 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill on a Diet: Efficient Knowledge Distillation via Learnable Data Pruning
Jun 24, 2026Knowledge Distillation (KD) is widely used to obtain compact models for efficient inference in resource-constrained environments. Yet the computational overhead of the distillation process itself is often overlooked, raising the question of whether a better student model can be obtained with less data and less compute via data pruning. However, existing data pruning methods are not designed for KD: some introduce substantial overhead, such as obtaining training dynamics through retraining, while others rely on heuristic selection rules that fail to capture what KD actually requires, often resulting in suboptimal subsets. To address these issues, we propose IF-Beta, an efficient data pruning framework that combines influence functions with a learnable sampling policy. Empirically, we first demonstrate that influence functions can serve as an effective and efficient estimator of sample impact in KD settings, where only a pretrained teacher is available. Building on this, our sampling policy is specifically parameterized by a Beta distribution, whose highly flexible two-parameter family allows the policy to adapt to diverse pruning regimes rather than being tied to fixed heuristic forms. Next, we formulate KD pruning as optimizing this policy through a bilevel objective, where the inner loop operates in the teacher feature space with a KD-aligned objective, enabling fast proxy training, while the outer loop updates the policy parameters to maximize distillation performance. This design ensures that IF-Beta is both computationally efficient and inherently aligned with the goals of KD. Extensive experiments on CIFAR-10/100 and ImageNet show that IF-Beta consistently outperforms other baselines across a wide range of pruning ratios. Remarkably, IF-Beta enables students trained on less data and less compute to surpass the performance of students distilled on the full dataset.
Towards Rationale-Answer Alignment of LVLMs via Self-Rationale Calibration
Sep 17, 2025Large Vision-Language Models (LVLMs) have manifested strong visual question answering capability. However, they still struggle with aligning the rationale and the generated answer, leading to inconsistent reasoning and incorrect responses. To this end, this paper introduces the Self-Rationale Calibration (SRC) framework to iteratively calibrate the alignment between rationales and answers. SRC begins by employing a lightweight "rationale fine-tuning" approach, which modifies the model's response format to require a rationale before deriving an answer without explicit prompts. Next, SRC searches for a diverse set of candidate responses from the fine-tuned LVLMs for each sample, followed by a proposed pairwise scoring strategy using a tailored scoring model, R-Scorer, to evaluate both rationale quality and factual consistency of candidates. Based on a confidence-weighted preference curation process, SRC decouples the alignment calibration into a preference fine-tuning manner, leading to significant improvements of LVLMs in perception, reasoning, and generalization across multiple benchmarks. Our results emphasize the rationale-oriented alignment in exploring the potential of LVLMs.
A Simple yet Powerful Instance-Aware Prompting Framework for Training-free Camouflaged Object Segmentation
Aug 13, 2025Camouflaged Object Segmentation (COS) remains highly challenging due to the intrinsic visual similarity between target objects and their surroundings. While training-based COS methods achieve good performance, their performance degrades rapidly with increased annotation sparsity. To circumvent this limitation, recent studies have explored training-free COS methods, leveraging the Segment Anything Model (SAM) by automatically generating visual prompts from a single task-generic prompt (\textit{e.g.}, "\textit{camouflaged animal}") uniformly applied across all test images. However, these methods typically produce only semantic-level visual prompts, causing SAM to output coarse semantic masks and thus failing to handle scenarios with multiple discrete camouflaged instances effectively. To address this critical limitation, we propose a simple yet powerful \textbf{I}nstance-\textbf{A}ware \textbf{P}rompting \textbf{F}ramework (IAPF), the first training-free COS pipeline that explicitly converts a task-generic prompt into fine-grained instance masks. Specifically, the IAPF comprises three steps: (1) Text Prompt Generator, utilizing task-generic queries to prompt a Multimodal Large Language Model (MLLM) for generating image-specific foreground and background tags; (2) \textbf{Instance Mask Generator}, leveraging Grounding DINO to produce precise instance-level bounding box prompts, alongside the proposed Single-Foreground Multi-Background Prompting strategy to sample region-constrained point prompts within each box, enabling SAM to yield a candidate instance mask; (3) Self-consistency Instance Mask Voting, which selects the final COS prediction by identifying the candidate mask most consistent across multiple candidate instance masks. Extensive evaluations on standard COS benchmarks demonstrate that the proposed IAPF significantly surpasses existing state-of-the-art training-free COS methods.
