 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownstream Task Inspired Underwater Image Enhancement: A Perception-Aware Study from Dataset Construction to Network Design
Mar 02, 2026In real underwater environments, downstream image recognition tasks such as semantic segmentation and object detection often face challenges posed by problems like blurring and color inconsistencies. Underwater image enhancement (UIE) has emerged as a promising preprocessing approach, aiming to improve the recognizability of targets in underwater images. However, most existing UIE methods mainly focus on enhancing images for human visual perception, frequently failing to reconstruct high-frequency details that are critical for task-specific recognition. To address this issue, we propose a Downstream Task-Inspired Underwater Image Enhancement (DTI-UIE) framework, which leverages human visual perception model to enhance images effectively for underwater vision tasks. Specifically, we design an efficient two-branch network with task-aware attention module for feature mixing. The network benefits from a multi-stage training framework and a task-driven perceptual loss. Additionally, inspired by human perception, we automatically construct a Task-Inspired UIE Dataset (TI-UIED) using various task-specific networks. Experimental results demonstrate that DTI-UIE significantly improves task performance by generating preprocessed images that are beneficial for downstream tasks such as semantic segmentation, object detection, and instance segmentation. The codes are publicly available at https://github.com/oucailab/DTIUIE.
Frequency-Enhanced Hilbert Scanning Mamba for Short-Term Arctic Sea Ice Concentration Prediction
Feb 13, 2026While Mamba models offer efficient sequence modeling, vanilla versions struggle with temporal correlations and boundary details in Arctic sea ice concentration (SIC) prediction. To address these limitations, we propose Frequency-enhanced Hilbert scanning Mamba Framework (FH-Mamba) for short-term Arctic SIC prediction. Specifically, we introduce a 3D Hilbert scan mechanism that traverses the 3D spatiotemporal grid along a locality-preserving path, ensuring that adjacent indices in the flattened sequence correspond to neighboring voxels in both spatial and temporal dimensions. Additionally, we incorporate wavelet transform to amplify high-frequency details and we also design a Hybrid Shuffle Attention module to adaptively aggregate sequence and frequency features. Experiments conducted on the OSI-450a1 and AMSR2 datasets demonstrate that our FH-Mamba achieves superior prediction performance compared with state-of-the-art baselines. The results confirm the effectiveness of Hilbert scanning and frequency-aware attention in improving both temporal consistency and edge reconstruction for Arctic SIC forecasting. Our codes are publicly available at https://github.com/oucailab/FH-Mamba.
Enhancing Underwater Images via Adaptive Semantic-aware Codebook Learning
Feb 11, 2026Underwater Image Enhancement (UIE) is an ill-posed problem where natural clean references are not available, and the degradation levels vary significantly across semantic regions. Existing UIE methods treat images with a single global model and ignore the inconsistent degradation of different scene components. This oversight leads to significant color distortions and loss of fine details in heterogeneous underwater scenes, especially where degradation varies significantly across different image regions. Therefore, we propose SUCode (Semantic-aware Underwater Codebook Network), which achieves adaptive UIE from semantic-aware discrete codebook representation. Compared with one-shot codebook-based methods, SUCode exploits semantic-aware, pixel-level codebook representation tailored to heterogeneous underwater degradation. A three-stage training paradigm is employed to represent raw underwater image features to avoid pseudo ground-truth contamination. Gated Channel Attention Module (GCAM) and Frequency-Aware Feature Fusion (FAFF) jointly integrate channel and frequency cues for faithful color restoration and texture recovery. Extensive experiments on multiple benchmarks demonstrate that SUCode achieves state-of-the-art performance, outperforming recent UIE methods on both reference and no-reference metrics. The code will be made public available at https://github.com/oucailab/SUCode.
