 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Universal Image Degradation Model via Content-Degradation Disentanglement
May 19, 2025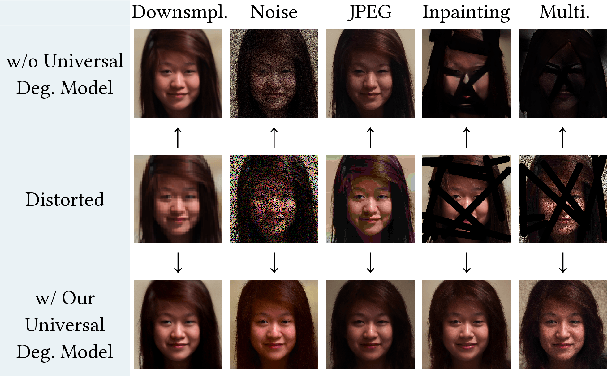
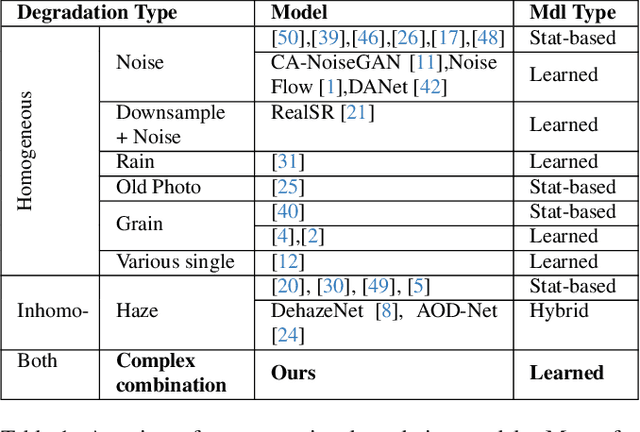

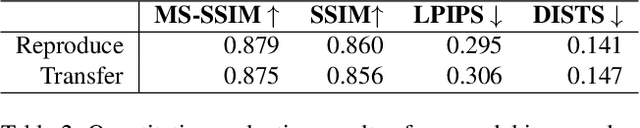
Image degradation synthesis is highly desirable in a wide variety of applications ranging from image restoration to simulating artistic effects. Existing models are designed to generate one specific or a narrow set of degradations, which often require user-provided degradation parameters. As a result, they lack the generalizability to synthesize degradations beyond their initial design or adapt to other applications. Here we propose the first universal degradation model that can synthesize a broad spectrum of complex and realistic degradations containing both homogeneous (global) and inhomogeneous (spatially varying) components. Our model automatically extracts and disentangles homogeneous and inhomogeneous degradation features, which are later used for degradation synthesis without user intervention. A disentangle-by-compression method is proposed to separate degradation information from images. Two novel modules for extracting and incorporating inhomogeneous degradations are created to model inhomogeneous components in complex degradations. We demonstrate the model's accuracy and adaptability in film-grain simulation and blind image restoration tasks. The demo video, code, and dataset of this project will be released upon publication at github.com/yangwenbo99/content-degradation-disentanglement.
Architectural Exploration of Hybrid Neural Decoders for Neuromorphic Implantable BMI
May 09, 2025This work presents an efficient decoding pipeline for neuromorphic implantable brain-machine interfaces (Neu-iBMI), leveraging sparse neural event data from an event-based neural sensing scheme. We introduce a tunable event filter (EvFilter), which also functions as a spike detector (EvFilter-SPD), significantly reducing the number of events processed for decoding by 192X and 554X, respectively. The proposed pipeline achieves high decoding performance, up to R^2=0.73, with ANN- and SNN-based decoders, eliminating the need for signal recovery, spike detection, or sorting, commonly performed in conventional iBMI systems. The SNN-Decoder reduces computations and memory required by 5-23X compared to NN-, and LSTM-Decoders, while the ST-NN-Decoder delivers similar performance to an LSTM-Decoder requiring 2.5X fewer resources. This streamlined approach significantly reduces computational and memory demands, making it ideal for low-power, on-implant, or wearable iBMIs.
