 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Based Optimization for IRS Based UAV-NOMA Downlink Networks
Jun 17, 2021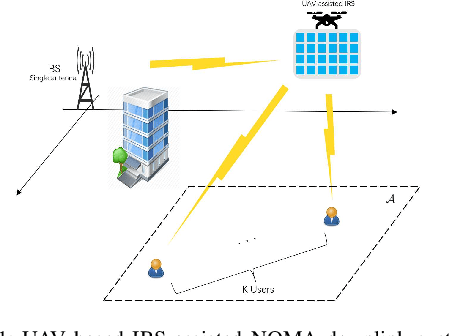
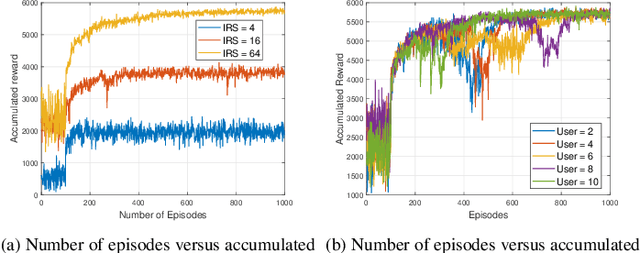
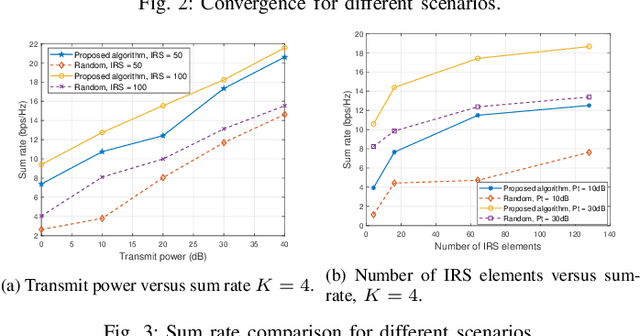
This paper investigates the application of deep deterministic policy gradient (DDPG) to intelligent reflecting surface (IRS) based unmanned aerial vehicles (UAV) assisted non-orthogonal multiple access (NOMA) downlink networks. The deployment of the UAV equipped with an IRS is important, as the UAV increases the flexibility of the IRS significantly, especially for the case of users who have no line of sight (LoS) path to the base station (BS). Therefore, the aim of this letter is to maximize the sum rate by jointly optimizing the power allocation of the BS, the phase shifting of the IRS and the horizontal position of the UAV. Because the formulated problem is not convex, the DDPG algorithm is utilized to solve it. The computer simulation results are provided to show the superior performance of the proposed DDPG based algorithm.
Channel Estimation for RIS-Empowered Multi-User MISO Wireless Communications
Aug 04, 2020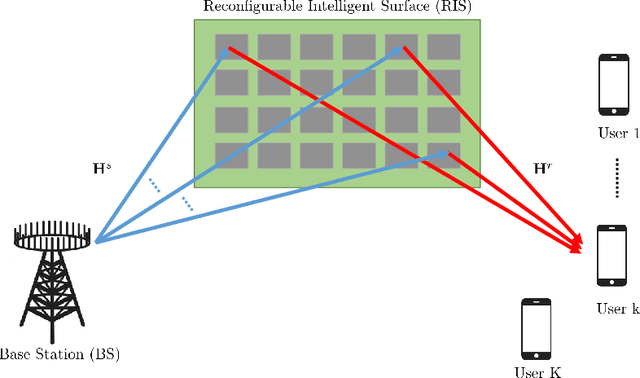
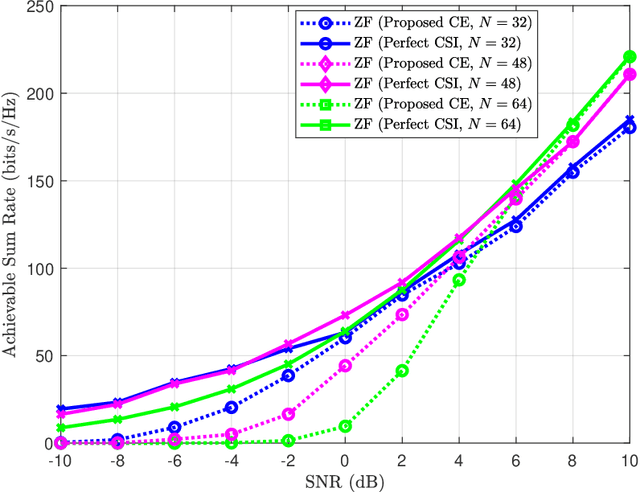
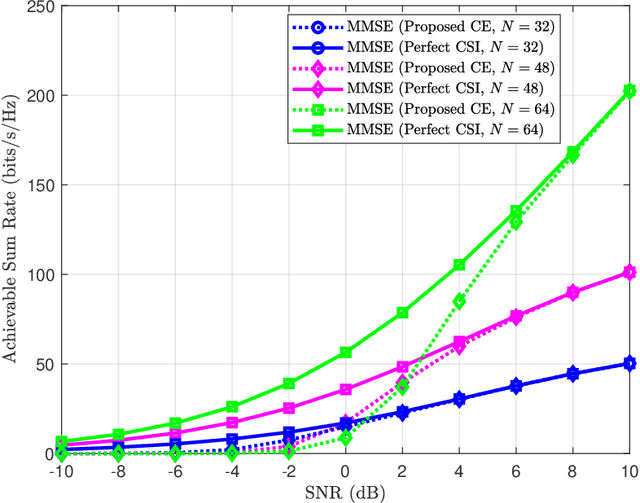
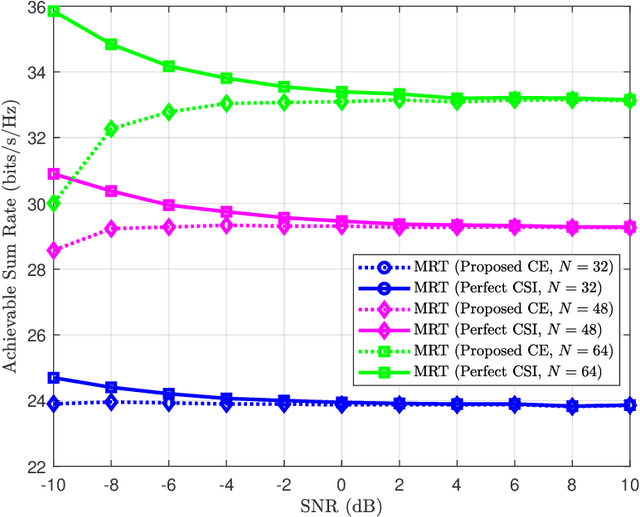
