 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFantasyVLN: Unified Multimodal Chain-of-Thought Reasoning for Vision-Language Navigation
Jan 20, 2026Achieving human-level performance in Vision-and-Language Navigation (VLN) requires an embodied agent to jointly understand multimodal instructions and visual-spatial context while reasoning over long action sequences. Recent works, such as NavCoT and NavGPT-2, demonstrate the potential of Chain-of-Thought (CoT) reasoning for improving interpretability and long-horizon planning. Moreover, multimodal extensions like OctoNav-R1 and CoT-VLA further validate CoT as a promising pathway toward human-like navigation reasoning. However, existing approaches face critical drawbacks: purely textual CoTs lack spatial grounding and easily overfit to sparse annotated reasoning steps, while multimodal CoTs incur severe token inflation by generating imagined visual observations, making real-time navigation impractical. In this work, we propose FantasyVLN, a unified implicit reasoning framework that preserves the benefits of CoT reasoning without explicit token overhead. Specifically, imagined visual tokens are encoded into a compact latent space using a pretrained Visual AutoRegressor (VAR) during CoT reasoning training, and the model jointly learns from textual, visual, and multimodal CoT modes under a unified multi-CoT strategy. At inference, our model performs direct instruction-to-action mapping while still enjoying reasoning-aware representations. Extensive experiments on LH-VLN show that our approach achieves reasoning-aware yet real-time navigation, improving success rates and efficiency while reducing inference latency by an order of magnitude compared to explicit CoT methods.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
Exploring Patterns Behind Sports
Feb 11, 2025This paper presents a comprehensive framework for time series prediction using a hybrid model that combines ARIMA and LSTM. The model incorporates feature engineering techniques, including embedding and PCA, to transform raw data into a lower-dimensional representation while retaining key information. The embedding technique is used to convert categorical data into continuous vectors, facilitating the capture of complex relationships. PCA is applied to reduce dimensionality and extract principal components, enhancing model performance and computational efficiency. To handle both linear and nonlinear patterns in the data, the ARIMA model captures linear trends, while the LSTM model models complex nonlinear dependencies. The hybrid model is trained on historical data and achieves high accuracy, as demonstrated by low RMSE and MAE scores. Additionally, the paper employs the run test to assess the randomness of sequences, providing insights into the underlying patterns. Ablation studies are conducted to validate the roles of different components in the model, demonstrating the significance of each module. The paper also utilizes the SHAP method to quantify the impact of traditional advantages on the predicted results, offering a detailed understanding of feature importance. The KNN method is used to determine the optimal prediction interval, further enhancing the model's accuracy. The results highlight the effectiveness of combining traditional statistical methods with modern deep learning techniques for robust time series forecasting in Sports.
From Attention to Activation: Unravelling the Enigmas of Large Language Models
Oct 22, 2024We study two strange phenomena in auto-regressive Transformers: (1) the dominance of the first token in attention heads; (2) the occurrence of large outlier activations in the hidden states. We find that popular large language models, such as Llama attend maximally to the first token in 98% of attention heads, a behaviour we attribute to the softmax function. To mitigate this issue, we propose a reformulation of softmax to softmax-1. Furthermore, we identify adaptive optimisers, e.g. Adam, as the primary contributor to the large outlier activations and introduce OrthoAdam, a novel optimiser that utilises orthogonal matrices to transform gradients, to address this issue. Finally, not only do our methods prevent these phenomena from occurring, but additionally, they enable Transformers to sustain their performance when quantised using basic algorithms, something that standard methods are unable to do. In summary, our methods reduce the attention proportion on the first token from 65% to 3.3%, the activation kurtosis in the hidden states from 1657 to 3.1, and perplexity penalty under 4-bit weight quantisation from 3565 to 0.3.
