 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fidelity: Semantic Similarity Assessment in Low-Level Image Processing
Apr 28, 2026Low-level image processing has long been evaluated mainly from the perspective of visual fidelity. However, with the rise of deep learning and generative models, processed images may preserve perceptual quality while altering semantic content, making conventional Image Quality Assessment (IQA) insufficient for semantic-level assessment. In this paper, we formalize \textit{Semantic Similarity} as a new evaluation task for low-level image processing, aimed at measuring whether semantic content is preserved after processing. We further present a structured formulation of image semantics based on semantic entities and their relations, and discuss the desired properties and constraints of a valid semantic similarity index. Based on this formulation, we propose Triplet-based Semantic Similarity Score (T3S), which models image semantics through foreground entities, background entities, and relations. T3S combines semantic entity extraction, foreground-background disentanglement, and open-world class/relation modeling. Experiments on COCO and SPA-Data show that T3S consistently outperforms existing fidelity-oriented metrics and representative semantic-level baselines, while better reflecting progressive semantic changes under diverse degradations. These results highlight the importance of semantic assessment in modern low-level vision.
MSDS: Deep Structural Similarity with Multiscale Representation
Apr 21, 2026Deep-feature-based perceptual similarity models have demonstrated strong alignment with human visual perception in Image Quality Assessment (IQA). However, most existing approaches operate at a single spatial scale, implicitly assuming that structural similarity at a fixed resolution is sufficient. The role of spatial scale in deep-feature similarity modeling thus remains insufficiently understood. In this letter, we isolate spatial scale as an independent factor using a minimal multiscale extension of DeepSSIM, referred to as Deep Structural Similarity with Multiscale Representation (MSDS). The proposed framework decouples deep feature representation from cross-scale integration by computing DeepSSIM independently across pyramid levels and fusing the resulting scores with a lightweight set of learnable global weights. Experiments on multiple benchmark datasets demonstrate consistent and statistically significant improvements over the single-scale baseline, while introducing negligible additional complexity. The results empirically confirm spatial scale as a non-negligible factor in deep perceptual similarity, isolated here via a minimal testbed.
Omne-R1: Learning to Reason with Memory for Multi-hop Question Answering
Aug 24, 2025This paper introduces Omne-R1, a novel approach designed to enhance multi-hop question answering capabilities on schema-free knowledge graphs by integrating advanced reasoning models. Our method employs a multi-stage training workflow, including two reinforcement learning phases and one supervised fine-tuning phase. We address the challenge of limited suitable knowledge graphs and QA data by constructing domain-independent knowledge graphs and auto-generating QA pairs. Experimental results show significant improvements in answering multi-hop questions, with notable performance gains on more complex 3+ hop questions. Our proposed training framework demonstrates strong generalization abilities across diverse knowledge domains.
Structural Similarity in Deep Features: Image Quality Assessment Robust to Geometrically Disparate Reference
Dec 27, 2024
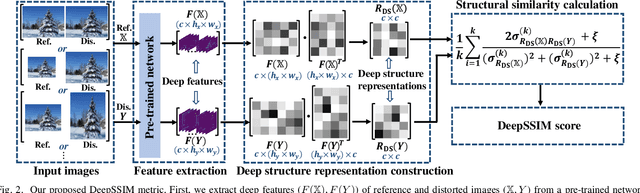


Image Quality Assessment (IQA) with references plays an important role in optimizing and evaluating computer vision tasks. Traditional methods assume that all pixels of the reference and test images are fully aligned. Such Aligned-Reference IQA (AR-IQA) approaches fail to address many real-world problems with various geometric deformations between the two images. Although significant effort has been made to attack Geometrically-Disparate-Reference IQA (GDR-IQA) problem, it has been addressed in a task-dependent fashion, for example, by dedicated designs for image super-resolution and retargeting, or by assuming the geometric distortions to be small that can be countered by translation-robust filters or by explicit image registrations. Here we rethink this problem and propose a unified, non-training-based Deep Structural Similarity (DeepSSIM) approach to address the above problems in a single framework, which assesses structural similarity of deep features in a simple but efficient way and uses an attention calibration strategy to alleviate attention deviation. The proposed method, without application-specific design, achieves state-of-the-art performance on AR-IQA datasets and meanwhile shows strong robustness to various GDR-IQA test cases. Interestingly, our test also shows the effectiveness of DeepSSIM as an optimization tool for training image super-resolution, enhancement and restoration, implying an even wider generalizability. \footnote{Source code will be made public after the review is completed.
Long Term Memory: The Foundation of AI Self-Evolution
Oct 21, 2024



Large language models (LLMs) like GPTs, trained on vast datasets, have demonstrated impressive capabilities in language understanding, reasoning, and planning, achieving human-level performance in various tasks. Most studies focus on enhancing these models by training on ever-larger datasets to build more powerful foundation models. While training stronger models is important, enabling models to evolve during inference is equally crucial, a process we refer to as AI self-evolution. Unlike large-scale training, self-evolution may rely on limited data or interactions. Inspired by the columnar organization of the human cerebral cortex, we hypothesize that AI models could develop cognitive abilities and build internal representations through iterative interactions with their environment. To achieve this, models need long-term memory (LTM) to store and manage processed interaction data. LTM supports self-evolution by representing diverse experiences across environments and agents. In this report, we explore AI self-evolution and its potential to enhance models during inference. We examine LTM's role in lifelong learning, allowing models to evolve based on accumulated interactions. We outline the structure of LTM and the systems needed for effective data retention and representation. We also classify approaches for building personalized models with LTM data and show how these models achieve self-evolution through interaction. Using LTM, our multi-agent framework OMNE achieved first place on the GAIA benchmark, demonstrating LTM's potential for AI self-evolution. Finally, we present a roadmap for future research, emphasizing the importance of LTM for advancing AI technology and its practical applications.
Dual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024



Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
Geometry-based spherical JND modeling for 360$^\circ$ display
Mar 07, 2023



360$^\circ$ videos have received widespread attention due to its realistic and immersive experiences for users. To date, how to accurately model the user perceptions on 360$^\circ$ display is still a challenging issue. In this paper, we exploit the visual characteristics of 360$^\circ$ projection and display and extend the popular just noticeable difference (JND) model to spherical JND (SJND). First, we propose a quantitative 2D-JND model by jointly considering spatial contrast sensitivity, luminance adaptation and texture masking effect. In particular, our model introduces an entropy-based region classification and utilizes different parameters for different types of regions for better modeling performance. Second, we extend our 2D-JND model to SJND by jointly exploiting latitude projection and field of view during 360$^\circ$ display. With this operation, SJND reflects both the characteristics of human vision system and the 360$^\circ$ display. Third, our SJND model is more consistent with user perceptions during subjective test and also shows more tolerance in distortions with fewer bit rates during 360$^\circ$ video compression. To further examine the effectiveness of our SJND model, we embed it in Versatile Video Coding (VVC) compression. Compared with the state-of-the-arts, our SJND-VVC framework significantly reduced the bit rate with negligible loss in visual quality.
A Correction-Based Dynamic Enhancement Framework towards Underwater Detection
Feb 06, 2023



To assist underwater object detection for better performance, image enhancement technology is often used as a pre-processing step. However, most of the existing enhancement methods tend to pursue the visual quality of an image, instead of providing effective help for detection tasks. In fact, image enhancement algorithms should be optimized with the goal of utility improvement. In this paper, to adapt to the underwater detection tasks, we proposed a lightweight dynamic enhancement algorithm using a contribution dictionary to guide low-level corrections. Dynamic solutions are designed to capture differences in detection preferences. In addition, it can also balance the inconsistency between the contribution of correction operations and their time complexity. Experimental results in real underwater object detection tasks show the superiority of our proposed method in both generalization and real-time performance.
Saliency-Aware Spatio-Temporal Artifact Detection for Compressed Video Quality Assessment
Jan 03, 2023


Compressed videos often exhibit visually annoying artifacts, known as Perceivable Encoding Artifacts (PEAs), which dramatically degrade video visual quality. Subjective and objective measures capable of identifying and quantifying various types of PEAs are critical in improving visual quality. In this paper, we investigate the influence of four spatial PEAs (i.e. blurring, blocking, bleeding, and ringing) and two temporal PEAs (i.e. flickering and floating) on video quality. For spatial artifacts, we propose a visual saliency model with a low computational cost and higher consistency with human visual perception. In terms of temporal artifacts, self-attention based TimeSFormer is improved to detect temporal artifacts. Based on the six types of PEAs, a quality metric called Saliency-Aware Spatio-Temporal Artifacts Measurement (SSTAM) is proposed. Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics. We believe that SSTAM will be beneficial for optimizing video coding techniques.
LMQFormer: A Laplace-Prior-Guided Mask Query Transformer for Lightweight Snow Removal
Oct 12, 2022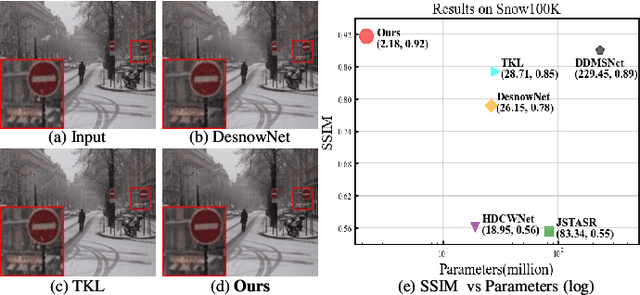



Snow removal aims to locate snow areas and recover clean images without repairing traces. Unlike the regularity and semitransparency of rain, snow with various patterns and degradations seriously occludes the background. As a result, the state-of-the-art snow removal methods usually retains a large parameter size. In this paper, we propose a lightweight but high-efficient snow removal network called Laplace Mask Query Transformer (LMQFormer). Firstly, we present a Laplace-VQVAE to generate a coarse mask as prior knowledge of snow. Instead of using the mask in dataset, we aim at reducing both the information entropy of snow and the computational cost of recovery. Secondly, we design a Mask Query Transformer (MQFormer) to remove snow with the coarse mask, where we use two parallel encoders and a hybrid decoder to learn extensive snow features under lightweight requirements. Thirdly, we develop a Duplicated Mask Query Attention (DMQA) that converts the coarse mask into a specific number of queries, which constraint the attention areas of MQFormer with reduced parameters. Experimental results in popular datasets have demonstrated the efficiency of our proposed model, which achieves the state-of-the-art snow removal quality with significantly reduced parameters and the lowest running time.