Reconfigurable Intelligent Surfaces (RISs) have been recently considered as an energy-efficient solution for future wireless networks due to their fast and low-power configuration, which has increased potential in enabling massive connectivity and low-latency communications. Accurate and low-overhead channel estimation in RIS-based systems is one of the most critical challenges due to the usually large number of RIS unit elements and their distinctive hardware constraints. In this paper, we focus on the downlink of a RIS-empowered multi-user Multiple Input Single Output (MISO) downlink communication systems and propose a channel estimation framework based on the PARAllel FACtor (PARAFAC) decomposition to unfold the resulting cascaded channel model. We present two iterative estimation algorithms for the channels between the base station and RIS, as well as the channels between RIS and users. One is based on alternating least squares (ALS), while the other uses vector approximate message passing to iteratively reconstruct two unknown channels from the estimated vectors. To theoretically assess the performance of the ALS-based algorithm, we derived its estimation Cram\'er-Rao Bound (CRB). We also discuss the achievable sum-rate computation with estimated channels and different precoding schemes for the base station. Our extensive simulation results show that our algorithms outperform benchmark schemes and that the ALS technique achieve the CRB. It is also demonstrated that the sum rate using the estimated channels reached that of perfect channel estimation under various settings, thus, verifying the effectiveness and robustness of the proposed estimation algorithms.