Omnidirectional Image Quality Captioning: A Large-scale Database and A New Model
Feb 21, 2025



The fast growing application of omnidirectional images calls for effective approaches for omnidirectional image quality assessment (OIQA). Existing OIQA methods have been developed and tested on homogeneously distorted omnidirectional images, but it is hard to transfer their success directly to the heterogeneously distorted omnidirectional images. In this paper, we conduct the largest study so far on OIQA, where we establish a large-scale database called OIQ-10K containing 10,000 omnidirectional images with both homogeneous and heterogeneous distortions. A comprehensive psychophysical study is elaborated to collect human opinions for each omnidirectional image, together with the spatial distributions (within local regions or globally) of distortions, and the head and eye movements of the subjects. Furthermore, we propose a novel multitask-derived adaptive feature-tailoring OIQA model named IQCaption360, which is capable of generating a quality caption for an omnidirectional image in a manner of textual template. Extensive experiments demonstrate the effectiveness of IQCaption360, which outperforms state-of-the-art methods by a significant margin on the proposed OIQ-10K database. The OIQ-10K database and the related source codes are available at https://github.com/WenJuing/IQCaption360.
Structural Similarity in Deep Features: Image Quality Assessment Robust to Geometrically Disparate Reference
Dec 27, 2024Image Quality Assessment (IQA) with references plays an important role in optimizing and evaluating computer vision tasks. Traditional methods assume that all pixels of the reference and test images are fully aligned. Such Aligned-Reference IQA (AR-IQA) approaches fail to address many real-world problems with various geometric deformations between the two images. Although significant effort has been made to attack Geometrically-Disparate-Reference IQA (GDR-IQA) problem, it has been addressed in a task-dependent fashion, for example, by dedicated designs for image super-resolution and retargeting, or by assuming the geometric distortions to be small that can be countered by translation-robust filters or by explicit image registrations. Here we rethink this problem and propose a unified, non-training-based Deep Structural Similarity (DeepSSIM) approach to address the above problems in a single framework, which assesses structural similarity of deep features in a simple but efficient way and uses an attention calibration strategy to alleviate attention deviation. The proposed method, without application-specific design, achieves state-of-the-art performance on AR-IQA datasets and meanwhile shows strong robustness to various GDR-IQA test cases. Interestingly, our test also shows the effectiveness of DeepSSIM as an optimization tool for training image super-resolution, enhancement and restoration, implying an even wider generalizability. \footnote{Source code will be made public after the review is completed.
HybridMQA: Exploring Geometry-Texture Interactions for Colored Mesh Quality Assessment
Dec 02, 2024Mesh quality assessment (MQA) models play a critical role in the design, optimization, and evaluation of mesh operation systems in a wide variety of applications. Current MQA models, whether model-based methods using topology-aware features or projection-based approaches working on rendered 2D projections, often fail to capture the intricate interactions between texture and 3D geometry. We introduce HybridMQA, a first-of-its-kind hybrid full-reference colored MQA framework that integrates model-based and projection-based approaches, capturing complex interactions between textural information