sparse model achieves performance on par with its non-sparse counterpart. Furthermore, ReHub outperforms competitive baselines and consistently ranks among top performers across various benchmarks.
A Lesson in Splats: Teacher-Guided Diffusion for 3D Gaussian Splats Generation with 2D Supervision
Dec 01, 2024We introduce a diffusion model for Gaussian Splats, SplatDiffusion, to enable generation of three-dimensional structures from single images, addressing the ill-posed nature of lifting 2D inputs to 3D. Existing methods rely on deterministic, feed-forward predictions, which limit their ability to handle the inherent ambiguity of 3D inference from 2D data. Diffusion models have recently shown promise as powerful generative models for 3D data, including Gaussian splats; however, standard diffusion frameworks typically require the target signal and denoised signal to be in the same modality, which is challenging given the scarcity of 3D data. To overcome this, we propose a novel training strategy that decouples the denoised modality from the supervision modality. By using a deterministic model as a noisy teacher to create the noised signal and transitioning from single-step to multi-step denoising supervised by an image rendering loss, our approach significantly enhances performance compared to the deterministic teacher. Additionally, our method is flexible, as it can learn from various 3D Gaussian Splat (3DGS) teachers with minimal adaptation; we demonstrate this by surpassing the performance of two different deterministic models as teachers, highlighting the potential generalizability of our framework. Our approach further incorporates a guidance mechanism to aggregate information from multiple views, enhancing reconstruction quality when more than one view is available. Experimental results on object-level and scene-level datasets demonstrate the effectiveness of our framework.