Learning Person Re-identification Models from Videos with Weak Supervision
Jul 21, 2020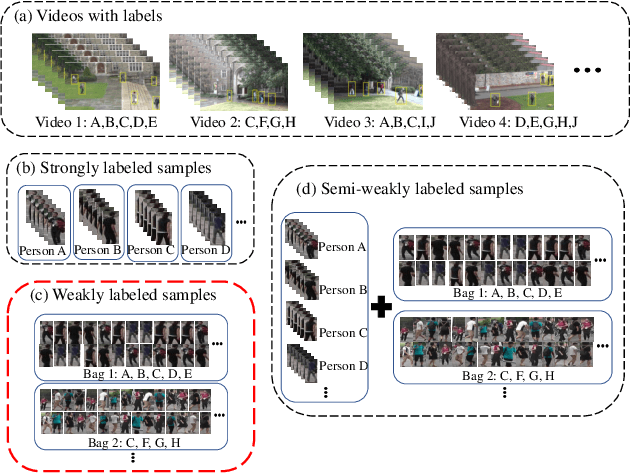
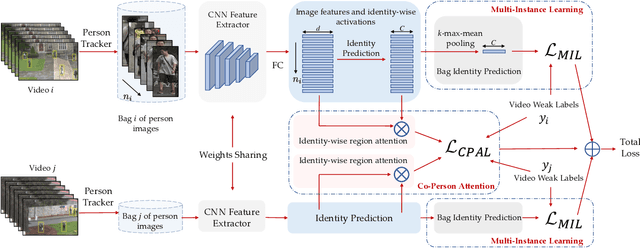
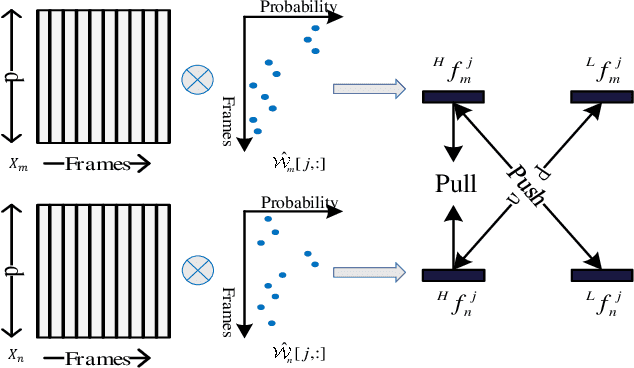
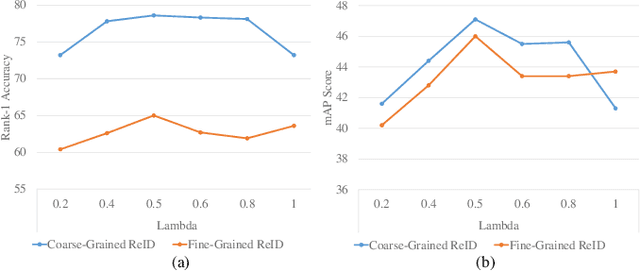
Most person re-identification methods, being supervised techniques, suffer from the burden of massive annotation requirement. Unsupervised methods overcome this need for labeled data, but perform poorly compared to the supervised alternatives. In order to cope with this issue, we introduce the problem of learning person re-identification models from videos with weak supervision. The weak nature of the supervision arises from the requirement of video-level labels, i.e. person identities who appear in the video, in contrast to the more precise framelevel annotations. Towards this goal, we propose a multiple instance attention learning framework for person re-identification using such video-level labels. Specifically, we first cast the video person re-identification task into a multiple instance learning setting, in which person images in a video are collected into a bag. The relations between videos with similar labels can be utilized to identify persons, on top of that, we introduce a co-person attention mechanism which mines the similarity correlations between videos with person identities in common. The attention weights are obtained based on all person images instead of person tracklets in a video, making our learned model less affected by noisy annotations. Extensive experiments demonstrate the superiority of the proposed method over the related methods on two weakly labeled person re-identification datasets.