Aerial Multi-View Stereo via Adaptive Depth Range Inference and Normal Cues
Jun 06, 2025Three-dimensional digital urban reconstruction from multi-view aerial images is a critical application where deep multi-view stereo (MVS) methods outperform traditional techniques. However, existing methods commonly overlook the key differences between aerial and close-range settings, such as varying depth ranges along epipolar lines and insensitive feature-matching associated with low-detailed aerial images. To address these issues, we propose an Adaptive Depth Range MVS (ADR-MVS), which integrates monocular geometric cues to improve multi-view depth estimation accuracy. The key component of ADR-MVS is the depth range predictor, which generates adaptive range maps from depth and normal estimates using cross-attention discrepancy learning. In the first stage, the range map derived from monocular cues breaks through predefined depth boundaries, improving feature-matching discriminability and mitigating convergence to local optima. In later stages, the inferred range maps are progressively narrowed, ultimately aligning with the cascaded MVS framework for precise depth regression. Moreover, a normal-guided cost aggregation operation is specially devised for aerial stereo images to improve geometric awareness within the cost volume. Finally, we introduce a normal-guided depth refinement module that surpasses existing RGB-guided techniques. Experimental results demonstrate that ADR-MVS achieves state-of-the-art performance on the WHU, LuoJia-MVS, and M\"unchen datasets, while exhibits superior computational complexity.
Prototype-Based Information Compensation Network for Multi-Source Remote Sensing Data Classification
May 06, 2025Multi-source remote sensing data joint classification aims to provide accuracy and reliability of land cover classification by leveraging the complementary information from multiple data sources. Existing methods confront two challenges: inter-frequency multi-source feature coupling and inconsistency of complementary information exploration. To solve these issues, we present a Prototype-based Information Compensation Network (PICNet) for land cover classification based on HSI and SAR/LiDAR data. Specifically, we first design a frequency interaction module to enhance the inter-frequency coupling in multi-source feature extraction. The multi-source features are first decoupled into high- and low-frequency components. Then, these features are recoupled to achieve efficient inter-frequency communication. Afterward, we design a prototype-based information compensation module to model the global multi-source complementary information. Two sets of learnable modality prototypes are introduced to represent the global modality information of multi-source data. Subsequently, cross-modal feature integration and alignment are achieved through cross-attention computation between the modality-specific prototype vectors and the raw feature representations. Extensive experiments on three public datasets demonstrate the significant superiority of our PICNet over state-of-the-art methods. The codes are available at https://github.com/oucailab/PICNet.
Frequency-Compensated Network for Daily Arctic Sea Ice Concentration Prediction
Apr 23, 2025Accurately forecasting sea ice concentration (SIC) in the Arctic is critical to global ecosystem health and navigation safety. However, current methods still is confronted with two challenges: 1) these methods rarely explore the long-term feature dependencies in the frequency domain. 2) they can hardly preserve the high-frequency details, and the changes in the marginal area of the sea ice cannot be accurately captured. To this end, we present a Frequency-Compensated Network (FCNet) for Arctic SIC prediction on a daily basis. In particular, we design a dual-branch network, including branches for frequency feature extraction and convolutional feature extraction. For frequency feature extraction, we design an adaptive frequency filter block, which integrates trainable layers with Fourier-based filters. By adding frequency features, the FCNet can achieve refined prediction of edges and details. For convolutional feature extraction, we propose a high-frequency enhancement block to separate high and low-frequency information. Moreover, high-frequency features are enhanced via channel-wise attention, and temporal attention unit is employed for low-frequency feature extraction to capture long-range sea ice changes. Extensive experiments are conducted on a satellite-derived daily SIC dataset, and the results verify the effectiveness of the proposed FCNet. Our codes and data will be made public available at: https://github.com/oucailab/FCNet .
