 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You See What I Am Pointing At? Gesture-Based Egocentric Video Question Answering
Mar 13, 2026Understanding and answering questions based on a user's pointing gesture is essential for next-generation egocentric AI assistants. However, current Multimodal Large Language Models (MLLMs) struggle with such tasks due to the lack of gesture-rich data and their limited ability to infer fine-grained pointing intent from egocentric video. To address this, we introduce EgoPointVQA, a dataset and benchmark for gesture-grounded egocentric question answering, comprising 4000 synthetic and 400 real-world videos across multiple deictic reasoning tasks. Built upon it, we further propose Hand Intent Tokens (HINT), which encodes tokens derived from 3D hand keypoints using an off-the-shelf reconstruction model and interleaves them with the model input to provide explicit spatial and temporal context for interpreting pointing intent. We show that our model outperforms others in different backbones and model sizes. In particular, HINT-14B achieves 68.1% accuracy, on average over 6 tasks, surpassing the state-of-the-art, InternVL3-14B, by 6.6%. To further facilitate the open research, we will release the code, model, and dataset. Project page: https://yuuraa.github.io/papers/choi2026egovqa
Test-Time Scaling with Diffusion Language Models via Reward-Guided Stitching
Feb 26, 2026Reasoning with large language models often benefits from generating multiple chains-of-thought, but existing aggregation strategies are typically trajectory-level (e.g., selecting the best trace or voting on the final answer), discarding useful intermediate work from partial or "nearly correct" attempts. We propose Stitching Noisy Diffusion Thoughts, a self-consistency framework that turns cheap diffusion-sampled reasoning into a reusable pool of step-level candidates. Given a problem, we (i) sample many diverse, low-cost reasoning trajectories using a masked diffusion language model, (ii) score every intermediate step with an off-the-shelf process reward model (PRM), and (iii) stitch these highest-quality steps across trajectories into a composite rationale. This rationale then conditions an autoregressive (AR) model (solver) to recompute only the final answer. This modular pipeline separates exploration (diffusion) from evaluation and solution synthesis, avoiding monolithic unified hybrids while preserving broad search. Across math reasoning benchmarks, we find that step-level recombination is most beneficial on harder problems, and ablations highlight the importance of the final AR solver in converting stitched but imperfect rationales into accurate answers. Using low-confidence diffusion sampling with parallel, independent rollouts, our training-free framework improves average accuracy by up to 23.8% across six math and coding tasks. At the same time, it achieves up to a 1.8x latency reduction relative to both traditional diffusion models (e.g., Dream, LLaDA) and unified architectures (e.g., TiDAR). Code is available at https://github.com/roymiles/diffusion-stitching.
A Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
SATGround: A Spatially-Aware Approach for Visual Grounding in Remote Sensing
Dec 09, 2025Vision-language models (VLMs) are emerging as powerful generalist tools for remote sensing, capable of integrating information across diverse tasks and enabling flexible, instruction-based interactions via a chat interface. In this work, we enhance VLM-based visual grounding in satellite imagery by proposing a novel structured localization mechanism. Our approach involves finetuning a pretrained VLM on a diverse set of instruction-following tasks, while interfacing a dedicated grounding module through specialized control tokens for localization. This method facilitates joint reasoning over both language and spatial information, significantly enhancing the model's ability to precisely localize objects in complex satellite scenes. We evaluate our framework on several remote sensing benchmarks, consistently improving the state-of-the-art, including a 24.8% relative improvement over previous methods on visual grounding. Our results highlight the benefits of integrating structured spatial reasoning into VLMs, paving the way for more reliable real-world satellite data analysis.