GETNET: A General End-to-end Two-dimensional CNN Framework for Hyperspectral Image Change Detection
May 05, 2019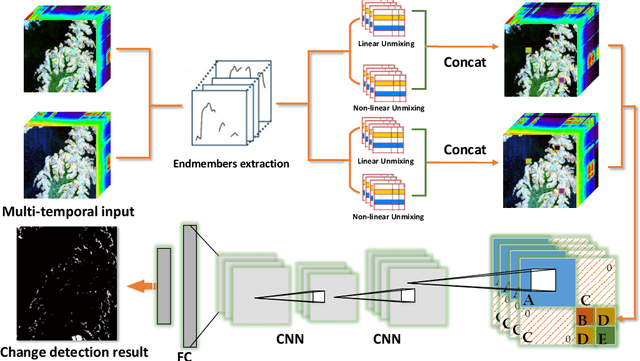

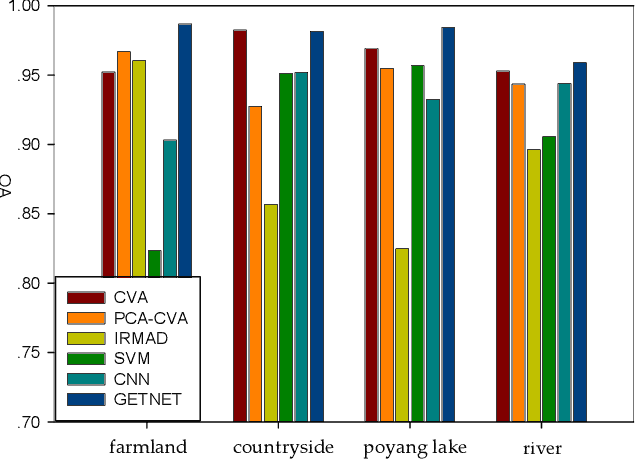
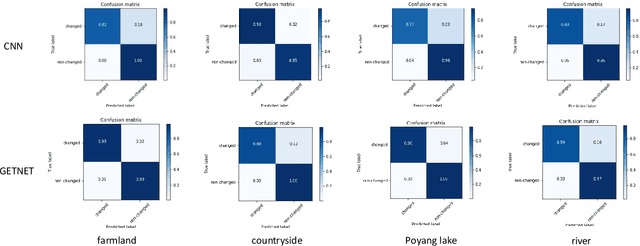
Change detection (CD) is an important application of remote sensing, which provides timely change information about large-scale Earth surface. With the emergence of hyperspectral imagery, CD technology has been greatly promoted, as hyperspectral data with the highspectral resolution are capable of detecting finer changes than using the traditional multispectral imagery. Nevertheless, the high dimension of hyperspectral data makes it difficult to implement traditional CD algorithms. Besides, endmember abundance information at subpixel level is often not fully utilized. In order to better handle high dimension problem and explore abundance information, this paper presents a General End-to-end Two-dimensional CNN (GETNET) framework for hyperspectral image change detection (HSI-CD). The main contributions of this work are threefold: 1) Mixed-affinity matrix that integrates subpixel representation is introduced to mine more cross-channel gradient features and fuse multi-source information; 2) 2-D CNN is designed to learn the discriminative features effectively from multi-source data at a higher level and enhance the generalization ability of the proposed CD algorithm; 3) A new HSI-CD data set is designed for the objective comparison of different methods. Experimental results on real hyperspectral data sets demonstrate the proposed method outperforms most of the state-of-the-arts.
