 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Priv Pruning : Efficient Differential Private Fine-Tuning in Multimodal Large Language Models
Jun 08, 2025Differential Privacy (DP) is a widely adopted technique, valued for its effectiveness in protecting the privacy of task-specific datasets, making it a critical tool for large language models. However, its effectiveness in Multimodal Large Language Models (MLLMs) remains uncertain. Applying Differential Privacy (DP) inherently introduces substantial computation overhead, a concern particularly relevant for MLLMs which process extensive textual and visual data. Furthermore, a critical challenge of DP is that the injected noise, necessary for privacy, scales with parameter dimensionality, leading to pronounced model degradation; This trade-off between privacy and utility complicates the application of Differential Privacy (DP) to complex architectures like MLLMs. To address these, we propose Dual-Priv Pruning, a framework that employs two complementary pruning mechanisms for DP fine-tuning in MLLMs: (i) visual token pruning to reduce input dimensionality by removing redundant visual information, and (ii) gradient-update pruning during the DP optimization process. This second mechanism selectively prunes parameter updates based on the magnitude of noisy gradients, aiming to mitigate noise impact and improve utility. Experiments demonstrate that our approach achieves competitive results with minimal performance degradation. In terms of computational efficiency, our approach consistently utilizes less memory than standard DP-SGD. While requiring only 1.74% more memory than zeroth-order methods which suffer from severe performance issues on A100 GPUs, our method demonstrates leading memory efficiency on H20 GPUs. To the best of our knowledge, we are the first to explore DP fine-tuning in MLLMs. Our code is coming soon.
Robust Video-Based Pothole Detection and Area Estimation for Intelligent Vehicles with Depth Map and Kalman Smoothing
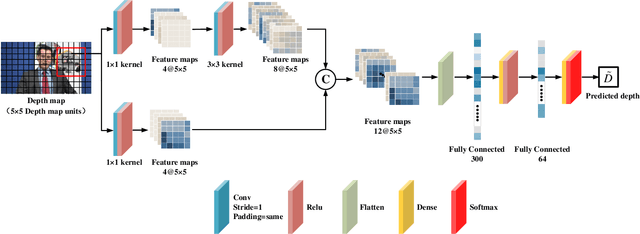
May 27, 2025Road potholes pose a serious threat to driving safety and comfort, making their detection and assessment a critical task in fields such as autonomous driving. When driving vehicles, the operators usually avoid large potholes and approach smaller ones at reduced speeds to ensure safety. Therefore, accurately estimating pothole area is of vital importance. Most existing vision-based methods rely on distance priors to construct geometric models. However, their performance is susceptible to variations in camera angles and typically relies on the assumption of a flat road surface, potentially leading to significant errors in complex real-world environments. To address these problems, a robust pothole area estimation framework that integrates object detection and monocular depth estimation in a video stream is proposed in this paper. First, to enhance pothole feature extraction and improve the detection of small potholes, ACSH-YOLOv8 is proposed with ACmix module and the small object detection head. Then, the BoT-SORT algorithm is utilized for pothole tracking, while DepthAnything V2 generates depth maps for each frame. With the obtained depth maps and potholes labels, a novel Minimum Bounding Triangulated Pixel (MBTP) method is proposed for pothole area estimation. Finally, Kalman Filter based on Confidence and Distance (CDKF) is developed to maintain consistency of estimation results across consecutive frames. The results show that ACSH-YOLOv8 model achieves an AP(50) of 76.6%, representing a 7.6% improvement over YOLOv8. Through CDKF optimization across consecutive frames, pothole predictions become more robust, thereby enhancing the method's practical applicability.
