 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-based spherical JND modeling for 360$^\circ$ display
Mar 07, 2023



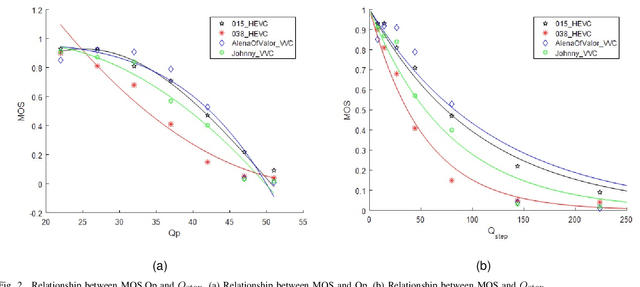
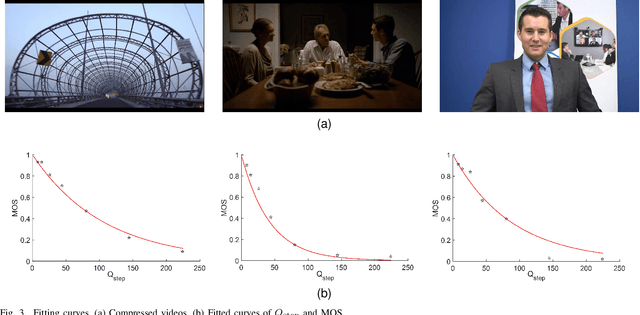
360$^\circ$ videos have received widespread attention due to its realistic and immersive experiences for users. To date, how to accurately model the user perceptions on 360$^\circ$ display is still a challenging issue. In this paper, we exploit the visual characteristics of 360$^\circ$ projection and display and extend the popular just noticeable difference (JND) model to spherical JND (SJND). First, we propose a quantitative 2D-JND model by jointly considering spatial contrast sensitivity, luminance adaptation and texture masking effect. In particular, our model introduces an entropy-based region classification and utilizes different parameters for different types of regions for better modeling performance. Second, we extend our 2D-JND model to SJND by jointly exploiting latitude projection and field of view during 360$^\circ$ display. With this operation, SJND reflects both the characteristics of human vision system and the 360$^\circ$ display. Third, our SJND model is more consistent with user perceptions during subjective test and also shows more tolerance in distortions with fewer bit rates during 360$^\circ$ video compression. To further examine the effectiveness of our SJND model, we embed it in Versatile Video Coding (VVC) compression. Compared with the state-of-the-arts, our SJND-VVC framework significantly reduced the bit rate with negligible loss in visual quality.
Saliency-Aware Spatio-Temporal Artifact Detection for Compressed Video Quality Assessment
Jan 03, 2023


Compressed videos often exhibit visually annoying artifacts, known as Perceivable Encoding Artifacts (PEAs), which dramatically degrade video visual quality. Subjective and objective measures capable of identifying and quantifying various types of PEAs are critical in improving visual quality. In this paper, we investigate the influence of four spatial PEAs (i.e. blurring, blocking, bleeding, and ringing) and two temporal PEAs (i.e. flickering and floating) on video quality. For spatial artifacts, we propose a visual saliency model with a low computational cost and higher consistency with human visual perception. In terms of temporal artifacts, self-attention based TimeSFormer is improved to detect temporal artifacts. Based on the six types of PEAs, a quality metric called Saliency-Aware Spatio-Temporal Artifacts Measurement (SSTAM) is proposed. Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics. We believe that SSTAM will be beneficial for optimizing video coding techniques.