See Different, Think Better: Visual Variations Mitigating Hallucinations in LVLMs
Jul 30, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in visual understanding and multimodal reasoning. However, LVLMs frequently exhibit hallucination phenomena, manifesting as the generated textual responses that demonstrate inconsistencies with the provided visual content. Existing hallucination mitigation methods are predominantly text-centric, the challenges of visual-semantic alignment significantly limit their effectiveness, especially when confronted with fine-grained visual understanding scenarios. To this end, this paper presents ViHallu, a Vision-Centric Hallucination mitigation framework that enhances visual-semantic alignment through Visual Variation Image Generation and Visual Instruction Construction. ViHallu introduces visual variation images with controllable visual alterations while maintaining the overall image structure. These images, combined with carefully constructed visual instructions, enable LVLMs to better understand fine-grained visual content through fine-tuning, allowing models to more precisely capture the correspondence between visual content and text, thereby enhancing visual-semantic alignment. Extensive experiments on multiple benchmarks show that ViHallu effectively enhances models' fine-grained visual understanding while significantly reducing hallucination tendencies. Furthermore, we release ViHallu-Instruction, a visual instruction dataset specifically designed for hallucination mitigation and visual-semantic alignment. Code is available at https://github.com/oliviadzy/ViHallu.
* Accepted by ACM MM25
Stepwise Decomposition and Dual-stream Focus: A Novel Approach for Training-free Camouflaged Object Segmentation
Jun 07, 2025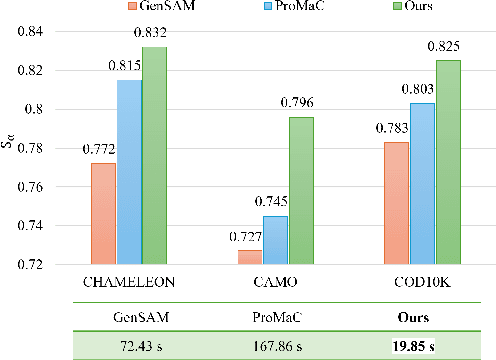
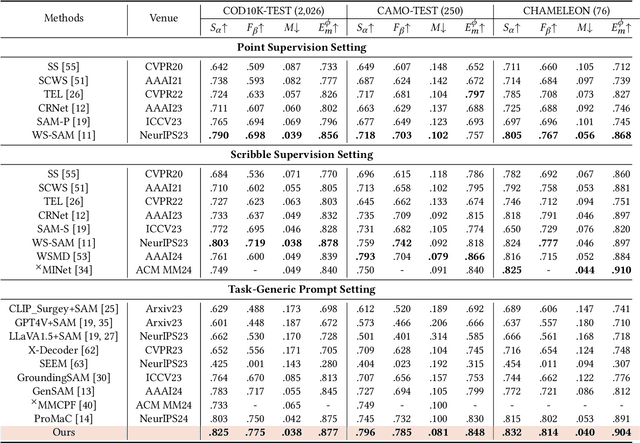
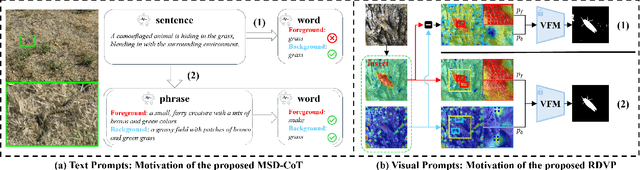
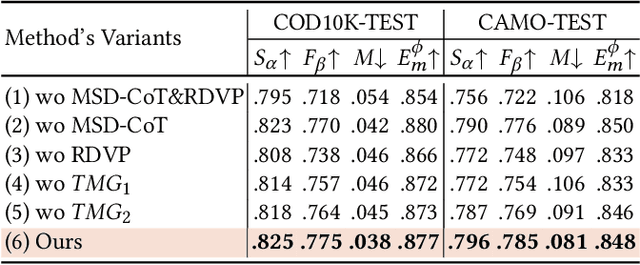
While promptable segmentation (\textit{e.g.}, SAM) has shown promise for various segmentation tasks, it still requires manual visual prompts for each object to be segmented. In contrast, task-generic promptable segmentation aims to reduce the need for such detailed prompts by employing only a task-generic prompt to guide segmentation across all test samples. However, when applied to Camouflaged Object Segmentation (COS), current methods still face two critical issues: 1) \textit{\textbf{semantic ambiguity in getting instance-specific text prompts}}, which arises from insufficient discriminative cues in holistic captions, leading to foreground-background confusion; 2) \textit{\textbf{semantic discrepancy combined with spatial separation in getting instance-specific visual prompts}}, which results from global background sampling far from object boundaries with low feature correlation, causing SAM to segment irrelevant regions. To address the issues above, we propose \textbf{RDVP-MSD}, a novel