Active Negative Loss: A Robust Framework for Learning with Noisy Labels
Dec 03, 2024
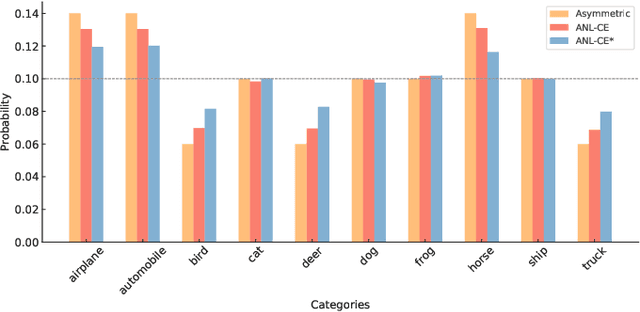

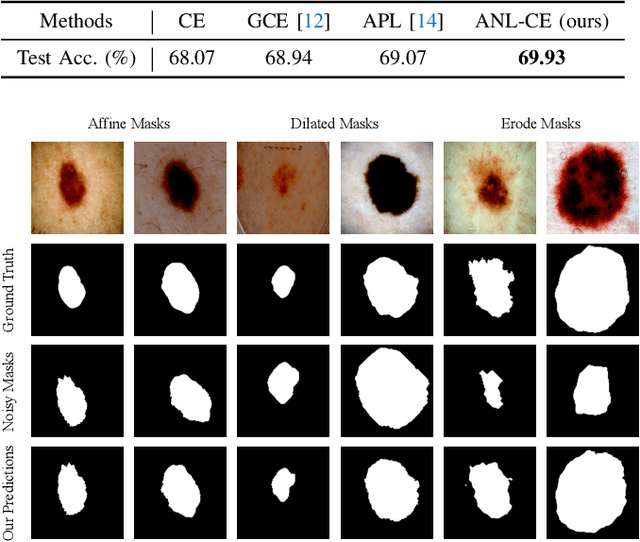
Deep supervised learning has achieved remarkable success across a wide range of tasks, yet it remains susceptible to overfitting when confronted with noisy labels. To address this issue, noise-robust loss functions offer an effective solution for enhancing learning in the presence of label noise. In this work, we systematically investigate the limitation of the recently proposed Active Passive Loss (APL), which employs Mean Absolute Error (MAE) as its passive loss function. Despite the robustness brought by MAE, one of its key drawbacks is that it pays equal attention to clean and noisy samples; this feature slows down convergence and potentially makes training difficult, particularly in large-scale datasets. To overcome these challenges, we introduce a novel loss function class, termed Normalized Negative Loss Functions (NNLFs), which serve as passive loss functions within the APL framework. NNLFs effectively address the limitations of MAE by concentrating more on memorized clean samples. By replacing MAE in APL with our proposed NNLFs, we enhance APL and present a new framework called Active Negative Loss (ANL). Moreover, in non-symmetric noise scenarios, we propose an entropy-based regularization technique to mitigate the vulnerability to the label imbalance. Extensive experiments demonstrate that the new loss functions adopted by our ANL framework can achieve better or comparable performance to state-of-the-art methods across various label noise types and in image segmentation tasks. The source code is available at: https://github.com/Virusdoll/Active-Negative-Loss.