PEA265: Perceptual Assessment of Video Compression Artifacts
Mar 01, 2019
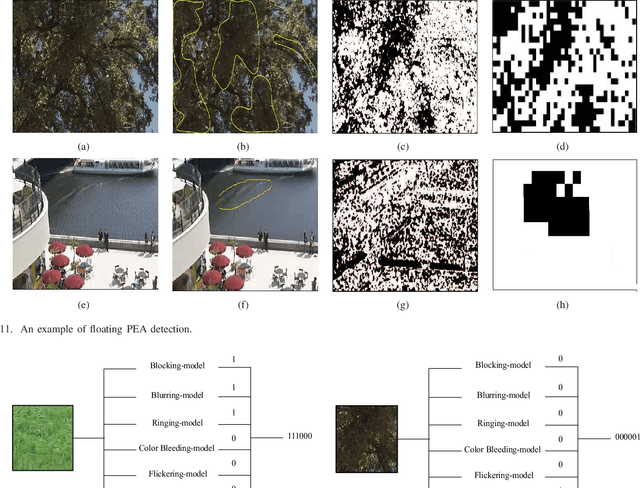
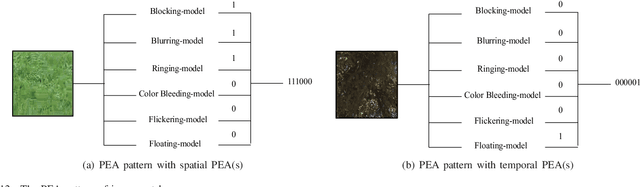
The most widely used video encoders share a common hybrid coding framework that includes block-based motion estimation/compensation and block-based transform coding. Despite their high coding efficiency, the encoded videos often exhibit visually annoying artifacts, denoted as Perceivable Encoding Artifacts (PEAs), which significantly degrade the visual Qualityof- Experience (QoE) of end users. To monitor and improve visual QoE, it is crucial to develop subjective and objective measures that can identify and quantify various types of PEAs. In this work, we make the first attempt to build a large-scale subjectlabelled database composed of H.265/HEVC compressed videos containing various PEAs. The database, namely the PEA265 database, includes 4 types of spatial PEAs (i.e. blurring, blocking, ringing and color bleeding) and 2 types of temporal PEAs (i.e. flickering and floating). Each containing at least 60,000 image or video patches with positive and negative labels. To objectively identify these PEAs, we train Convolutional Neural Networks (CNNs) using the PEA265 database. It appears that state-of-theart ResNeXt is capable of identifying each type of PEAs with high accuracy. Furthermore, we define PEA pattern and PEA intensity measures to quantify PEA levels of compressed video sequence. We believe that the PEA265 database and our findings will benefit the future development of video quality assessment methods and perceptually motivated video encoders.