and 3D structures for enriched quality representations. Our method employs graph learning to extract detailed 3D representations, which are then projected to 2D using a novel feature rendering process that precisely aligns them with colored projections. This enables the exploration of geometry-texture interactions via cross-attention, producing comprehensive mesh quality representations. Extensive experiments demonstrate HybridMQA's superior performance across diverse datasets, highlighting its ability to effectively leverage geometry-texture interactions for a thorough understanding of mesh quality. Our implementation will be made publicly available.
Perceptual Quality Assessment of Trisoup-Lifting Encoded 3D Point Clouds
Oct 09, 2024
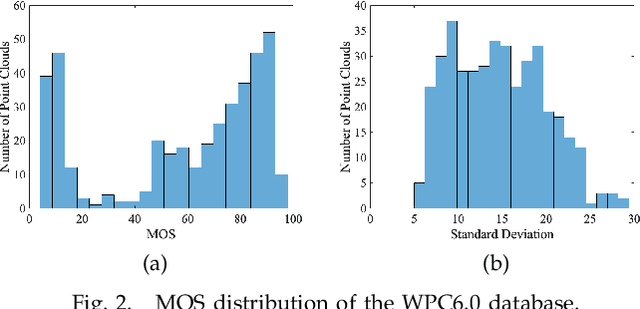
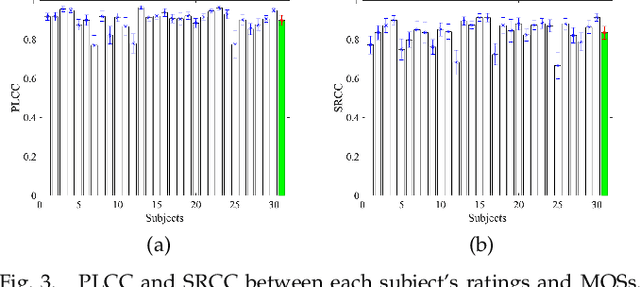
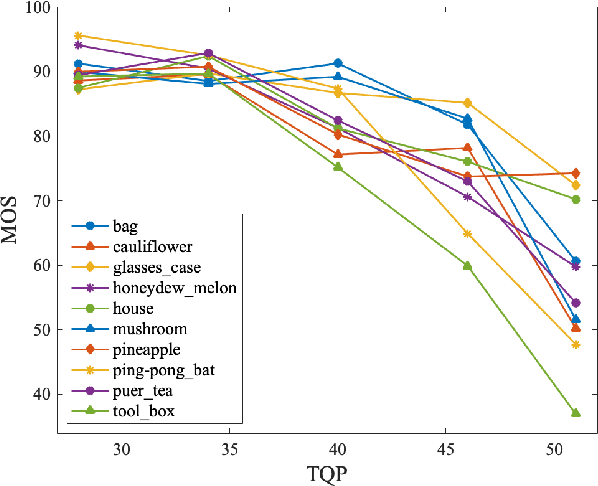
No-reference bitstream-layer point cloud quality assessment (PCQA) can be deployed without full decoding at any network node to achieve real-time quality monitoring. In this work, we develop the first PCQA model dedicated to Trisoup-Lifting encoded 3D point clouds by analyzing bitstreams without full decoding. Specifically, we investigate the relationship among texture bitrate per point (TBPP), texture complexity (TC) and texture quantization parameter (TQP) while geometry encoding is lossless. Subsequently, we estimate TC by utilizing TQP and TBPP. Then, we establish a texture distortion evaluation model based on TC, TBPP and TQP. Ultimately, by integrating this texture distortion model with a geometry attenuation factor, a function of trisoupNodeSizeLog2 (tNSL), we acquire a comprehensive NR bitstream-layer PCQA model named streamPCQ-TL. In addition, this work establishes a database named WPC6.0, the first and largest PCQA database dedicated to Trisoup-Lifting encoding mode, encompassing 400 distorted point clouds with both 4 geometric multiplied by 5 texture distortion levels. Experiment results on M-PCCD, ICIP2020 and the proposed WPC6.0 database suggest that the proposed streamPCQ-TL model exhibits robust and notable performance in contrast to existing advanced PCQA metrics, particularly in terms of computational cost. The dataset and source code will be publicly released at \href{https://github.com/qdushl/Waterloo-Point-Cloud-Database-6.0}{\textit{https://github.com/qdushl/Waterloo-Point-Cloud-Database-6.0}}
Perceptual Depth Quality Assessment of Stereoscopic Omnidirectional Images
Aug 19, 2024



Depth perception plays an essential role in the viewer experience for immersive virtual reality (VR) visual environments. However, previous research investigations in the depth quality of 3D/stereoscopic images are rather limited, and in particular, are largely lacking for 3D viewing of 360-degree omnidirectional content. In this work, we make one of the first attempts to develop an objective quality assessment model named depth quality index (DQI) for efficient no-reference (NR) depth quality assessment of stereoscopic omnidirectional images. Motivated by the perceptual characteristics of the human visual system (HVS), the proposed DQI is built upon multi-color-channel, adaptive viewport selection, and interocular discrepancy features. Experimental results demonstrate that the proposed method outperforms state-of-the-art image quality assessment (IQA) and depth quality assessment (DQA) approaches in predicting the perceptual depth quality when tested using both single-viewport and omnidirectional stereoscopic image databases. Furthermore, we demonstrate that combining the proposed depth quality model with existing IQA methods significantly boosts the performance in predicting the overall quality of 3D omnidirectional images.