Dynamic Cross-Modal Feature Interaction Network for Hyperspectral and LiDAR Data Classification
Mar 10, 2025Hyperspectral image (HSI) and LiDAR data joint classification is a challenging task. Existing multi-source remote sensing data classification methods often rely on human-designed frameworks for feature extraction, which heavily depend on expert knowledge. To address these limitations, we propose a novel Dynamic Cross-Modal Feature Interaction Network (DCMNet), the first framework leveraging a dynamic routing mechanism for HSI and LiDAR classification. Specifically, our approach introduces three feature interaction blocks: Bilinear Spatial Attention Block (BSAB), Bilinear Channel Attention Block (BCAB), and Integration Convolutional Block (ICB). These blocks are designed to effectively enhance spatial, spectral, and discriminative feature interactions. A multi-layer routing space with routing gates is designed to determine optimal computational paths, enabling data-dependent feature fusion. Additionally, bilinear attention mechanisms are employed to enhance feature interactions in spatial and channel representations. Extensive experiments on three public HSI and LiDAR datasets demonstrate the superiority of DCMNet over state-of-the-art methods. Our code will be available at https://github.com/oucailab/DCMNet.
Global and Local Attention-Based Transformer for Hyperspectral Image Change Detection
Nov 21, 2024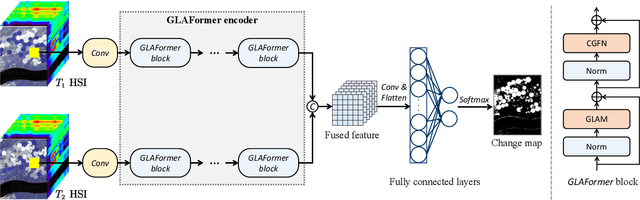
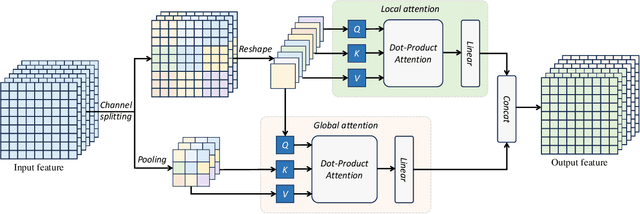
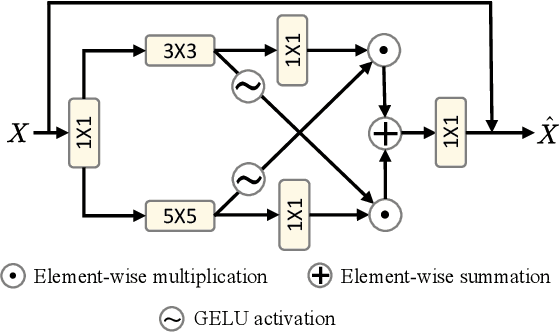
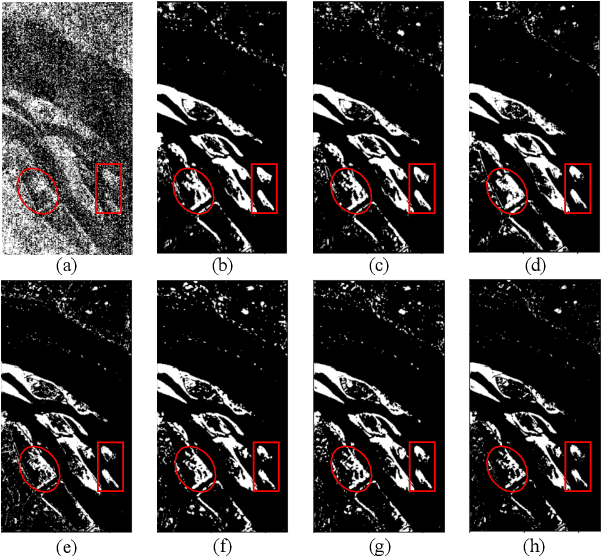
Recently Transformer-based hyperspectral image (HSI) change detection methods have shown remarkable performance. Nevertheless, existing attention mechanisms in Transformers have limitations in local feature representation. To address this issue, we propose Global and Local Attention-based Transformer (GLAFormer), which incorporates a global and local attention module (GLAM) to combine high-frequency and low-frequency signals. Furthermore, we introduce a cross-gating mechanism, called cross-gated feed-forward network (CGFN), to emphasize salient features and suppress noise interference. Specifically, the GLAM splits attention heads into global and local attention components to capture comprehensive spatial-spectral features. The global attention component employs global attention on downsampled feature maps to capture low-frequency information, while the local attention component focuses on high-frequency details using non-overlapping window-based local attention. The CGFN enhances the feature representation via convolutions and cross-gating mechanism in parallel paths. The proposed GLAFormer is evaluated on three HSI datasets. The results demonstrate its superiority over state-of-the-art HSI change detection methods. The source code of GLAFormer is available at \url{https://github.com/summitgao/GLAFormer}.
