 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal user interface control detection using cross-attention
Apr 08, 2026Detecting user interface (UI) controls from software screenshots is a critical task for automated testing, accessibility, and software analytics, yet it remains challenging due to visual ambiguities, design variability, and the lack of contextual cues in pixel-only approaches. In this paper, we introduce a novel multi-modal extension of YOLOv5 that integrates GPT-generated textual descriptions of UI images into the detection pipeline through cross-attention modules. By aligning visual features with semantic information derived from text embeddings, our model enables more robust and context-aware UI control detection. We evaluate the proposed framework on a large dataset of over 16,000 annotated UI screenshots spanning 23 control classes. Extensive experiments compare three fusion strategies, i.e. element-wise addition, weighted sum, and convolutional fusion, demonstrating consistent improvements over the baseline YOLOv5 model. Among these, convolutional fusion achieved the strongest performance, with significant gains in detecting semantically complex or visually ambiguous classes. These results establish that combining visual and textual modalities can substantially enhance UI element detection, particularly in edge cases where visual information alone is insufficient. Our findings open promising opportunities for more reliable and intelligent tools in software testing, accessibility support, and UI analytics, setting the stage for future research on efficient, robust, and generalizable multi-modal detection systems.
An empirical study of LoRA-based fine-tuning of large language models for automated test case generation
Apr 08, 2026Automated test case generation from natural language requirements remains a challenging problem in software engineering due to the ambiguity of requirements and the need to produce structured, executable test artifacts. Recent advances in LLMs have shown promise in addressing this task; however, their effectiveness depends on task-specific adaptation and efficient fine-tuning strategies. In this paper, we present a comprehensive empirical study on the use of parameter-efficient fine-tuning, specifically LoRA, for requirement-based test case generation. We evaluate multiple LLM families, including open-source and proprietary models, under a unified experimental pipeline. The study systematically explores the impact of key LoRA hyperparameters, including rank, scaling factor, and dropout, on downstream performance. We propose an automated evaluation framework based on GPT-4o, which assesses generated test cases across nine quality dimensions. Experimental results demonstrate that LoRA-based fine-tuning significantly improves the performance of all open-source models, with Ministral-8B achieving the best results among them. Furthermore, we show that a fine-tuned 8B open-source model can achieve performance comparable to pre-fine-tuned GPT-4.1 models, highlighting the effectiveness of parameter-efficient adaptation. While GPT-4.1 models achieve the highest overall performance, the performance gap between proprietary and open-source models is substantially reduced after fine-tuning. These findings provide important insights into model selection, fine-tuning strategies, and evaluation methods for automated test generation. In particular, they demonstrate that cost-efficient, locally deployable open-source models can serve as viable alternatives to proprietary systems when combined with well-designed fine-tuning approaches.
Predictive Regularization Against Visual Representation Degradation in Multimodal Large Language Models
Mar 21, 2026While Multimodal Large Language Models (MLLMs) excel at vision-language tasks, the cost of their language-driven training on internal visual foundational competence remains unclear. In this paper, we conduct a detailed diagnostic analysis to unveil a pervasive issue: visual representation degradation in MLLMs. Specifically, we find that compared to the initial visual features, the visual representation in the middle layers of LLM exhibits both a degradation in global function and patch structure. We attribute this phenomenon to a visual sacrifice driven by the singular text-generation objective, where the model compromises its visual fidelity to optimize for answer generation. We argue that a robust MLLM requires both strong cross-modal reasoning and core visual competence, and propose Predictive Regularization (PRe) to force degraded intermediate features to predict initial visual features, thereby maintaining the inherent visual attributes of the MLLM's internal representations. Extensive experiments confirm that mitigating this visual degradation effectively boosts vision-language performance, underscoring the critical importance of fostering robust internal visual representations within MLLMs for comprehensive multimodal understanding.