Non-Intrusive Electric Load Monitoring Approach Based on Current Feature Visualization for Smart Energy Management
Aug 08, 2023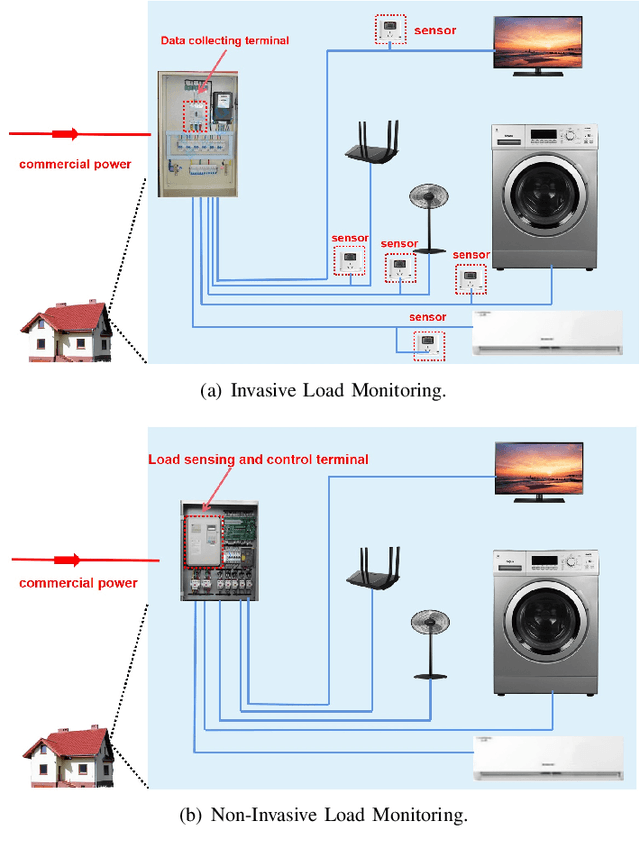
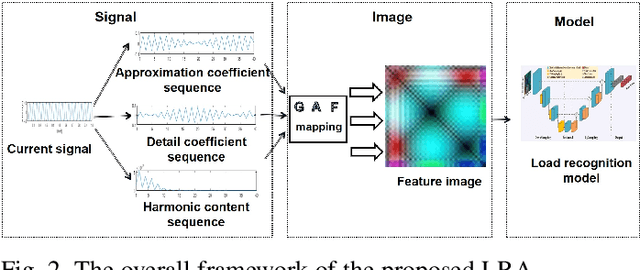
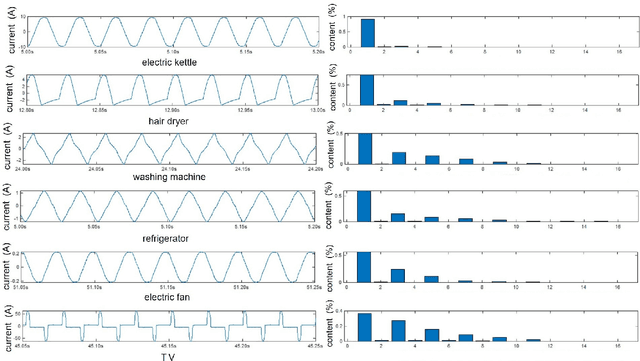
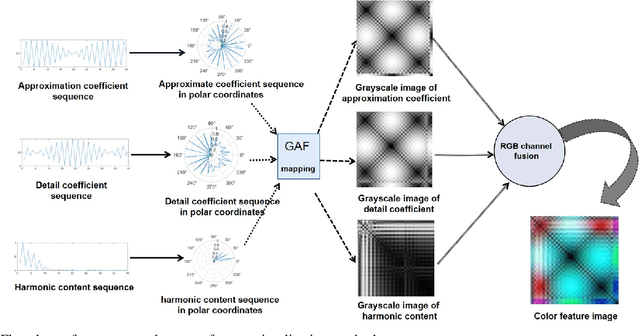
The state-of-the-art smart city has been calling for an economic but efficient energy management over large-scale network, especially for the electric power system. It is a critical issue to monitor, analyze and control electric loads of all users in system. In this paper, we employ the popular computer vision techniques of AI to design a non-invasive load monitoring method for smart electric energy management. First of all, we utilize both signal transforms (including wavelet transform and discrete Fourier transform) and Gramian Angular Field (GAF) methods to map one-dimensional current signals onto two-dimensional color feature images. Second, we propose to recognize all electric loads from color feature images using a U-shape deep neural network with multi-scale feature extraction and attention mechanism. Third, we design our method as a cloud-based, non-invasive monitoring of all users, thereby saving energy cost during electric power system control. Experimental results on both public and our private datasets have demonstrated our method achieves superior performances than its peers, and thus supports efficient energy management over large-scale Internet of Things (IoT).
