 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NeRFect Match: Exploring NeRF Features for Visual Localization
Mar 14, 2024



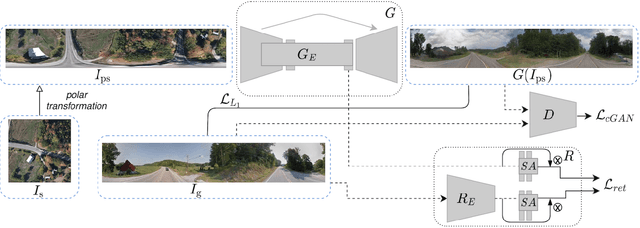
In this work, we propose the use of Neural Radiance Fields (NeRF) as a scene representation for visual localization. Recently, NeRF has been employed to enhance pose regression and scene coordinate regression models by augmenting the training database, providing auxiliary supervision through rendered images, or serving as an iterative refinement module. We extend its recognized advantages -- its ability to provide a compact scene representation with realistic appearances and accurate geometry -- by exploring the potential of NeRF's internal features in establishing precise 2D-3D matches for localization. To this end, we conduct a comprehensive examination of NeRF's implicit knowledge, acquired through view synthesis, for matching under various conditions. This includes exploring different matching network architectures, extracting encoder features at multiple layers, and varying training configurations. Significantly, we introduce NeRFMatch, an advanced 2D-3D matching function that capitalizes on the internal knowledge of NeRF learned via view synthesis. Our evaluation of NeRFMatch on standard localization benchmarks, within a structure-based pipeline, sets a new state-of-the-art for localization performance on Cambridge Landmarks.
Data-Driven but Privacy-Conscious: Pedestrian Dataset De-identification via Full-Body Person Synthesis
Jun 22, 2023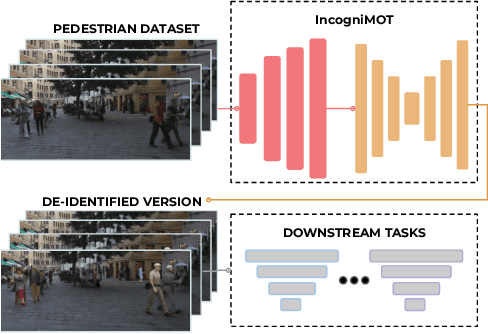

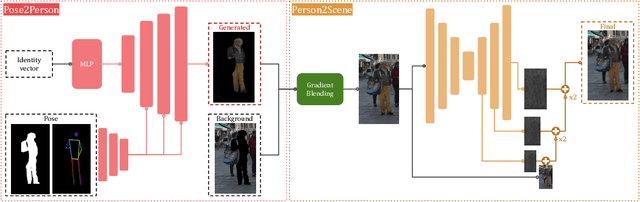

The advent of data-driven technology solutions is accompanied by an increasing concern with data privacy. This is of particular importance for human-centered image recognition tasks, such as pedestrian detection, re-identification, and tracking. To highlight the importance of privacy issues and motivate future research, we motivate and introduce the Pedestrian Dataset De-Identification (PDI) task. PDI evaluates the degree of de-identification and downstream task training performance for a given de-identification method. As a first baseline, we propose IncogniMOT, a two-stage full-body de-identification pipeline based on image synthesis via generative adversarial networks. The first stage replaces target pedestrians with synthetic identities. To improve downstream task performance, we then apply stage two, which blends and adapts the synthetic image parts into the data. To demonstrate the effectiveness of IncogniMOT, we generate a fully de-identified version of the MOT17 pedestrian tracking dataset and analyze its application as training data for pedestrian re-identification, detection, and tracking models. Furthermore, we show how our data is able to narrow the synthetic-to-real performance gap in a privacy-conscious manner.
The 2021 Image Similarity Dataset and Challenge
Jul 01, 2021

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of "distractor" images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Coming Down to Earth: Satellite-to-Street View Synthesis for Geo-Localization
Mar 11, 2021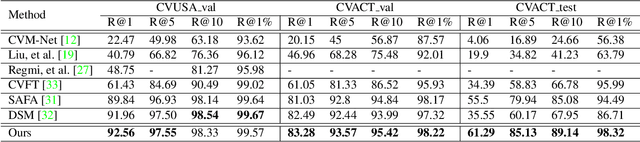