Non-Contrast CT Esophageal Varices Grading through Clinical Prior-Enhanced Multi-Organ Analysis
Dec 22, 2025Esophageal varices (EV) represent a critical complication of portal hypertension, affecting approximately 60% of cirrhosis patients with a significant bleeding risk of ~30%. While traditionally diagnosed through invasive endoscopy, non-contrast computed tomography (NCCT) presents a potential non-invasive alternative that has yet to be fully utilized in clinical practice. We present Multi-Organ-COhesion Network++ (MOON++), a novel multimodal framework that enhances EV assessment through comprehensive analysis of NCCT scans. Inspired by clinical evidence correlating organ volumetric relationships with liver disease severity, MOON++ synthesizes imaging characteristics of the esophagus, liver, and spleen through multimodal learning. We evaluated our approach using 1,631 patients, those with endoscopically confirmed EV were classified into four severity grades. Validation in 239 patient cases and independent testing in 289 cases demonstrate superior performance compared to conventional single organ methods, achieving an AUC of 0.894 versus 0.803 for the severe grade EV classification (G3 versus <G3) and 0.921 versus 0.793 for the differentiation of moderate to severe grades (>=G2 versus <G2). We conducted a reader study involving experienced radiologists to further validate the performance of MOON++. To our knowledge, MOON++ represents the first comprehensive multi-organ NCCT analysis framework incorporating clinical knowledge priors for EV assessment, potentially offering a promising non-invasive diagnostic alternative.
D2Pruner: Debiased Importance and Structural Diversity for MLLM Token Pruning
Dec 22, 2025



Processing long visual token sequences poses a significant computational burden on Multimodal Large Language Models (MLLMs). While token pruning offers a path to acceleration, we find that current methods, while adequate for general understanding, catastrophically fail on fine-grained localization tasks. We attribute this failure to the inherent flaws of the two prevailing strategies: importance-based methods suffer from a strong positional bias, an inherent model artifact that distracts from semantic content, while diversity-based methods exhibit structural blindness, disregarding the user's prompt and spatial redundancy. To address this, we introduce D2Pruner, a framework that rectifies these issues by uniquely combining debiased importance with a structural pruning mechanism. Our method first secures a core set of the most critical tokens as pivots based on a debiased attention score. It then performs a Maximal Independent Set (MIS) selection on the remaining tokens, which are modeled on a hybrid graph where edges signify spatial proximity and semantic similarity. This process iteratively preserves the most important and available token while removing its neighbors, ensuring that the supplementary tokens are chosen to maximize importance and diversity. Extensive experiments demonstrate that D2Pruner has exceptional efficiency and fidelity. Applied to LLaVA-1.5-7B for general understanding tasks, it reduces FLOPs by 74.2\% while retaining 99.2\% of its original performance. Furthermore, in challenging localization benchmarks with InternVL-2.5-8B, it maintains 85.7\% performance at a 90\% token reduction rate, marking a significant advancement with up to 63. 53\% improvement over existing methods.
Extracting Events Like Code: A Multi-Agent Programming Framework for Zero-Shot Event Extraction