Three Heads Are Better Than One: Complementary Experts for Long-Tailed Semi-supervised Learning
Dec 25, 2023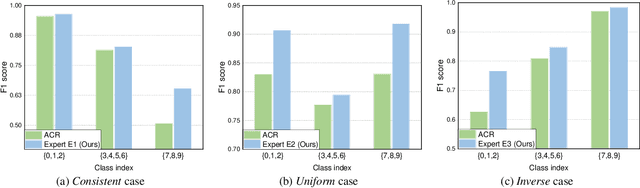
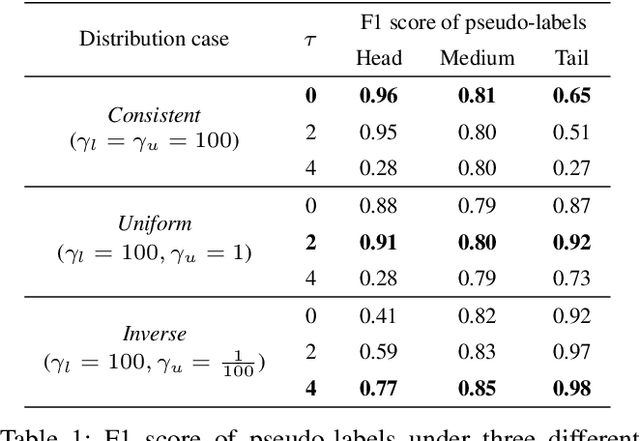
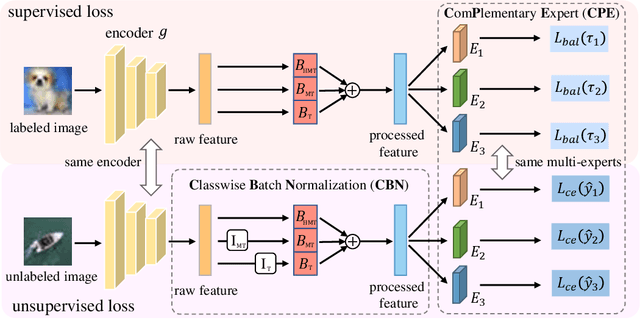
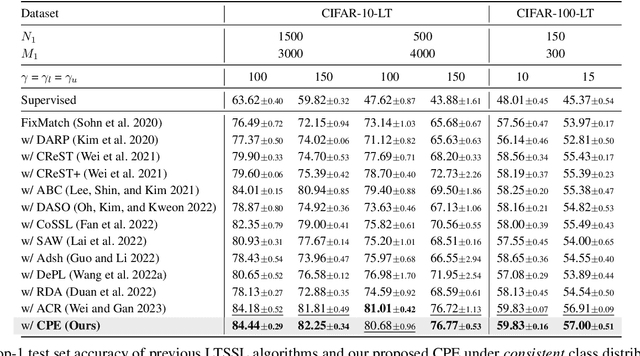
We address the challenging problem of Long-Tailed Semi-Supervised Learning (LTSSL) where labeled data exhibit imbalanced class distribution and unlabeled data follow an unknown distribution. Unlike in balanced SSL, the generated pseudo-labels are skewed towards head classes, intensifying the training bias. Such a phenomenon is even amplified as more unlabeled data will be mislabeled as head classes when the class distribution of labeled and unlabeled datasets are mismatched. To solve this problem, we propose a novel method named ComPlementary Experts (CPE). Specifically, we train multiple experts to model various class distributions, each of them yielding high-quality pseudo-labels within one form of class distribution. Besides, we introduce Classwise Batch Normalization for CPE to avoid performance degradation caused by feature distribution mismatch between head and non-head classes. CPE achieves state-of-the-art performances on CIFAR-10-LT, CIFAR-100-LT, and STL-10-LT dataset benchmarks. For instance, on CIFAR-10-LT, CPE improves test accuracy by over >2.22% compared to baselines. Code is available at https://github.com/machengcheng2016/CPE-LTSSL.
Understanding and Mitigating Overfitting in Prompt Tuning for Vision-Language Models
Nov 14, 2022Pre-trained Vision-Language Models (VLMs) such as CLIP have shown impressive generalization capability in downstream vision tasks with appropriate text prompts. Instead of designing prompts manually, Context Optimization (CoOp) has been recently proposed to learn continuous prompts using task-specific training data. Despite the performance improvements on downstream tasks, several studies have reported that CoOp suffers from the overfitting issue in two aspects: (i) the test accuracy on base classes first gets better and then gets worse during training; (ii) the test accuracy on novel classes keeps decreasing. However, none of the existing studies can understand and mitigate such overfitting problem effectively. In this paper, we first explore the cause of overfitting by analyzing the gradient flow. Comparative experiments reveal that CoOp favors generalizable and spurious features in the early and later training stages respectively, leading to the non-overfitting and overfitting phenomenon. Given those observations, we propose Subspace Prompt Tuning (SubPT) to project the gradients in back-propagation onto the low-rank subspace spanned by the early-stage gradient flow eigenvectors during the entire training process, and successfully eliminate the overfitting problem. Besides, we equip CoOp with Novel Feature Learner (NFL) to enhance the generalization ability of the learned prompts onto novel categories beyond the training set, needless of image training data. Extensive experiments on 11 classification datasets demonstrate that SubPT+NFL consistently boost the performance of CoOp and outperform the state-of-the-art approach CoCoOp. Experiments on more challenging vision downstream tasks including open-vocabulary object detection and zero-shot semantic segmentation also verify the effectiveness of the proposed method. Codes can be found at https://tinyurl.com/mpe64f89.