training-free test-time adaptation framework that synergizes \textbf{R}egion-constrained \textbf{D}ual-stream \textbf{V}isual \textbf{P}rompting (RDVP) via \textbf{M}ultimodal \textbf{S}tepwise \textbf{D}ecomposition Chain of Thought (MSD-CoT). MSD-CoT progressively disentangles image captions to eliminate semantic ambiguity, while RDVP injects spatial constraints into visual prompting and independently samples visual prompts for foreground and background points, effectively mitigating semantic discrepancy and spatial separation. Without requiring any training or supervision, RDVP-MSD achieves a state-of-the-art segmentation result on multiple COS benchmarks and delivers a faster inference speed than previous methods, demonstrating significantly improved accuracy and efficiency. The codes will be available at \href{https://github.com/ycyinchao/RDVP-MSD}{https://github.com/ycyinchao/RDVP-MSD}
Antidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Apr 29, 2025



Large Vision-Language Models (LVLMs) have achieved impressive results across various cross-modal tasks. However, hallucinations, i.e., the models generating counterfactual responses, remain a challenge. Though recent studies have attempted to alleviate object perception hallucinations, they focus on the models' response generation, and overlooking the task question itself. This paper discusses the vulnerability of LVLMs in solving counterfactual presupposition questions (CPQs), where the models are prone to accept the presuppositions of counterfactual objects and produce severe hallucinatory responses. To this end, we introduce "Antidote", a unified, synthetic data-driven post-training framework for mitigating both types of hallucination above. It leverages synthetic data to incorporate factual priors into questions to achieve self-correction, and decouple the mitigation process into a preference optimization problem. Furthermore, we construct "CP-Bench", a novel benchmark to evaluate LVLMs' ability to correctly handle CPQs and produce factual responses. Applied to the LLaVA series, Antidote can simultaneously enhance performance on CP-Bench by over 50%, POPE by 1.8-3.3%, and CHAIR & SHR by 30-50%, all without relying on external supervision from stronger LVLMs or human feedback and introducing noticeable catastrophic forgetting issues.
Intrinsic Saliency Guided Trunk-Collateral Network for Unsupervised Video Object Segmentation
Apr 08, 2025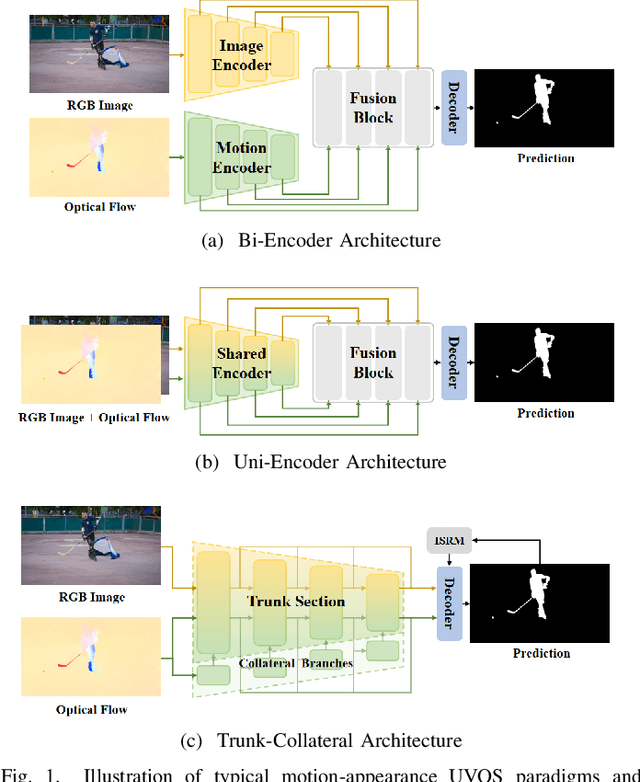

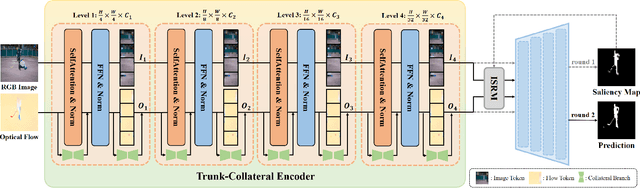
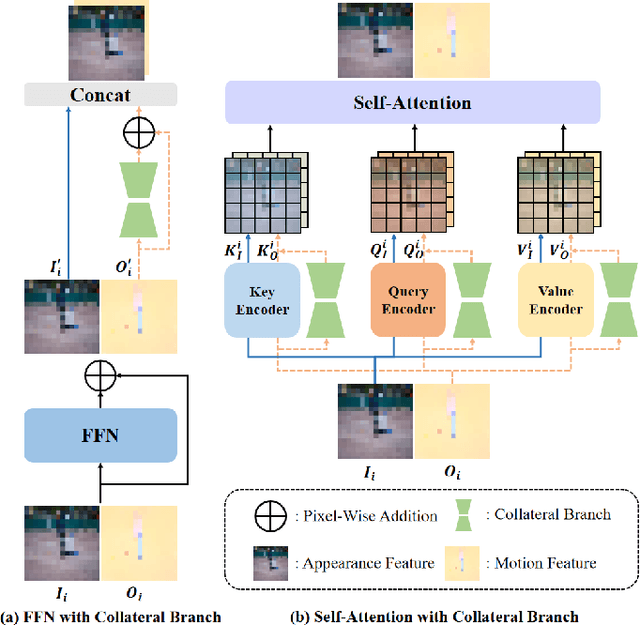