Deep Quality Assessment of Compressed Videos: A Subjective and Objective Study
May 07, 2022
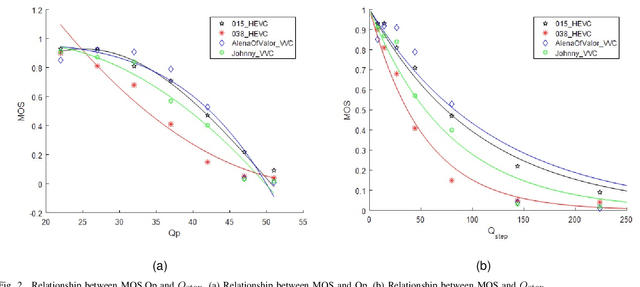
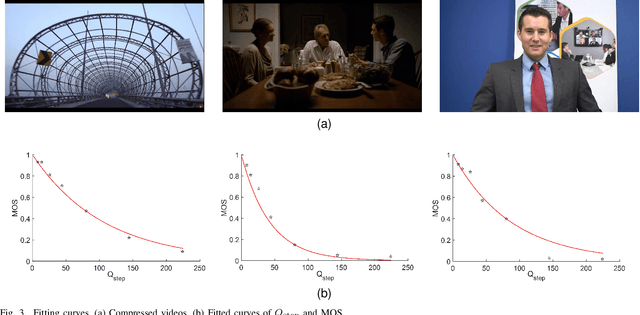
In the video coding process, the perceived quality of a compressed video is evaluated by full-reference quality evaluation metrics. However, it is difficult to obtain reference videos with perfect quality. To solve this problem, it is critical to design no-reference compressed video quality assessment algorithms, which assists in measuring the quality of experience on the server side and resource allocation on the network side. Convolutional Neural Network (CNN) has shown its advantage in Video Quality Assessment (VQA) with promising successes in recent years. A large-scale quality database is very important for learning accurate and powerful compressed video quality metrics. In this work, a semi-automatic labeling method is adopted to build a large-scale compressed video quality database, which allows us to label a large number of compressed videos with manageable human workload. The resulting Compressed Video quality database with Semi-Automatic Ratings (CVSAR), so far the largest of compressed video quality database. We train a no-reference compressed video quality assessment model with a 3D CNN for SpatioTemporal Feature Extraction and Evaluation (STFEE). Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The CVSAR database and STFEE model will be made publicly available to facilitate reproducible research.
Efficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation
May 07, 2022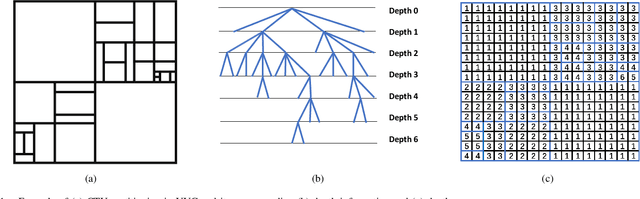
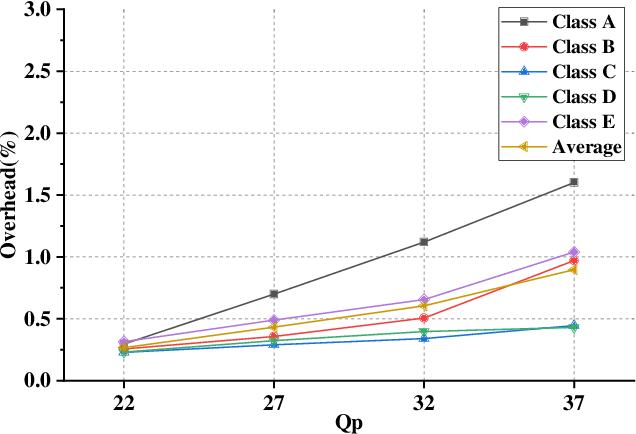
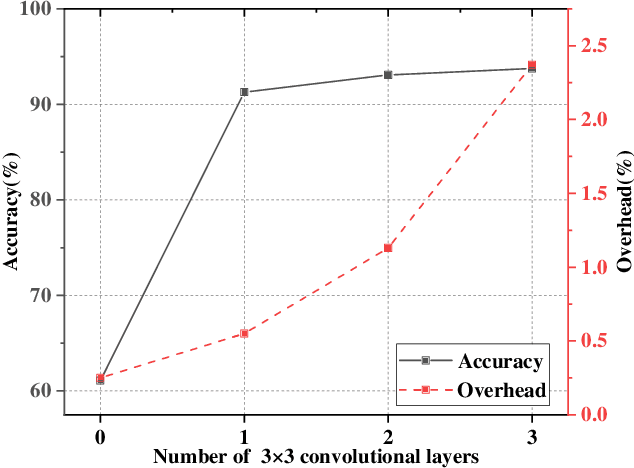
The ever-growing multimedia traffic has underscored the importance of effective multimedia codecs. Among them, the up-to-date lossy video coding standard, Versatile Video Coding (VVC), has been attracting attentions of video coding community. However, the gain of VVC is achieved at the cost of significant encoding complexity, which brings the need to realize fast encoder with comparable Rate