Mitigating the Mutual Error Amplification for Semi-Supervised Object Detection
Jan 26, 2022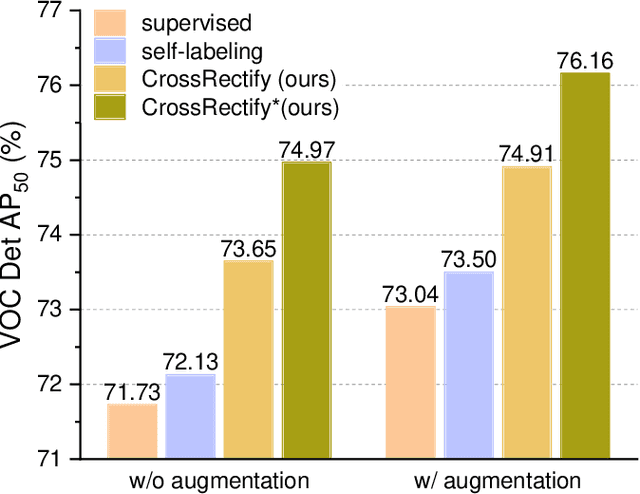
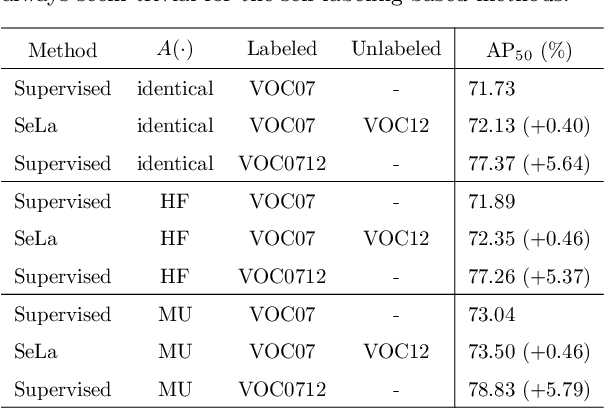
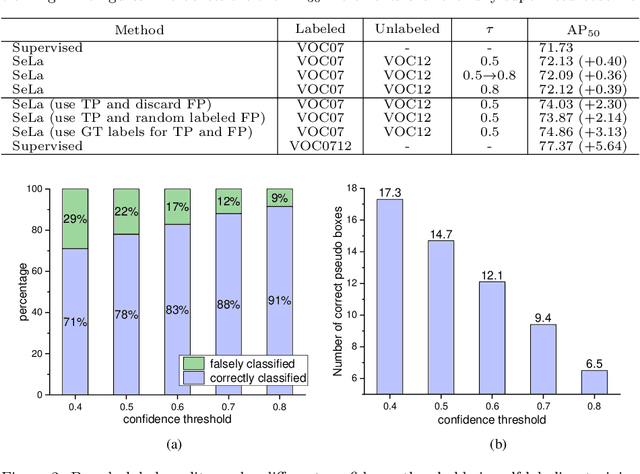
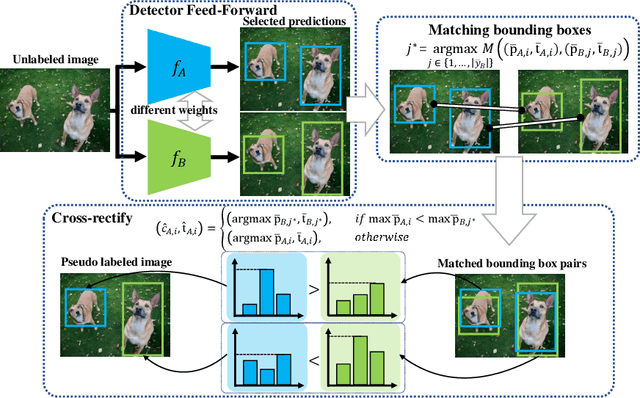
Semi-supervised object detection (SSOD) has achieved substantial progress in recent years. However, it is observed that the performances of self-labeling SSOD methods remain limited. Based on our experimental analysis, we reveal that the reason behind such phenomenon lies in the mutual error amplification between the pseudo labels and the trained detector. In this study, we propose a Cross Teaching (CT) method, aiming to mitigate the mutual error amplification by introducing a rectification mechanism of pseudo labels. CT simultaneously trains multiple detectors with an identical structure but different parameter initialization. In contrast to existing mutual teaching methods that directly treat predictions from other detectors as pseudo labels, we propose the Label Rectification Module (LRM), where the bounding boxes predicted by one detector are rectified by using the corresponding boxes predicted by all other detectors with higher confidence scores. In this way, CT can enhance the pseudo label quality compared with self-labeling and existing mutual teaching methods, and reasonably mitigate the mutual error amplification. Over two popular detector structures, i.e., SSD300 and Faster-RCNN-FPN, the proposed CT method obtains consistent improvements and outperforms the state-of-the-art SSOD methods by 2.2% absolute mAP improvements on the Pascal VOC and MS-COCO benchmarks. The code is available at github.com/machengcheng2016/CrossTeaching-SSOD.