Nov 17, 2025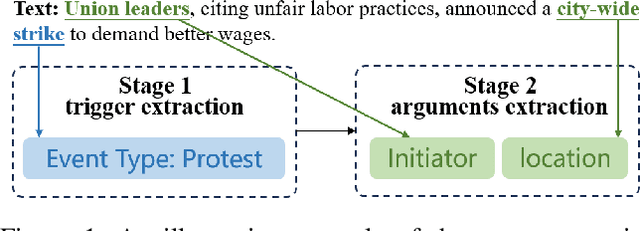
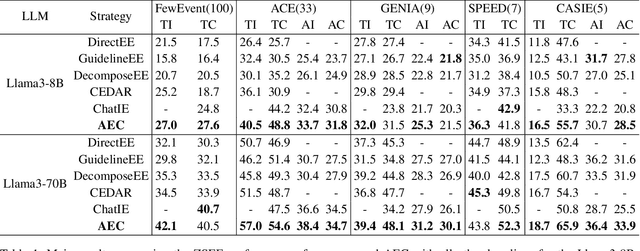
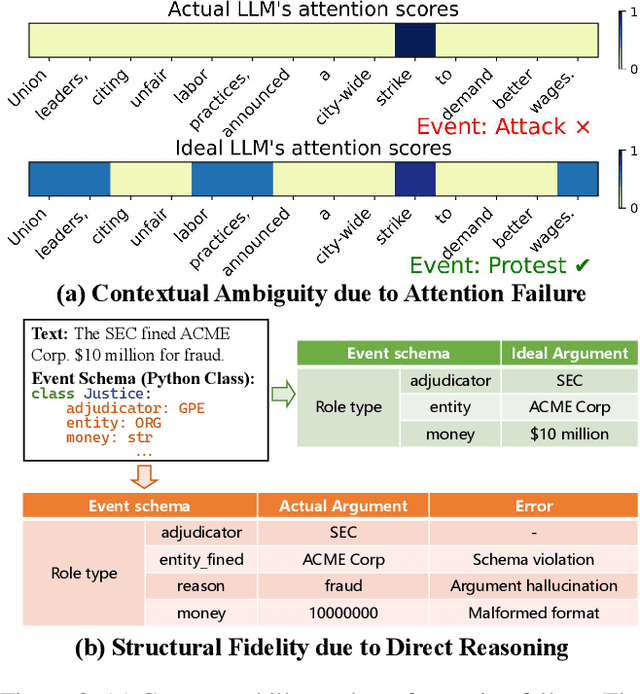
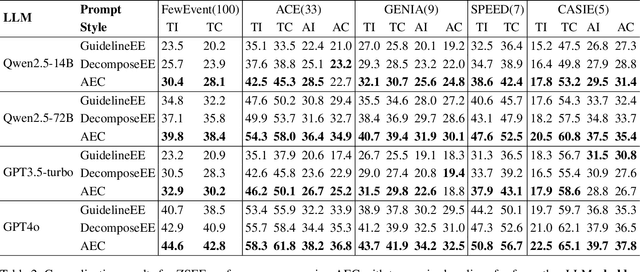
Zero-shot event extraction (ZSEE) remains a significant challenge for large language models (LLMs) due to the need for complex reasoning and domain-specific understanding. Direct prompting often yields incomplete or structurally invalid outputs--such as misclassified triggers, missing arguments, and schema violations. To address these limitations, we present Agent-Event-Coder (AEC), a novel multi-agent framework that treats event extraction like software engineering: as a structured, iterative code-generation process. AEC decomposes ZSEE into specialized subtasks--retrieval, planning, coding, and verification--each handled by a dedicated LLM agent. Event schemas are represented as executable class definitions, enabling deterministic validation and precise feedback via a verification agent. This programming-inspired approach allows for systematic disambiguation and schema enforcement through iterative refinement. By leveraging collaborative agent workflows, AEC enables LLMs to produce precise, complete, and schema-consistent extractions in zero-shot settings. Experiments across five diverse domains and six LLMs demonstrate that AEC consistently outperforms prior zero-shot baselines, showcasing the power of treating event extraction like code generation. The code and data are released on https://github.com/UESTC-GQJ/Agent-Event-Coder.
ITPP: Learning Disentangled Event Dynamics in Marked Temporal Point Processes
Nov 08, 2025Marked Temporal Point Processes (MTPPs) provide a principled framework for modeling asynchronous event sequences by conditioning on the history of past events. However, most existing MTPP models rely on channel-mixing strategies that encode information from different event types into a single, fixed-size latent representation. This entanglement can obscure type-specific dynamics, leading to performance degradation and increased risk of overfitting. In this work, we introduce ITPP, a novel channel-independent architecture for MTPP modeling that decouples event type information using an encoder-decoder framework with an ODE-based backbone. Central to ITPP is a type-aware inverted self-attention mechanism, designed to explicitly model inter-channel correlations among heterogeneous event types. This architecture enhances effectiveness and robustness while reducing overfitting. Comprehensive experiments on multiple real-world and synthetic datasets demonstrate that ITPP consistently outperforms state-of-the-art MTPP models in both predictive accuracy and generalization.
MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
Nov 07, 2025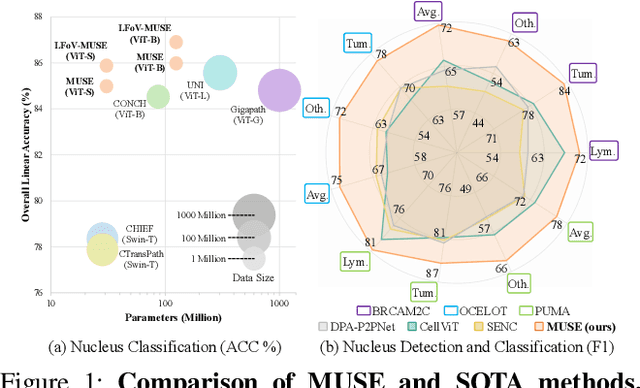
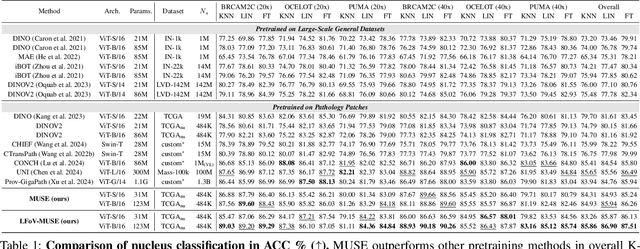
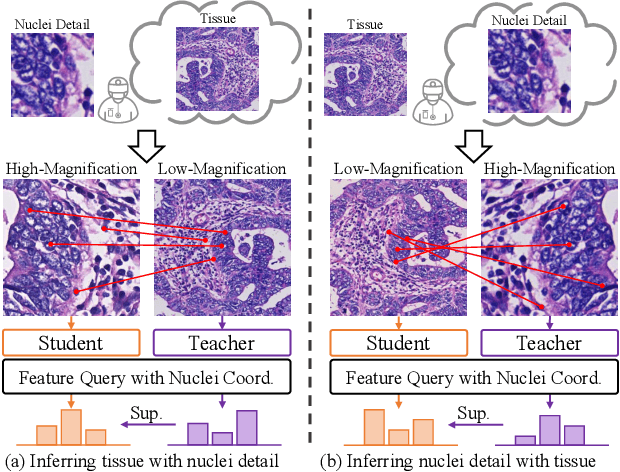
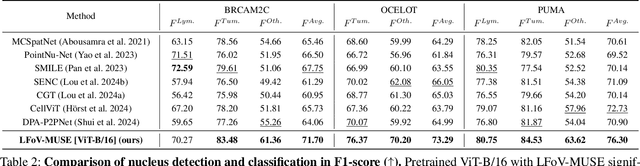
Nucleus detection and classification (NDC) in histopathology analysis is a fundamental task that underpins a wide range of high-level pathology applications. However, existing methods heavily rely on labor-intensive nucleus-level annotations and struggle to fully exploit large-scale unlabeled data for learning discriminative nucleus representations. In this work, we propose MUSE (MUlti-scale denSE self-distillation), a novel self-supervised learning method tailored for NDC. At its core is NuLo (Nucleus-based Local self-distillation), a