The goal of cross-view image based geo-localization is to determine the location of a given street view image by matching it against a collection of geo-tagged satellite images. This task is notoriously challenging due to the drastic viewpoint and appearance differences between the two domains. We show that we can address this discrepancy explicitly by learning to synthesize realistic street views from satellite inputs. Following this observation, we propose a novel multi-task architecture in which image synthesis and retrieval are considered jointly. The rationale behind this is that we can bias our network to learn latent feature representations that are useful for retrieval if we utilize them to generate images across the two input domains. To the best of our knowledge, ours is the first approach that creates realistic street views from satellite images and localizes the corresponding query street-view simultaneously in an end-to-end manner. In our experiments, we obtain state-of-the-art performance on the CVUSA and CVACT benchmarks. Finally, we show compelling qualitative results for satellite-to-street view synthesis.
4D Panoptic LiDAR Segmentation
Feb 24, 2021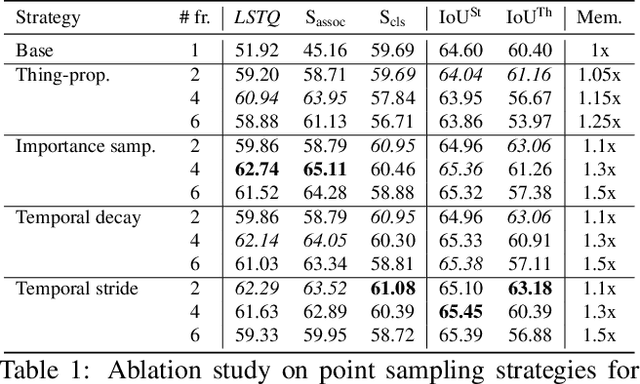
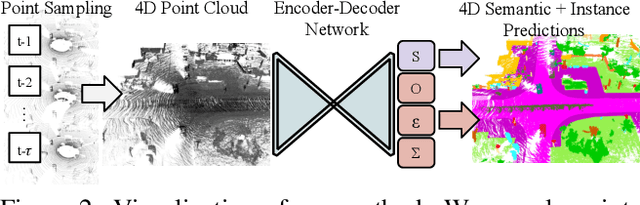
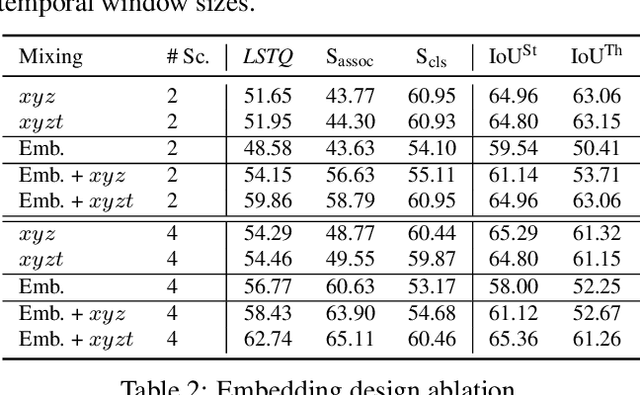
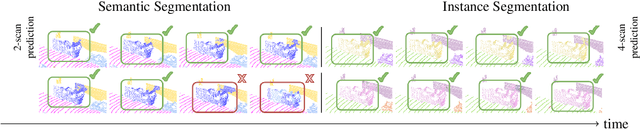
Temporal semantic scene understanding is critical for self-driving cars or robots operating in dynamic environments. In this paper, we propose 4D panoptic LiDAR segmentation to assign a semantic class and a temporally-consistent instance ID to a sequence of 3D points. To this end, we present an approach and a point-centric evaluation metric. Our approach determines a semantic class for every point while modeling object instances as probability distributions in the 4D spatio-temporal domain. We process multiple point clouds in parallel and resolve point-to-instance associations, effectively alleviating the need for explicit temporal data association. Inspired by recent advances in benchmarking of multi-object tracking, we propose to adopt a new evaluation metric that separates the semantic and point-to-instance association aspects of the task. With this work, we aim at paving the road for future developments of temporal LiDAR panoptic perception.
Focus on defocus: bridging the synthetic to real domain gap for depth estimation
May 19, 2020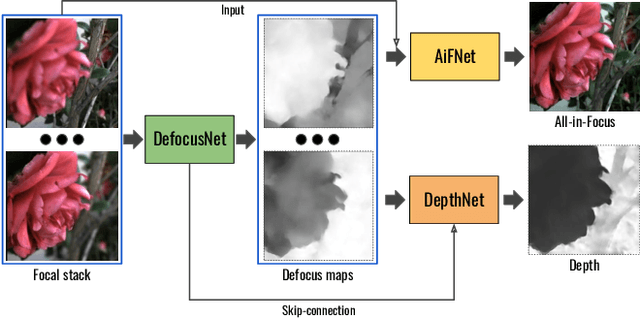