Recent unsupervised video object segmentation (UVOS) methods predominantly adopt the motion-appearance paradigm. Mainstream motion-appearance approaches use either the two-encoder structure to separately encode motion and appearance features, or the single-encoder structure for joint encoding. However, these methods fail to properly balance the motion-appearance relationship. Consequently, even with complex fusion modules for motion-appearance integration, the extracted suboptimal features degrade the models' overall performance. Moreover, the quality of optical flow varies across scenarios, making it insufficient to rely solely on optical flow to achieve high-quality segmentation results. To address these challenges, we propose the Intrinsic Saliency guided Trunk-Collateral Net}work (ISTC-Net), which better balances the motion-appearance relationship and incorporates model's intrinsic saliency information to enhance segmentation performance. Specifically, considering that optical flow maps are derived from RGB images, they share both commonalities and differences. We propose a novel Trunk-Collateral structure. The shared trunk backbone captures the motion-appearance commonality, while the collateral branch learns the uniqueness of motion features. Furthermore, an Intrinsic Saliency guided Refinement Module (ISRM) is devised to efficiently leverage the model's intrinsic saliency information to refine high-level features, and provide pixel-level guidance for motion-appearance fusion, thereby enhancing performance without additional input. Experimental results show that ISTC-Net achieved state-of-the-art performance on three UVOS datasets (89.2% J&F on DAVIS-16, 76% J on YouTube-Objects, 86.4% J on FBMS) and four standard video salient object detection (VSOD) benchmarks with the notable increase, demonstrating its effectiveness and superiority over previous methods.
ToVE: Efficient Vision-Language Learning via Knowledge Transfer from Vision Experts
Apr 01, 2025



Vision-language (VL) learning requires extensive visual perception capabilities, such as fine-grained object recognition and spatial perception. Recent works typically rely on training huge models on massive datasets to develop these capabilities. As a more efficient alternative, this paper proposes a new framework that Transfers the knowledge from a hub of Vision Experts (ToVE) for efficient VL learning, leveraging pre-trained vision expert models to promote visual perception capability. Specifically, building on a frozen CLIP encoder that provides vision tokens for image-conditioned language generation, ToVE introduces a hub of multiple vision experts and a token-aware gating network that dynamically routes expert knowledge to vision tokens. In the transfer phase, we propose a "residual knowledge transfer" strategy, which not only preserves the generalizability of the vision tokens but also allows detachment of low-contributing experts to improve inference efficiency. Further, we explore to merge these expert knowledge to a single CLIP encoder, creating a knowledge-merged CLIP that produces more informative vision tokens without expert inference during deployment. Experiment results across various VL tasks demonstrate that the proposed ToVE achieves competitive performance with two orders of magnitude fewer training data.
