 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEA265: Perceptual Assessment of Video Compression Artifacts
Paper and Code
Mar 01, 2019
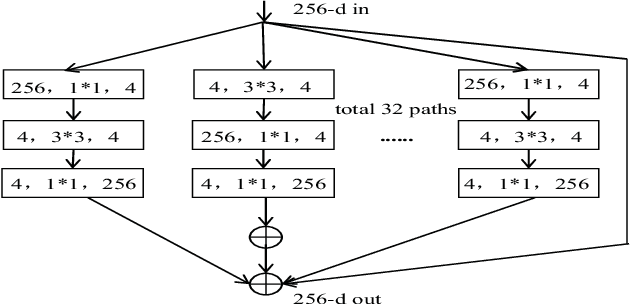
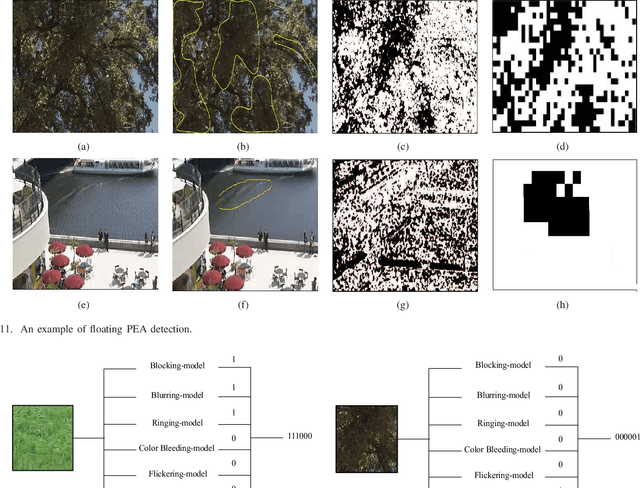
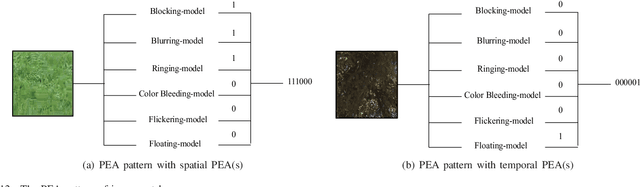
The most widely used video encoders share a common hybrid coding framework that includes block-based motion estimation/compensation and block-based transform coding. Despite their high coding efficiency, the encoded videos often exhibit visually annoying artifacts, denoted as Perceivable Encoding Artifacts (PEAs), which significantly degrade the visual Qualityof- Experience (QoE) of end users. To monitor and improve visual QoE, it is crucial to develop subjective and objective measures that can identify and quantify various types of PEAs. In this work, we make the first attempt to build a large-scale subjectlabelled database composed of H.265/HEVC compressed videos containing various PEAs. The database, namely the PEA265 database, includes 4 types of spatial PEAs (i.e. blurring, blocking, ringing and color bleeding) and 2 types of temporal PEAs (i.e. flickering and floating). Each containing at least 60,000 image or video patches with positive and negative labels. To objectively identify these PEAs, we train Convolutional Neural Networks (CNNs) using the PEA265 database. It appears that state-of-theart ResNeXt is capable of identifying each type of PEAs with high accuracy. Furthermore, we define PEA pattern and PEA intensity measures to quantify PEA levels of compressed video sequence. We believe that the PEA265 database and our findings will benefit the future development of video quality assessment methods and perceptually motivated video encoders.