Deep Quality Assessment of Compressed Videos: A Subjective and Objective Study
May 07, 2022
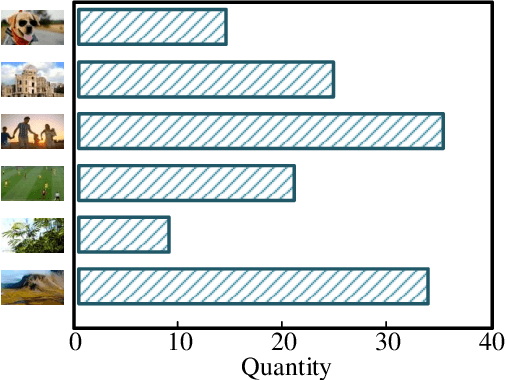
In the video coding process, the perceived quality of a compressed video is evaluated by full-reference quality evaluation metrics. However, it is difficult to obtain reference videos with perfect quality. To solve this problem, it is critical to design no-reference compressed video quality assessment algorithms, which assists in measuring the quality of experience on the server side and resource allocation on the network side. Convolutional Neural Network (CNN) has shown its advantage in Video Quality Assessment (VQA) with promising successes in recent years. A large-scale quality database is very important for learning accurate and powerful compressed video quality metrics. In this work, a semi-automatic labeling method is adopted to build a large-scale compressed video quality database, which allows us to label a large number of compressed videos with manageable human workload. The resulting Compressed Video quality database with Semi-Automatic Ratings (CVSAR), so far the largest of compressed video quality database. We train a no-reference compressed video quality assessment model with a 3D CNN for SpatioTemporal Feature Extraction and Evaluation (STFEE). Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The CVSAR database and STFEE model will be made publicly available to facilitate reproducible research.
PEA265: Perceptual Assessment of Video Compression Artifacts
Mar 01, 2019
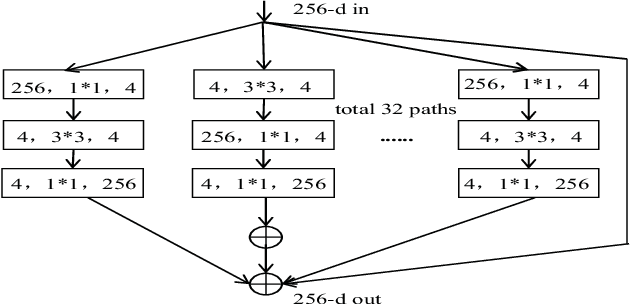
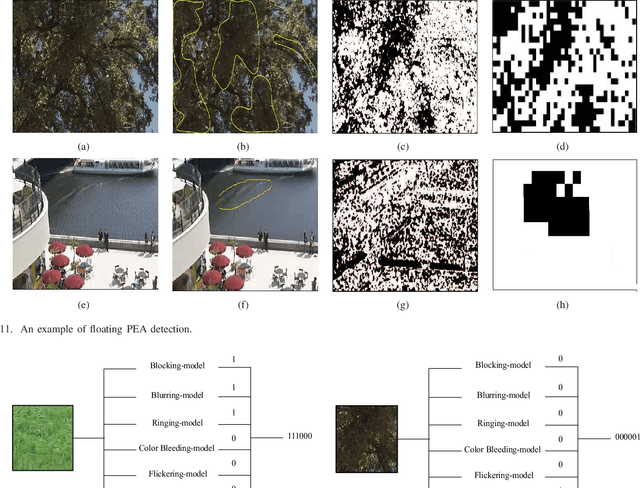
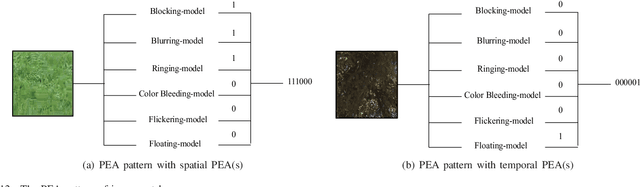
The most widely used video encoders share a common hybrid coding framework that includes block-based motion estimation/compensation and block-based transform coding. Despite their high coding efficiency, the encoded videos often exhibit visually annoying artifacts, denoted as Perceivable Encoding Artifacts (PEAs), which significantly degrade the visual Qualityof- Experience (QoE) of end users. To monitor and improve visual QoE, it is crucial to develop subjective and objective measures that can identify and quantify various types of PEAs. In this work, we make the first attempt to build a large-scale subjectlabelled database composed of H.265/HEVC compressed videos containing various PEAs. The database, namely the PEA265 database, includes 4 types of spatial PEAs (i.e. blurring, blocking, ringing and color bleeding) and 2 types of temporal PEAs (i.e. flickering and floating). Each containing at least 60,000 image or video patches with positive and negative labels. To objectively identify these PEAs, we train Convolutional Neural Networks (CNNs) using the PEA265 database. It appears that state-of-theart ResNeXt is capable of identifying each type of PEAs with high accuracy. Furthermore, we define PEA pattern and PEA intensity measures to quantify PEA levels of compressed video sequence. We believe that the PEA265 database and our findings will benefit the future development of video quality assessment methods and perceptually motivated video encoders.