Efficient Fully Convolution Neural Network for Generating Pixel Wise Robotic Grasps With High Resolution Images
Feb 24, 2019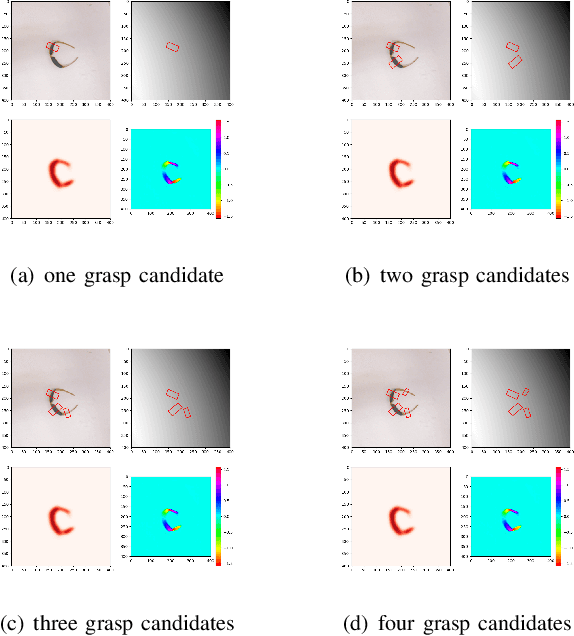

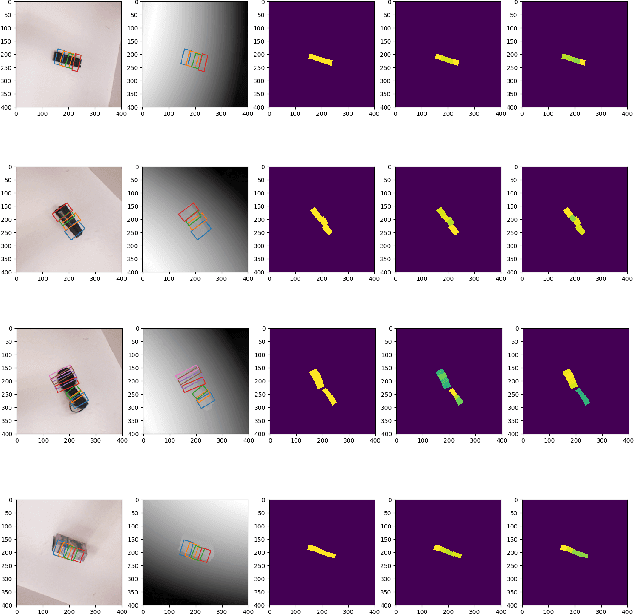
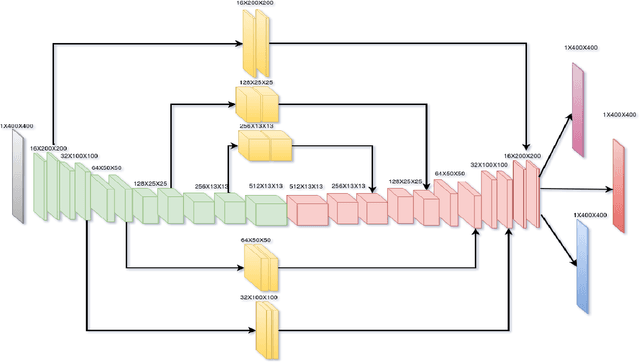
This paper presents an efficient neural network model to generate robotic grasps with high resolution images. The proposed model uses fully convolution neural network to generate robotic grasps for each pixel using 400 $\times$ 400 high resolution RGB-D images. It first down-sample the images to get features and then up-sample those features to the original size of the input as well as combines local and global features from different feature maps. Compared to other regression or classification methods for detecting robotic grasps, our method looks more like the segmentation methods which solves the problem through pixel-wise ways. We use Cornell Grasp Dataset to train and evaluate the model and get high accuracy about 94.42% for image-wise and 91.02% for object-wise and fast prediction time about 8ms. We also demonstrate that without training on the multiple objects dataset, our model can directly output robotic grasps candidates for different objects because of the pixel wise implementation.