A Generalized Tensor Formulation for Hyperspectral Image Super-Resolution Under General Spatial Blurring
Sep 27, 2024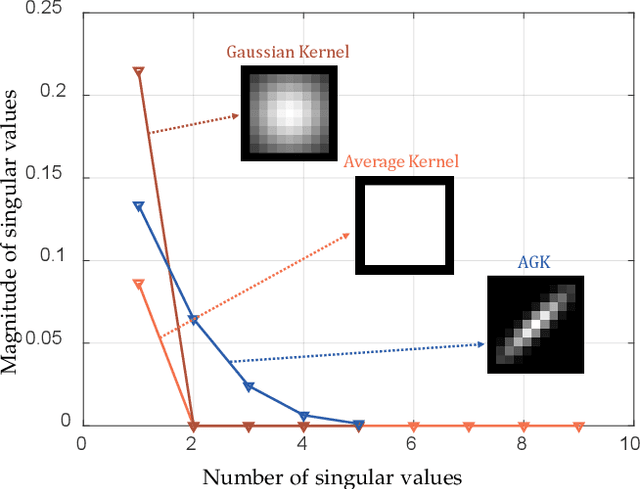
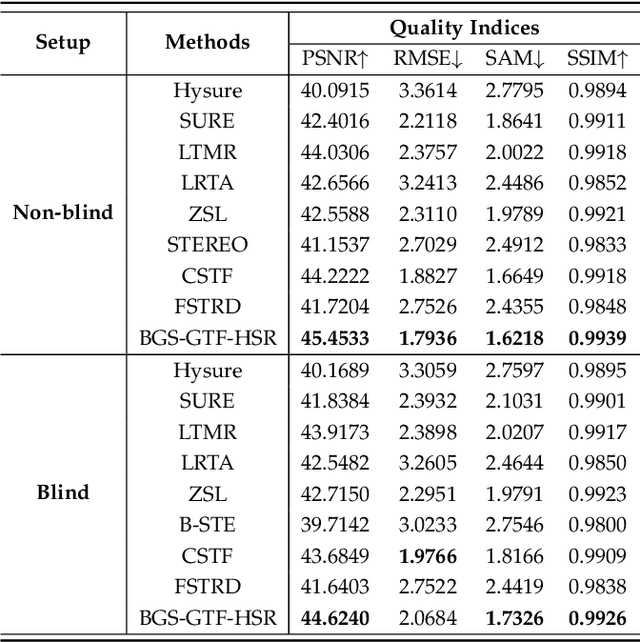
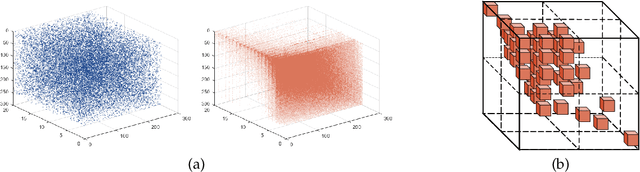
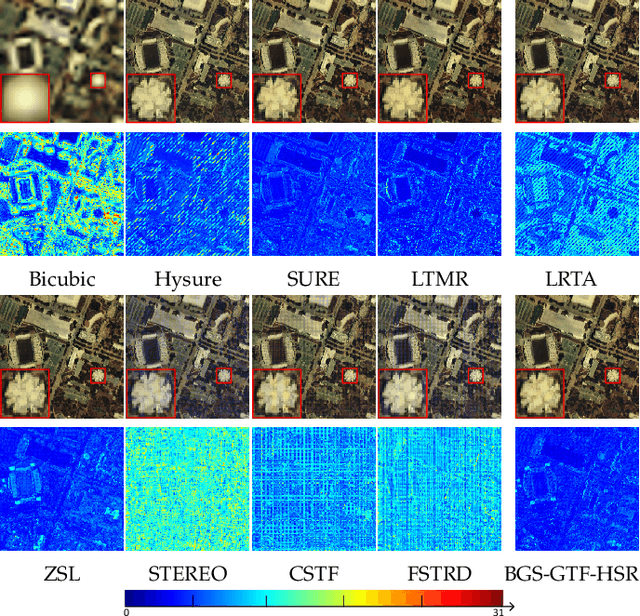
Hyperspectral super-resolution is commonly accomplished by the fusing of a hyperspectral imaging of low spatial resolution with a multispectral image of high spatial resolution, and many tensor-based approaches to this task have been recently proposed. Yet, it is assumed in such tensor-based methods that the spatial-blurring operation that creates the observed hyperspectral image from the desired super-resolved image is separable into independent horizontal and vertical blurring. Recent work has argued that such separable spatial degradation is ill-equipped to model the operation of real sensors which may exhibit, for example, anisotropic blurring. To accommodate this fact, a generalized tensor formulation based on a Kronecker decomposition is proposed to handle any general spatial-degradation matrix, including those that are not separable as previously assumed. Analysis of the generalized formulation reveals conditions under which exact recovery of the desired super-resolved image is guaranteed, and a practical algorithm for such recovery, driven by a blockwise-group-sparsity regularization, is proposed. Extensive experimental results demonstrate that the proposed generalized tensor approach outperforms not only traditional matrix-based techniques but also state-of-the-art tensor-based methods; the gains with respect to the latter are especially significant in cases of anisotropic spatial blurring.