Optimized Gradient Clipping for Noisy Label Learning
Dec 12, 2024



Previous research has shown that constraining the gradient of loss function with respect to model-predicted probabilities can enhance the model robustness against noisy labels. These methods typically specify a fixed optimal threshold for gradient clipping through validation data to obtain the desired robustness against noise. However, this common practice overlooks the dynamic distribution of gradients from both clean and noisy-labeled samples at different stages of training, significantly limiting the model capability to adapt to the variable nature of gradients throughout the training process. To address this issue, we propose a simple yet effective approach called Optimized Gradient Clipping (OGC), which dynamically adjusts the clipping threshold based on the ratio of noise gradients to clean gradients after clipping, estimated by modeling the distributions of clean and noisy samples. This approach allows us to modify the clipping threshold at each training step, effectively controlling the influence of noise gradients. Additionally, we provide statistical analysis to certify the noise-tolerance ability of OGC. Our extensive experiments across various types of label noise, including symmetric, asymmetric, instance-dependent, and real-world noise, demonstrate the effectiveness of our approach. The code and a technical appendix for better digital viewing are included as supplementary materials and scheduled to be open-sourced upon publication.
Revisiting Energy-Based Model for Out-of-Distribution Detection
Dec 04, 2024

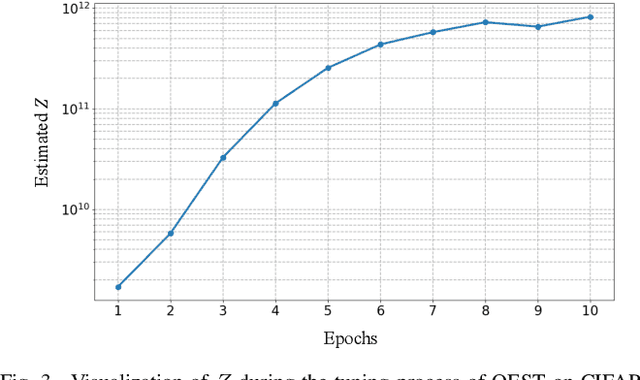
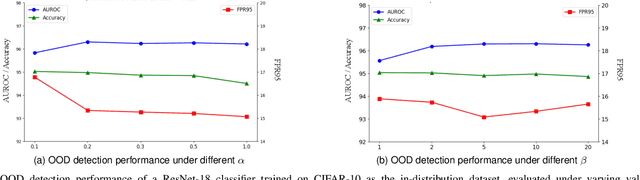
Out-of-distribution (OOD) detection is an essential approach to robustifying deep learning models, enabling them to identify inputs that fall outside of their trained distribution. Existing OOD detection methods usually depend on crafted data, such as specific outlier datasets or elaborate data augmentations. While this is reasonable, the frequent mismatch between crafted data and OOD data limits model robustness and generalizability. In response to this issue, we introduce Outlier Exposure by Simple Transformations (OEST), a framework that enhances OOD detection by leveraging "peripheral-distribution" (PD) data. Specifically, PD data are samples generated through simple data transformations, thus providing an efficient alternative to manually curated outliers. We adopt energy-based models (EBMs) to study PD data. We recognize the "energy barrier" in OOD detection, which characterizes the energy difference between in-distribution (ID) and OOD samples and eases detection. PD data are introduced to establish the energy barrier during training. Furthermore, this energy barrier concept motivates a theoretically grounded energy-barrier loss to replace the classical energy-bounded loss, leading to an improved paradigm, OEST*, which achieves a more effective and theoretically sound separation between ID and OOD samples. We perform empirical validation of our proposal, and extensive experiments across various benchmarks demonstrate that OEST* achieves better or similar accuracy compared with state-of-the-art methods.