Design and Control of a Quasi-Direct Drive Soft Hybrid Knee Exoskeleton for Injury Prevention during Squatting
Feb 19, 2019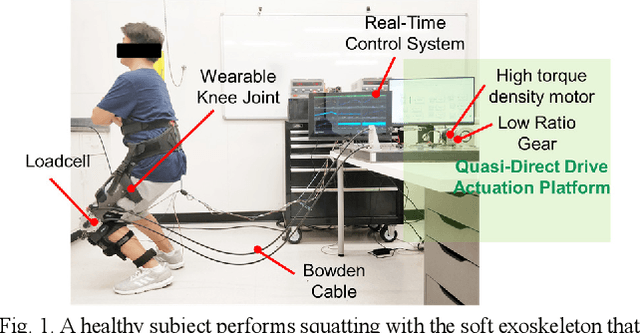
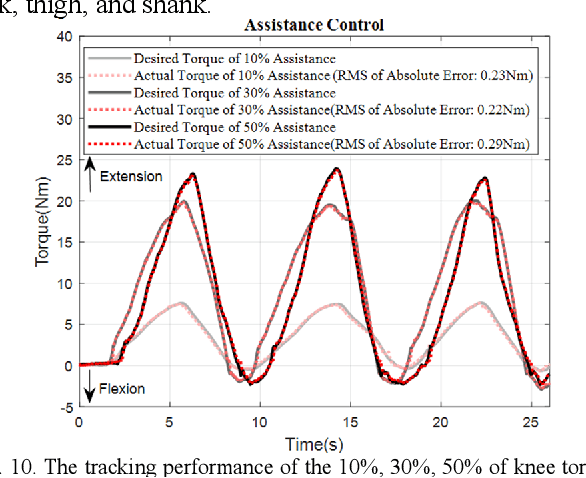
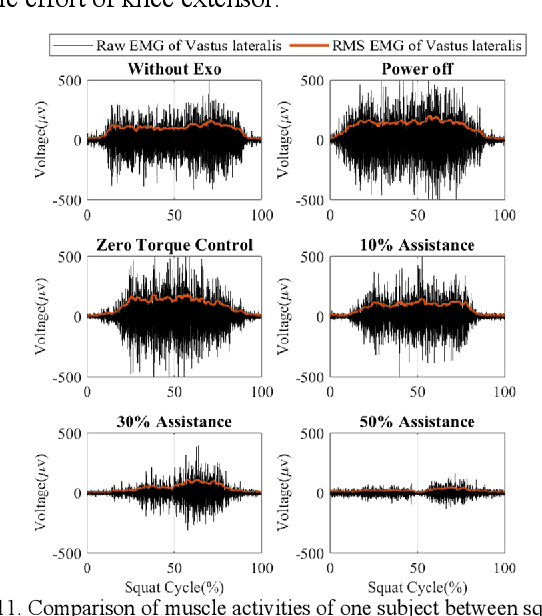
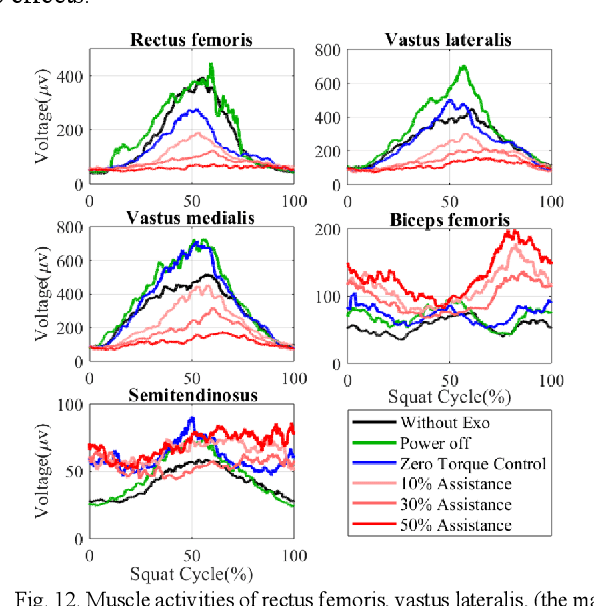
This paper presents a new design approach of wearable robots that tackle the three barriers to mainstay practical use of exoskeletons, namely discomfort, weight of the device, and symbiotic control of the exoskeleton-human co-robot system. The hybrid exoskeleton approach, demonstrated in a soft knee industrial exoskeleton case, mitigates the discomfort of wearers as it aims to avoid the drawbacks of rigid exoskeletons and textile-based soft exosuits. Quasi-direct drive actuation using high-torque density motors minimizes the weight of the device and presents high backdrivability that does not restrict natural movement. We derive a biomechanics model that is generic to both squat and stoop lifting motion. The control algorithm symbiotically detects posture using compact inertial measurement unit (IMU) sensors to generate an assistive profile that is proportional to the biological torque generated from our model. Experimental results demonstrate that the robot exhibits 1.5 Nm torque when it is unpowered and 0.5 Nm torque with zero-torque tracking control. The efficacy of injury prevention is demonstrated with one healthy subject. Root mean square (RMS) error of torque tracking is less than 0.29 Nm (1.21% of 24 Nm peak torque) for 50% assistance of biological torque. Comparing to the squat without exoskeleton, the maximum amplitude of the knee extensor muscle activity (rectus femoris) measured by Electromyography (EMG) sensors is reduced by 30% with 50% assistance of biological torque.
