 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Attention to Activation: Unravelling the Enigmas of Large Language Models
Oct 22, 2024We study two strange phenomena in auto-regressive Transformers: (1) the dominance of the first token in attention heads; (2) the occurrence of large outlier activations in the hidden states. We find that popular large language models, such as Llama attend maximally to the first token in 98% of attention heads, a behaviour we attribute to the softmax function. To mitigate this issue, we propose a reformulation of softmax to softmax-1. Furthermore, we identify adaptive optimisers, e.g. Adam, as the primary contributor to the large outlier activations and introduce OrthoAdam, a novel optimiser that utilises orthogonal matrices to transform gradients, to address this issue. Finally, not only do our methods prevent these phenomena from occurring, but additionally, they enable Transformers to sustain their performance when quantised using basic algorithms, something that standard methods are unable to do. In summary, our methods reduce the attention proportion on the first token from 65% to 3.3%, the activation kurtosis in the hidden states from 1657 to 3.1, and perplexity penalty under 4-bit weight quantisation from 3565 to 0.3.
THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models
May 08, 2024Mitigating hallucinations in large vision-language models (LVLMs) remains an open problem. Recent benchmarks do not address hallucinations in open-ended free-form responses, which we term "Type I hallucinations". Instead, they focus on hallucinations responding to very specific question formats -- typically a multiple-choice response regarding a particular object or attribute -- which we term "Type II hallucinations". Additionally, such benchmarks often require external API calls to models which are subject to change. In practice, we observe that a reduction in Type II hallucinations does not lead to a reduction in Type I hallucinations but rather that the two forms of hallucinations are often anti-correlated. To address this, we propose THRONE, a novel object-based automatic framework for quantitatively evaluating Type I hallucinations in LVLM free-form outputs. We use public language models (LMs) to identify hallucinations in LVLM responses and compute informative metrics. By evaluating a large selection of recent LVLMs using public datasets, we show that an improvement in existing metrics do not lead to a reduction in Type I hallucinations, and that established benchmarks for measuring Type I hallucinations are incomplete. Finally, we provide a simple and effective data augmentation method to reduce Type I and Type II hallucinations as a strong baseline.
Multi-Modal Classifiers for Open-Vocabulary Object Detection
Jun 08, 2023



The goal of this paper is open-vocabulary object detection (OVOD) $\unicode{x2013}$ building a model that can detect objects beyond the set of categories seen at training, thus enabling the user to specify categories of interest at inference without the need for model retraining. We adopt a standard two-stage object detector architecture, and explore three ways for specifying novel categories: via language descriptions, via image exemplars, or via a combination of the two. We make three contributions: first, we prompt a large language model (LLM) to generate informative language descriptions for object classes, and construct powerful text-based classifiers; second, we employ a visual aggregator on image exemplars that can ingest any number of images as input, forming vision-based classifiers; and third, we provide a simple method to fuse information from language descriptions and image exemplars, yielding a multi-modal classifier. When evaluating on the challenging LVIS open-vocabulary benchmark we demonstrate that: (i) our text-based classifiers outperform all previous OVOD works; (ii) our vision-based classifiers perform as well as text-based classifiers in prior work; (iii) using multi-modal classifiers perform better than either modality alone; and finally, (iv) our text-based and multi-modal classifiers yield better performance than a fully-supervised detector.
Label, Verify, Correct: A Simple Few Shot Object Detection Method
Dec 10, 2021
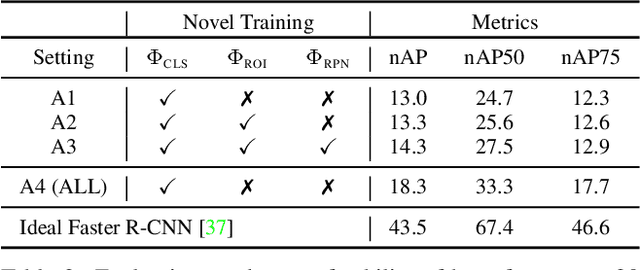


The objective of this paper is few-shot object detection (FSOD) -- the task of expanding an object detector for a new category given only a few instances for training. We introduce a simple pseudo-labelling method to source high-quality pseudo-annotations from the training set, for each new category, vastly increasing the number of training instances and reducing class imbalance; our method finds previously unlabelled instances. Na\"ively training with model predictions yields sub-optimal performance; we present two novel methods to improve the precision of the pseudo-labelling process: first, we introduce a verification technique to remove candidate detections with incorrect class labels; second, we train a specialised model to correct poor quality bounding boxes. After these two novel steps, we obtain a large set of high-quality pseudo-annotations that allow our final detector to be trained end-to-end. Additionally, we demonstrate our method maintains base class performance, and the utility of simple augmentations in FSOD. While benchmarking on PASCAL VOC and MS-COCO, our method achieves state-of-the-art or second-best performance compared to existing approaches across all number of shots.
RSS-Net: Weakly-Supervised Multi-Class Semantic Segmentation with FMCW Radar
Apr 02, 2020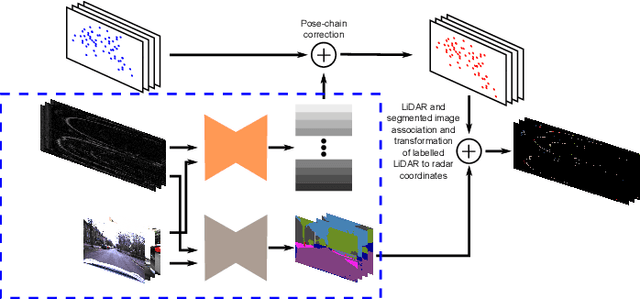
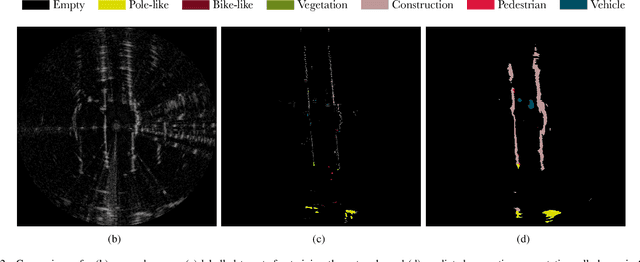


This paper presents an efficient annotation procedure and an application thereof to end-to-end, rich semantic segmentation of the sensed environment using FMCW scanning radar. We advocate radar over the traditional sensors used for this task as it operates at longer ranges and is substantially more robust to adverse weather and illumination conditions. We avoid laborious manual labelling by exploiting the largest radar-focused urban autonomy dataset collected to date, correlating radar scans with RGB cameras and LiDAR sensors, for which semantic segmentation is an already consolidated procedure. The training procedure leverages a state-of-the-art natural image segmentation system which is publicly available and as such, in contrast to previous approaches, allows for the production of copious labels for the radar stream by incorporating four camera and two LiDAR streams. Additionally, the losses are computed taking into account labels to the radar sensor horizon by accumulating LiDAR returns along a pose-chain ahead and behind of the current vehicle position. Finally, we present the network with multi-channel radar scan inputs in order to deal with ephemeral and dynamic scene objects.