MSFMamba: Multi-Scale Feature Fusion State Space Model for Multi-Source Remote Sensing Image Classification
Aug 26, 2024In multi-source remote sensing image classification field, remarkable progress has been made by convolutional neural network and Transformer. However, existing methods are still limited due to the inherent local reductive bias. Recently, Mamba-based methods built upon the State Space Model have shown great potential for long-range dependency modeling with linear complexity, but it has rarely been explored for the multi-source remote sensing image classification task. To this end, we propose Multi-Scale Feature Fusion Mamba (MSFMamba) network for hyperspectral image (HSI) and LiDAR/SAR data joint classification. Specifically, MSFMamba mainly comprises three parts: Multi-Scale Spatial Mamba (MSpa-Mamba) block, Spectral Mamba (Spe-Mamba) block, and Fusion Mamba (Fus-Mamba) block. Specifically, to solve the feature redundancy in multiple canning routes, the MSpa-Mamba block incorporates the multi-scale strategy to minimize the computational redundancy and alleviate the feature redundancy of SSM. In addition, Spe-Mamba is designed for spectral feature exploration, which is essential for HSI feature modeling. Moreover, to alleviate the heterogeneous gap between HSI and LiDAR/SAR data, we design Fus-Mamba block for multi-source feature fusion. The original Mamba is extended to accommodate dual inputs, and cross-modal feature interaction is enhanced. Extensive experimental results on three multi-source remote sensing datasets demonstrate the superiority performance of the proposed MSFMamba over the state-of-the-art models. Source codes of MSFMamba will be made public available at https://github.com/summitgao/MSFMamba .