Location-Centered House Price Prediction: A Multi-Task Learning Approach
Jan 07, 2019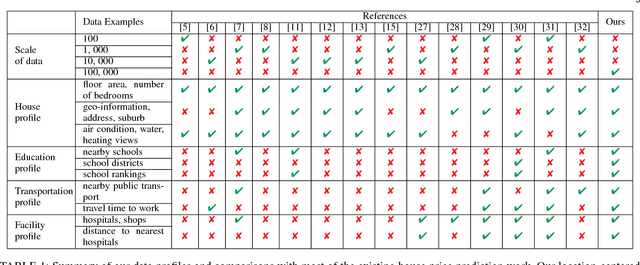
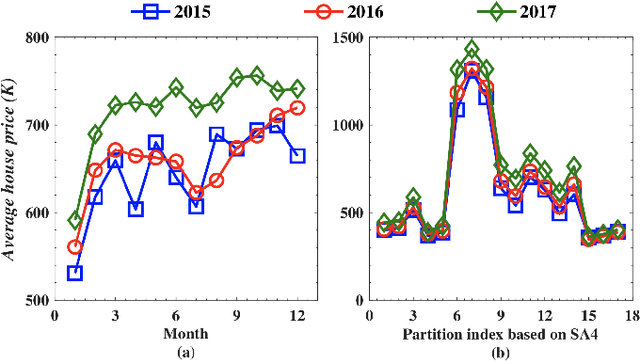
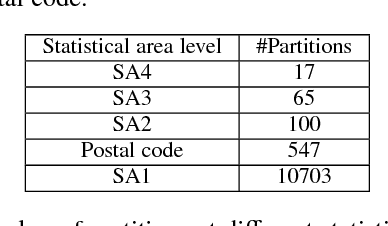

Accurate house prediction is of great significance to various real estate stakeholders such as house owners, buyers, investors, and agents. We propose a location-centered prediction framework that differs from existing work in terms of data profiling and prediction model. Regarding data profiling, we define and capture a fine-grained location profile powered by a diverse range of location data sources, such as transportation profile (e.g., distance to nearest train station), education profile (e.g., school zones and ranking), suburb profile based on census data, facility profile (e.g., nearby hospitals, supermarkets). Regarding the choice of prediction model, we observe that a variety of approaches either consider the entire house data for modeling, or split the entire data and model each partition independently. However, such modeling ignores the relatedness between partitions, and for all prediction scenarios, there may not be sufficient training samples per partition for the latter approach. We address this problem by conducting a careful study of exploiting the Multi-Task Learning (MTL) model. Specifically, we map the strategies for splitting the entire house data to the ways the tasks are defined in MTL, and each partition obtained is aligned with a task. Furthermore, we select specific MTL-based methods with different regularization terms to capture and exploit the relatedness between tasks. Based on real-world house transaction data collected in Melbourne, Australia. We design extensive experimental evaluations, and the results indicate a significant superiority of MTL-based methods over state-of-the-art approaches. Meanwhile, we conduct an in-depth analysis on the impact of task definitions and method selections in MTL on the prediction performance, and demonstrate that the impact of task definitions on prediction performance far exceeds that of method selections.