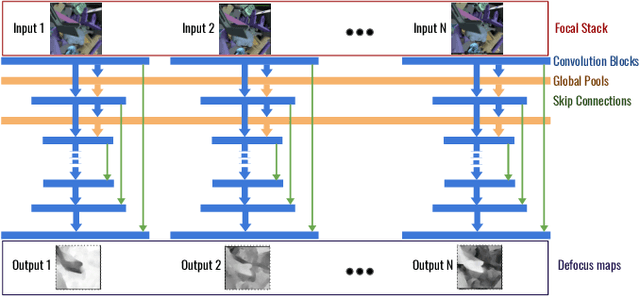
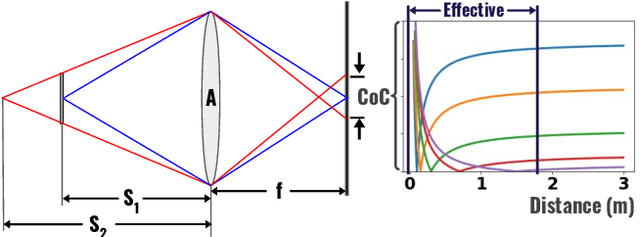
Data-driven depth estimation methods struggle with the generalization outside their training scenes due to the immense variability of the real-world scenes. This problem can be partially addressed by utilising synthetically generated images, but closing the synthetic-real domain gap is far from trivial. In this paper, we tackle this issue by using domain invariant defocus blur as direct supervision. We leverage defocus cues by using a permutation invariant convolutional neural network that encourages the network to learn from the differences between images with a different point of focus. Our proposed network uses the defocus map as an intermediate supervisory signal. We are able to train our model completely on synthetic data and directly apply it to a wide range of real-world images. We evaluate our model on synthetic and real datasets, showing compelling generalization results and state-of-the-art depth prediction.
CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks
May 19, 2020
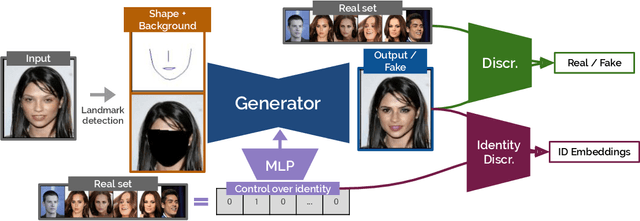
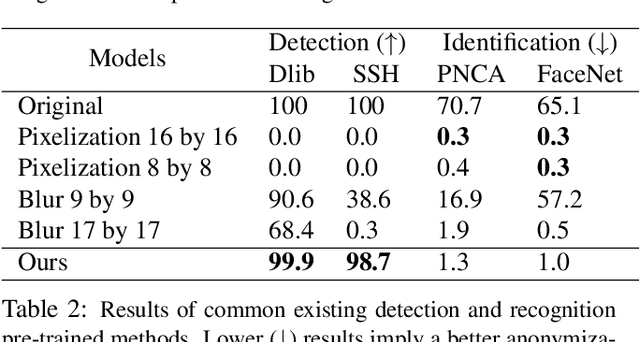