Distortion (RD) performance. In this paper, we propose to optimize the VVC complexity at intra-frame prediction, with a two-stage framework of deep feature fusion and probability estimation. At the first stage, we employ the deep convolutional network to extract the spatialtemporal neighboring coding features. Then we fuse all reference features obtained by different convolutional kernels to determine an optimal intra coding depth. At the second stage, we employ a probability-based model and the spatial-temporal coherence to select the candidate partition modes within the optimal coding depth. Finally, these selected depths and partitions are executed whilst unnecessary computations are excluded. Experimental results on standard database demonstrate the superiority of proposed method, especially for High Definition (HD) and Ultra-HD (UHD) video sequences.
Learning-Based Quality Assessment for Image Super-Resolution
Dec 16, 2020
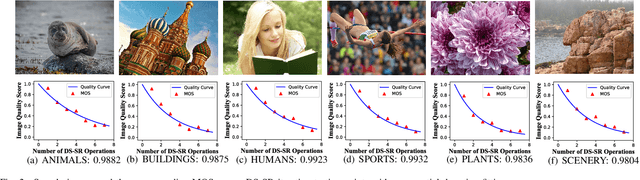

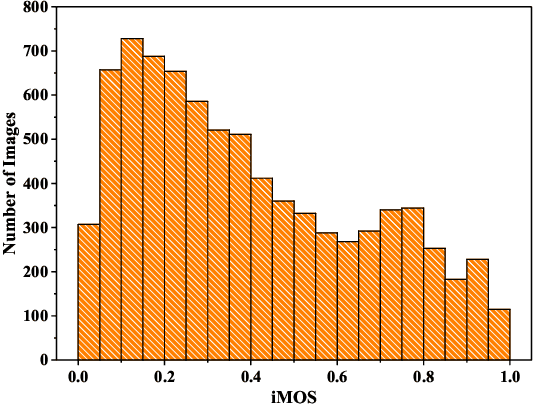
Image Super-Resolution (SR) techniques improve visual quality by enhancing the spatial resolution of images. Quality evaluation metrics play a critical role in comparing and optimizing SR algorithms, but current metrics achieve only limited success, largely due to the lack of large-scale quality databases, which are essential for learning accurate and robust SR quality metrics. In this work, we first build a large-scale SR image database using a novel semi-automatic labeling approach, which allows us to label a large number of images with manageable human workload. The resulting SR Image quality database with Semi-Automatic Ratings (SISAR), so far the largest of SR-IQA database, contains 8,400 images of 100 natural scenes. We train an end-to-end Deep Image SR Quality (DISQ) model by employing two-stream Deep Neural Networks (DNNs) for feature extraction, followed by a feature fusion network for quality prediction. Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The SISAR database and DISQ model will be made publicly available to facilitate reproducible research.