Effective and Robust Detection of Adversarial Examples via Benford-Fourier Coefficients
May 12, 2020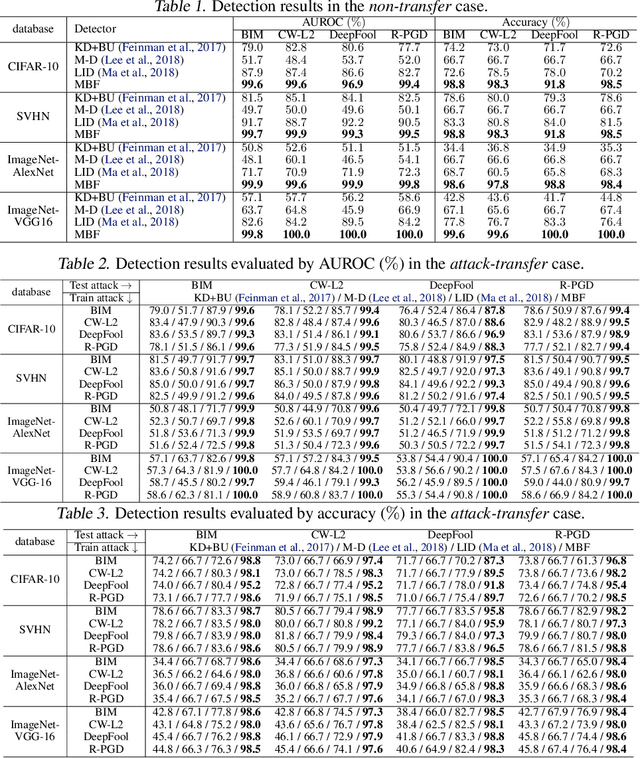

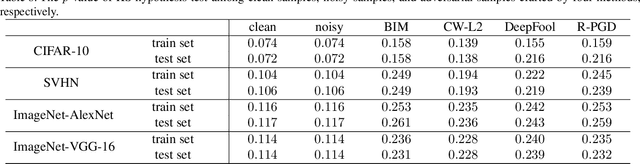
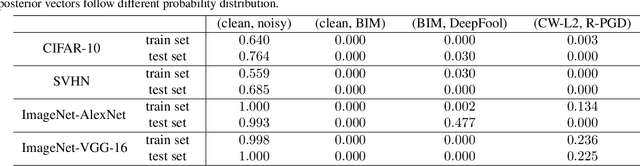
Adversarial examples have been well known as a serious threat to deep neural networks (DNNs). In this work, we study the detection of adversarial examples, based on the assumption that the output and internal responses of one DNN model for both adversarial and benign examples follow the generalized Gaussian distribution (GGD), but with different parameters (i.e., shape factor, mean, and variance). GGD is a general distribution family to cover many popular distributions (e.g., Laplacian, Gaussian, or uniform). It is more likely to approximate the intrinsic distributions of internal responses than any specific distribution. Besides, since the shape factor is more robust to different databases rather than the other two parameters, we propose to construct discriminative features via the shape factor for adversarial detection, employing the magnitude of Benford-Fourier coefficients (MBF), which can be easily estimated using responses. Finally, a support vector machine is trained as the adversarial detector through leveraging the MBF features. Extensive experiments in terms of image classification demonstrate that the proposed detector is much more effective and robust on detecting adversarial examples of different crafting methods and different sources, compared to state-of-the-art adversarial detection methods.