The unprecedented increase in the usage of computer vision technology in society goes hand in hand with an increased concern in data privacy. In many real-world scenarios like people tracking or action recognition, it is important to be able to process the data while taking careful consideration in protecting people's identity. We propose and develop CIAGAN, a model for image and video anonymization based on conditional generative adversarial networks. Our model is able to remove the identifying characteristics of faces and bodies while producing high-quality images and videos that can be used for any computer vision task, such as detection or tracking. Unlike previous methods, we have full control over the de-identification (anonymization) procedure, ensuring both anonymization as well as diversity. We compare our method to several baselines and achieve state-of-the-art results.
LIME: Live Intrinsic Material Estimation
May 04, 2018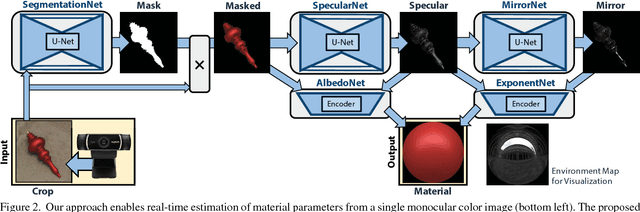
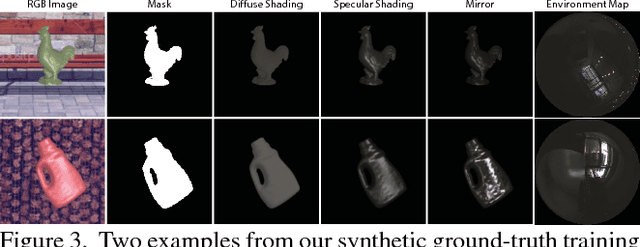


We present the first end to end approach for real time material estimation for general object shapes with uniform material that only requires a single color image as input. In addition to Lambertian surface properties, our approach fully automatically computes the specular albedo, material shininess, and a foreground segmentation. We tackle this challenging and ill posed inverse rendering problem using recent advances in image to image translation techniques based on deep convolutional encoder decoder architectures. The underlying core representations of our approach are specular shading, diffuse shading and mirror images, which allow to learn the effective and accurate separation of diffuse and specular albedo. In addition, we propose a novel highly efficient perceptual rendering loss that mimics real world image formation and obtains intermediate results even during run time. The estimation of material parameters at real time frame rates enables exciting mixed reality applications, such as seamless illumination consistent integration of virtual objects into real world scenes, and virtual material cloning. We demonstrate our approach in a live setup, compare it to the state of the art, and demonstrate its effectiveness through quantitative and qualitative evaluation.
Deep Appearance Maps
Apr 03, 2018
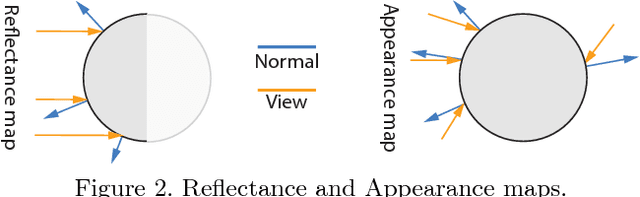

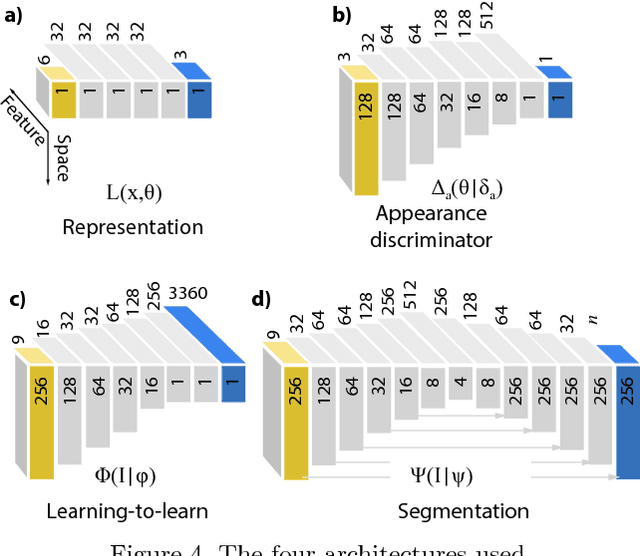
We propose a deep representation of appearance, i. e. the relation of color, surface orientation, viewer position, material and illumination. Previous approaches have used deep learning to extract classic appearance representations relating to reflectance model parameters (e. g. Phong) or illumination (e. g. HDR environment maps). We suggest to directly represent appearance itself as a network we call a deep appearance map (DAM). This is a 4D generalization over 2D reflectance maps, which held the view direction fixed. First, we show how a DAM can be learned from images or video frames and later be used to synthesize appearance, given new surface orientations and viewer positions. Second, we demonstrate how another network can be used to map from an image or video frames to a DAM network to reproduce this appearance, without using a lengthy optimization such as stochastic gradient descent (learning-to-learn). Finally, we generalize this to an appearance estimation-and-segmentation task, where we map from an image showing multiple materials to multiple networks reproducing their appearance, as well as per-pixel segmentation.