Perceptual Crack Detection for Rendered 3D Textured Meshes
May 09, 2024


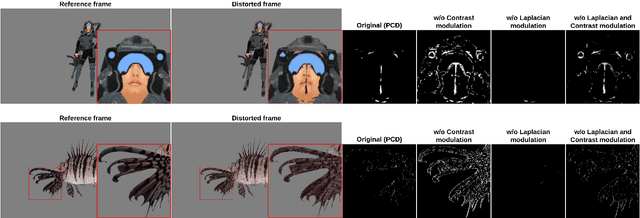
Recent years have witnessed many advancements in the applications of 3D textured meshes. As the demand continues to rise, evaluating the perceptual quality of this new type of media content becomes crucial for quality assurance and optimization purposes. Different from traditional image quality assessment, crack is an annoying artifact specific to rendered 3D meshes that severely affects their perceptual quality. In this work, we make one of the first attempts to propose a novel Perceptual Crack Detection (PCD) method for detecting and localizing crack artifacts in rendered meshes. Specifically, motivated by the characteristics of the human visual system (HVS), we adopt contrast and Laplacian measurement modules to characterize crack artifacts and differentiate them from other undesired artifacts. Extensive experiments on large-scale public datasets of 3D textured meshes demonstrate effectiveness and efficiency of the proposed PCD method in correct localization and detection of crack artifacts. %Specifically, We propose a full-reference crack artifact localization method that operates on a pair of input snapshots of distorted and reference 3D objects to generate a final crack map. Moreover, to quantify the performance of the proposed detection method and validate its effectiveness, we propose a simple yet effective weighting mechanism to incorporate the resulting crack map into classical quality assessment (QA) models, which creates significant performance improvement in predicting the perceptual image quality when tested on public datasets of static 3D textured meshes. A software release of the proposed method is publicly available at: https://github.com/arshafiee/crack-detection-VVM
Efficient Online Set-valued Classification with Bandit Feedback
May 07, 2024

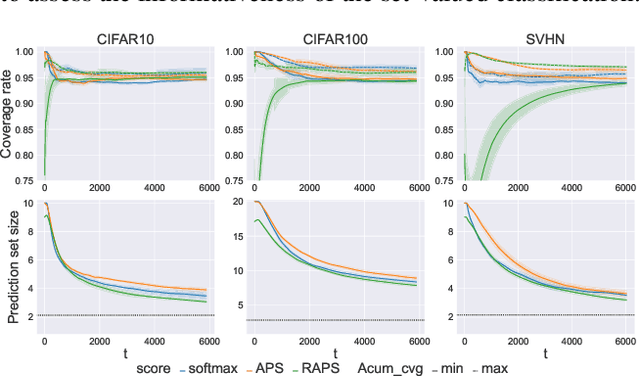
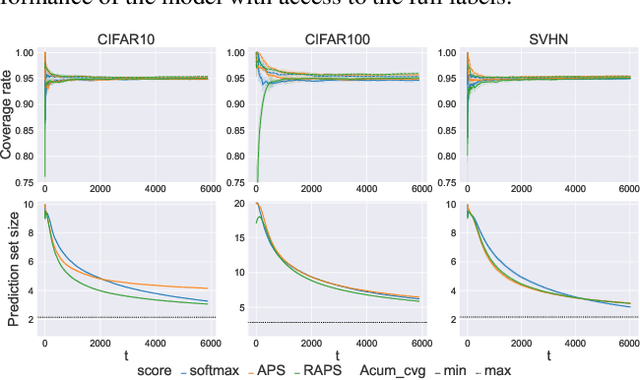
Conformal prediction is a distribution-free method that wraps a given machine learning model and returns a set of plausible labels that contain the true label with a prescribed coverage rate. In practice, the empirical coverage achieved highly relies on fully observed label information from data both in the training phase for model fitting and the calibration phase for quantile estimation. This dependency poses a challenge in the context of online learning with bandit feedback, where a learner only has access to the correctness of actions (i.e., pulled an arm) but not the full information of the true label. In particular, when the pulled arm is incorrect, the learner only knows that the pulled one is not the true class label, but does not know which label is true. Additionally, bandit feedback further results in a smaller labeled dataset for calibration, limited to instances with correct actions, thereby affecting the accuracy of quantile estimation. To address these limitations, we propose Bandit Class-specific Conformal Prediction (BCCP), offering coverage guarantees on a class-specific granularity. Using an unbiased estimation of an estimand involving the true label, BCCP trains the model and makes set-valued inferences through stochastic gradient descent. Our approach overcomes the challenges of sparsely labeled data in each iteration and generalizes the reliability and applicability of conformal prediction to online decision-making environments.
Generated Contents Enrichment
May 06, 2024In this paper, we investigate a novel artificial intelligence generation task, termed as generated contents enrichment (GCE). Different from conventional artificial intelligence contents generation task that enriches the given textual description implicitly with limited semantics for generating visually real content, our proposed GCE strives to perform content enrichment explicitly on both the visual and textual domain, from which the enriched contents are visually real, structurally reasonable, and semantically abundant. Towards to solve GCE, we propose a deep end-to-end method that explicitly explores the semantics and inter-semantic relationships during the enrichment. Specifically, we first model the input description as a semantic graph, wherein each node represents an object and each edge corresponds to the inter-object relationship. We then adopt Graph Convolutional Networks on top of the input scene description to predict the enriching objects and their relationships with the input objects. Finally, the enriched graph is fed into an image synthesis model to carry out the visual contents generation. Our experiments conducted on the Visual Genome dataset exhibit promising and visually plausible results.