RetouchLLM: Training-free White-box Image Retouching
Oct 09, 2025Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
"Principal Components" Enable A New Language of Images
Mar 11, 2025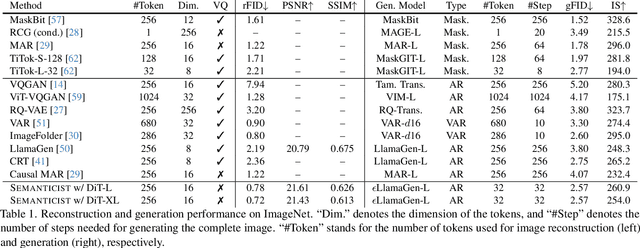
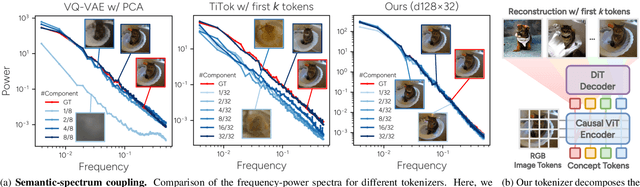
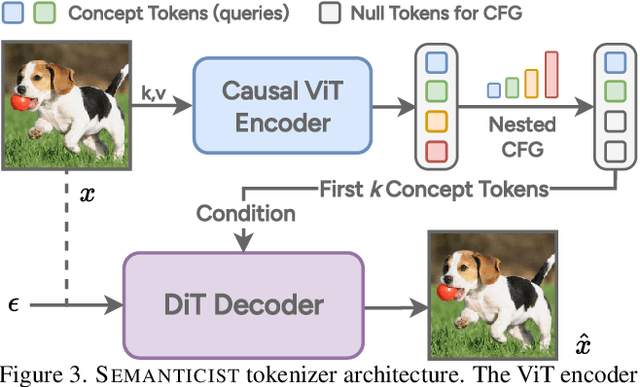
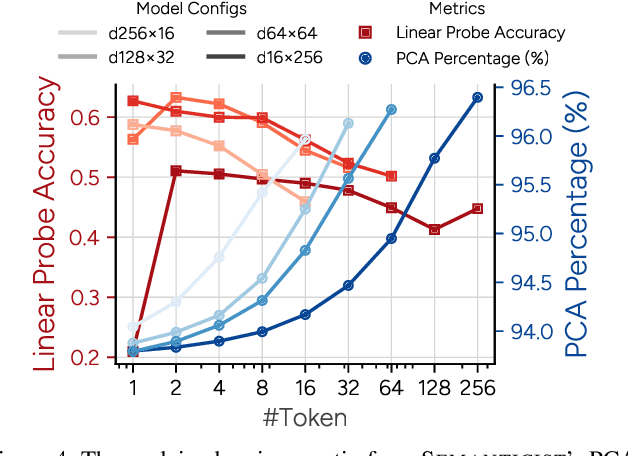
We introduce a novel visual tokenization framework that embeds a provable PCA-like structure into the latent token space. While existing visual tokenizers primarily optimize for reconstruction fidelity, they often neglect the structural properties of the latent space -- a critical factor for both interpretability and downstream tasks. Our method generates a 1D causal token sequence for images, where each successive token contributes non-overlapping information with mathematically guaranteed decreasing explained variance, analogous to principal component analysis. This structural constraint ensures the tokenizer extracts the most salient visual features first, with each subsequent token adding diminishing yet complementary information. Additionally, we identified and resolved a semantic-spectrum coupling effect that causes the unwanted entanglement of high-level semantic content and low-level spectral details in the tokens by leveraging a diffusion decoder. Experiments demonstrate that our approach achieves state-of-the-art reconstruction performance and enables better interpretability to align with the human vision system. Moreover, auto-regressive models trained on our token sequences achieve performance comparable to current state-of-the-art methods while requiring fewer tokens for training and inference.
From Attention to Activation: Unravelling the Enigmas of Large Language Models
Oct 22, 2024We study two strange phenomena in auto-regressive Transformers: (1) the dominance of the first token in attention heads; (2) the occurrence of large outlier activations in the hidden states. We find that popular large language models, such as Llama attend maximally to the first token in 98% of attention heads, a behaviour we attribute to the softmax function. To mitigate this issue, we propose a reformulation of softmax to softmax-1. Furthermore, we identify adaptive optimisers, e.g. Adam, as the primary contributor to the large outlier activations and introduce OrthoAdam, a novel optimiser that utilises orthogonal matrices to transform gradients, to address this issue. Finally, not only do our methods prevent these phenomena from occurring, but additionally, they enable Transformers to sustain their performance when quantised using basic algorithms, something that standard methods are unable to do. In summary, our methods reduce the attention proportion on the first token from 65% to 3.3%, the activation kurtosis in the hidden states from 1657 to 3.1, and perplexity penalty under 4-bit weight quantisation from 3565 to 0.3.
Fractal Calibration for long-tailed object detection
Oct 15, 2024



Real-world datasets follow an imbalanced distribution, which poses significant challenges in rare-category object detection. Recent studies tackle this problem by developing re-weighting and re-sampling methods, that utilise the class frequencies of the dataset. However, these techniques focus solely on the frequency statistics and ignore the distribution of the classes in image space, missing important information. In contrast to them, we propose FRActal CALibration (FRACAL): a novel post-calibration method for long-tailed object detection. FRACAL devises a logit adjustment method that utilises the fractal dimension to estimate how uniformly classes are distributed in image space. During inference, it uses the fractal dimension to inversely downweight the probabilities of uniformly spaced class predictions achieving balance in two axes: between frequent and rare categories, and between uniformly spaced and sparsely spaced classes. FRACAL is a post-processing method and it does not require any training, also it can be combined with many off-the-shelf models such as one-stage sigmoid detectors and two-stage instance segmentation models. FRACAL boosts the rare class performance by up to 8.6% and surpasses all previous methods on LVIS dataset, while showing good generalisation to other datasets such as COCO, V3Det and OpenImages. The code will be released.