coordinate-guided mechanism that enables flexible local self-distillation based on predicted nucleus positions. By removing the need for strict spatial alignment between augmented views, NuLo allows critical cross-scale alignment, thus unlocking the capacity of models for fine-grained nucleus-level representation. To support MUSE, we design a simple yet effective encoder-decoder architecture and a large field-of-view semi-supervised fine-tuning strategy that together maximize the value of unlabeled pathology images. Extensive experiments on three widely used benchmarks demonstrate that MUSE effectively addresses the core challenges of histopathological NDC. The resulting models not only surpass state-of-the-art supervised baselines but also outperform generic pathology foundation models.
Towards Rationale-Answer Alignment of LVLMs via Self-Rationale Calibration
Sep 17, 2025Large Vision-Language Models (LVLMs) have manifested strong visual question answering capability. However, they still struggle with aligning the rationale and the generated answer, leading to inconsistent reasoning and incorrect responses. To this end, this paper introduces the Self-Rationale Calibration (SRC) framework to iteratively calibrate the alignment between rationales and answers. SRC begins by employing a lightweight "rationale fine-tuning" approach, which modifies the model's response format to require a rationale before deriving an answer without explicit prompts. Next, SRC searches for a diverse set of candidate responses from the fine-tuned LVLMs for each sample, followed by a proposed pairwise scoring strategy using a tailored scoring model, R-Scorer, to evaluate both rationale quality and factual consistency of candidates. Based on a confidence-weighted preference curation process, SRC decouples the alignment calibration into a preference fine-tuning manner, leading to significant improvements of LVLMs in perception, reasoning, and generalization across multiple benchmarks. Our results emphasize the rationale-oriented alignment in exploring the potential of LVLMs.
VISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference
Aug 25, 2025In this study, we introduce a novel method called group-wise \textbf{VI}sual token \textbf{S}election and \textbf{A}ggregation (VISA) to address the issue of inefficient inference stemming from excessive visual tokens in multimoal large language models (MLLMs). Compared with previous token pruning approaches, our method can preserve more visual information while compressing visual tokens. We first propose a graph-based visual token aggregation (VTA) module. VTA treats each visual token as a node, forming a graph based on semantic similarity among visual tokens. It then aggregates information from removed tokens into kept tokens based on this graph, producing a more compact visual token representation. Additionally, we introduce a group-wise token selection strategy (GTS) to divide visual tokens into kept and removed ones, guided by text tokens from the final layers of each group. This strategy progressively aggregates visual information, enhancing the stability of the visual information extraction process. We conduct comprehensive experiments on LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA across various benchmarks to validate the efficacy of VISA. Our method consistently outperforms previous methods, achieving a superior trade-off between model performance and inference speed. The code is available at https://github.com/mobiushy/VISA.